Deep Reinforcement Learning
Deep Q-Learning
Value-based deep RL
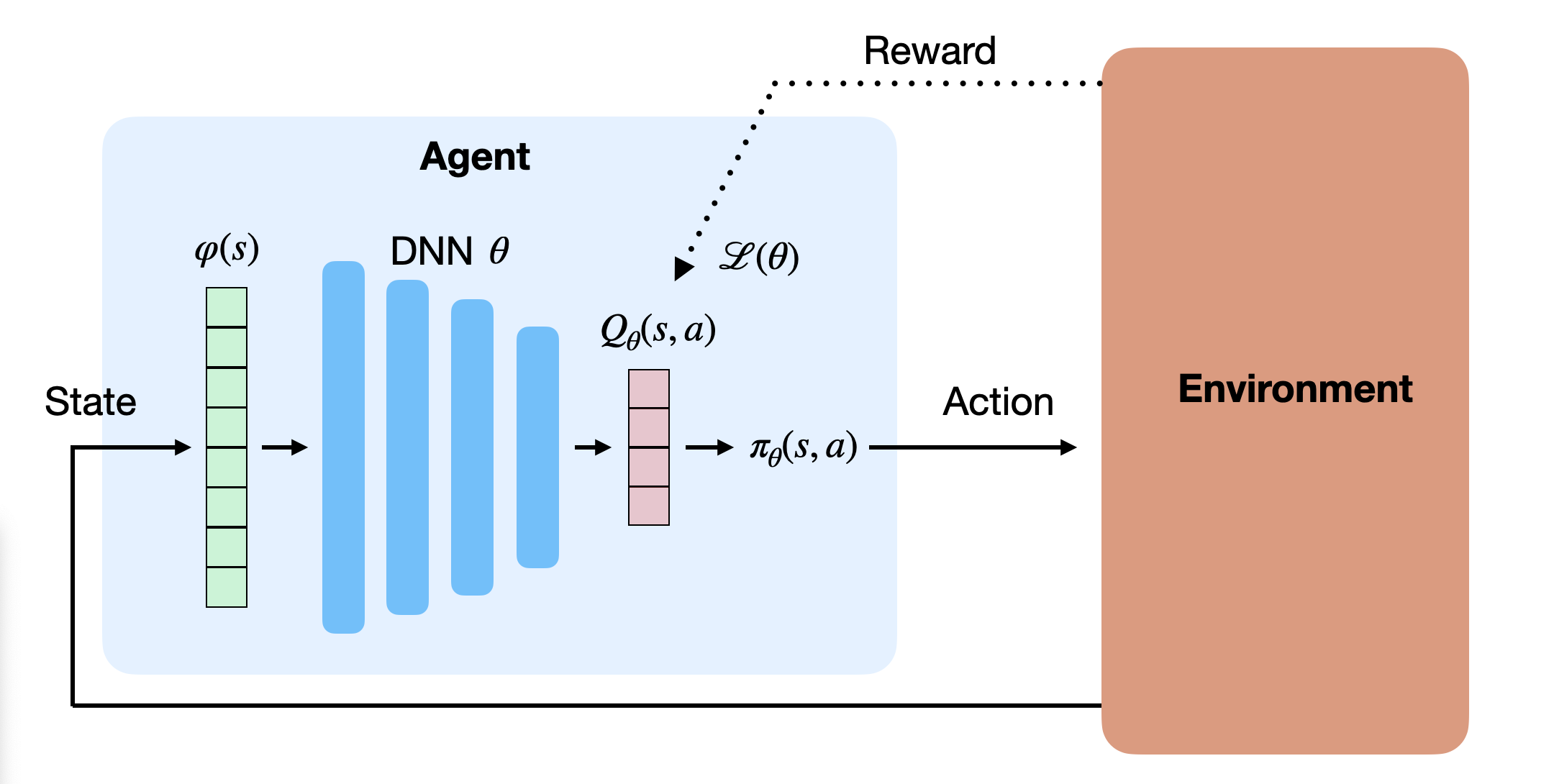
- The basic idea in value-based deep RL is to approximate the Q-values in each possible state, using a deep neural network with free parameters \theta:
Q_\theta(s, a) \approx Q^\pi(s, a) = \mathbb{E}_\pi (R_t | s_t=s, a_t=a)
- The derived policy \pi_\theta uses for example an \epsilon-greedy or softmax action selection scheme over the estimated Q-values:
\pi_\theta(s, a) \leftarrow \text{Softmax} (Q_\theta(s, a))
Function approximators to learn the Q-values
There are two possibilities to approximate Q-values Q_\theta(s, a):
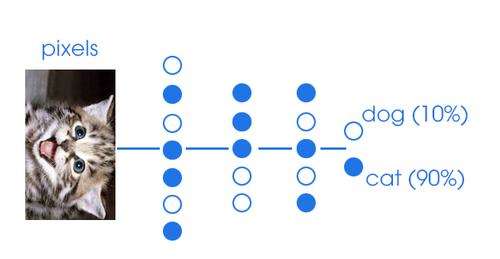
- The DNN approximates the Q-value of a single (s, a) pair.
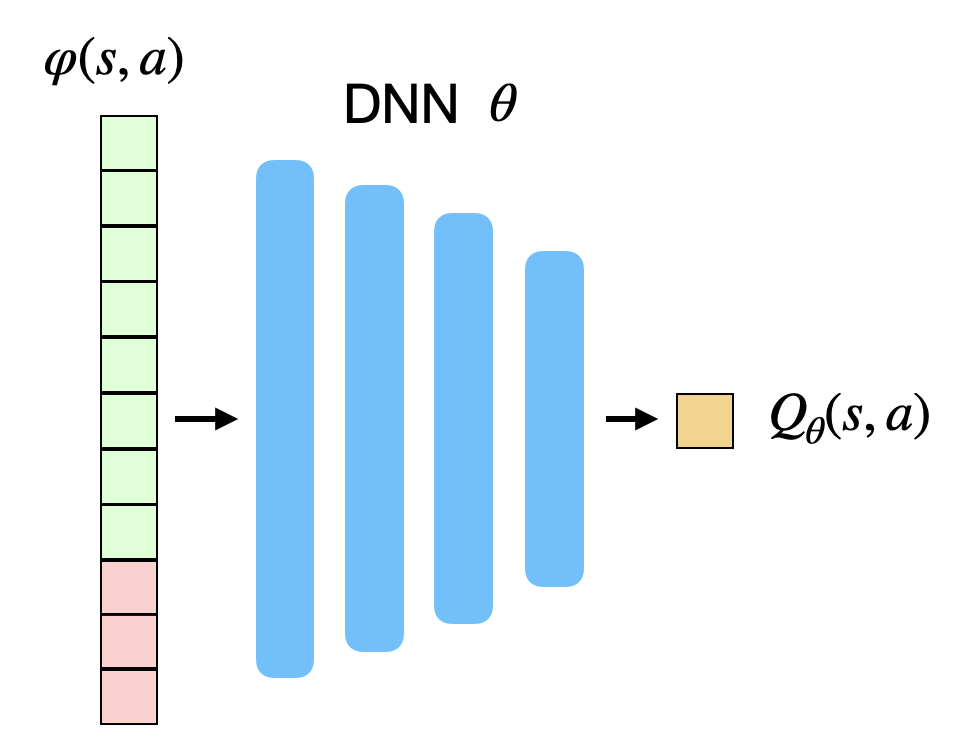
- The action space can be continuous.
- The DNN approximates the Q-value of all actions a in a state s.
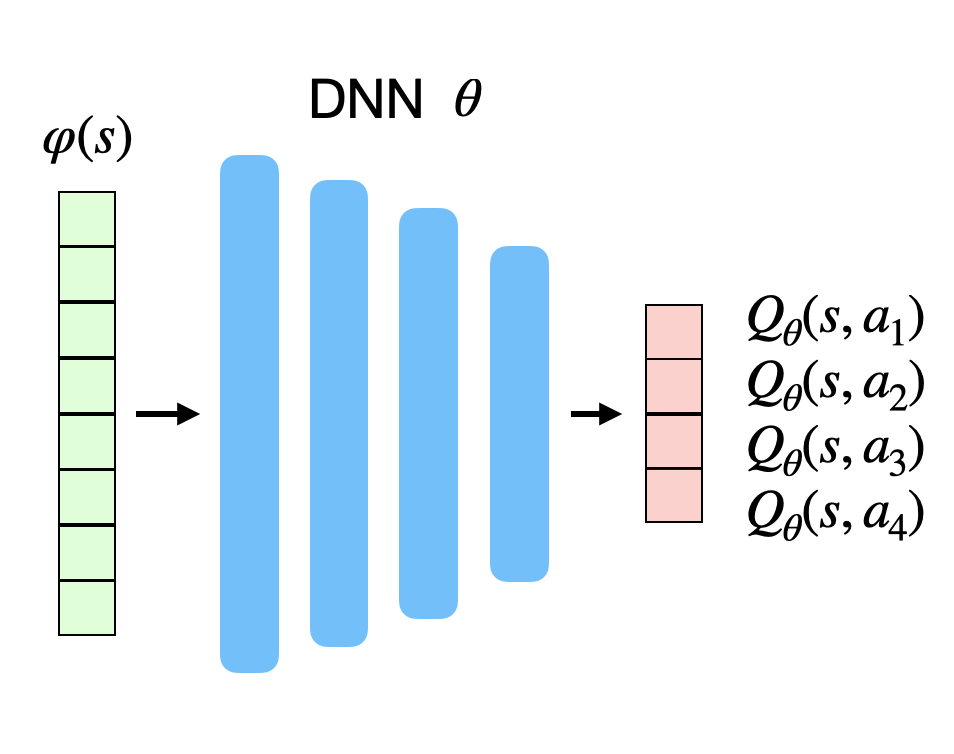
- The action space must be discrete (one neuron per action).
Correlated inputs
Unfortunately, this does not work either.
The last K transitions (s, a, r, s') are not i.i.d (independent and identically distributed).
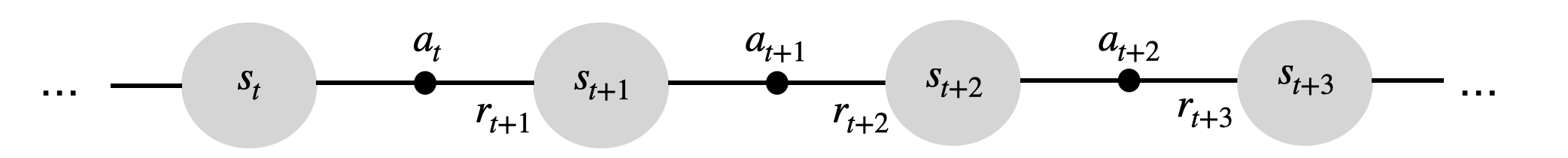
The transition (s_{t+1}, a_{t+1}, r_{t+2}, s_{t+2}) depends on (s_{t}, a_{t}, r_{t+1}, s_{t+1}) by definition, i.e. the transitions are correlated.
Even worse, when playing video games, successive frames will be very similar or even identical.

- The actions are also correlated: you move the paddle to the left for several successive steps.
Correlated inputs
- Feeding transitions sequentially to a DNN is the same as giving all MNIST 0’s to a DNN, then all 1’s, etc… It does not work.

In SL, we have all the training data before training: it is possible to get i.i.d samples by shuffling the training set between two epochs.
In RL, we create the “training set” (transitions) during training: the samples are not i.i.d as we act sequentially over time.
Non-stationarity
- In SL, the targets \mathbf{t} do not change over time: an image of a cat stays an image of a cat throughout learning.
\mathcal{L}(\theta) = \mathbb{E}_{\mathbf{x}, \mathbf{t} \sim \mathcal{D}} [||\mathbf{t} - F_\theta(\mathbf{x})||^2]
- The problem is said stationary, as the distribution of the data does not change over time.
Non-stationarity
In RL, the targets t = r + \gamma \, \max_{a'} Q_\theta(s', a') do change over time:
Q_\theta(s', a') depends on \theta, so after one optimization step, all targets have changed!
As we improve the policy over training, we collect higher returns.
\mathcal{L}(\theta) = \mathbb{E}_{s, a \sim \pi_\theta} [(r + \gamma \, \max_{a'} Q_\theta(s', a') - Q_\theta(s, a))^2]
- NN do not like this. After a while, they give up and settle on a suboptimal policy.

Illustration of non-stationary targets
- We want our value estimates to “catch” the true values.
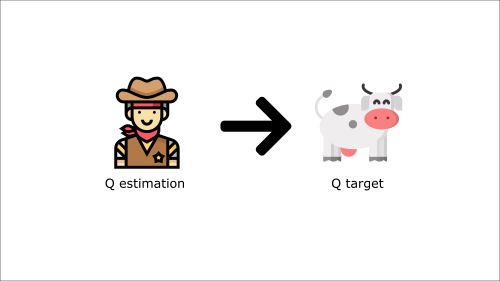
Illustration of non-stationary targets
- We update our estimate to come closer to the target.

Illustration of non-stationary targets
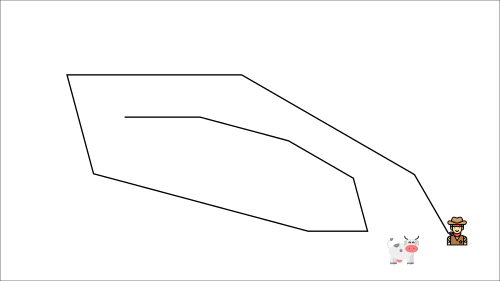
- But the target moves! We need to update again.

Illustration of non-stationary targets
- This leads to very strange and inefficient optimization paths.
1 - Deep Q-networks (DQN)

Problem with non-linear approximators and RL
Non-linear approximators never really worked with RL before 2013 because of:
The correlation between successive inputs or outputs.
The non-stationarity of the problem.
These two problems are very bad for deep networks, which end up overfitting the learned episodes or not learning anything at all.
Deepmind researchers proposed to use two classical ML tricks to overcome these problems:
experience replay memory.
target networks.
Experience replay memory
- To avoid correlation between samples, Mnih et al. (2015) proposed to store the (s, a, r, s') transitions in a huge experience replay memory or replay buffer \mathcal{D} (e.g. 1 million transitions).
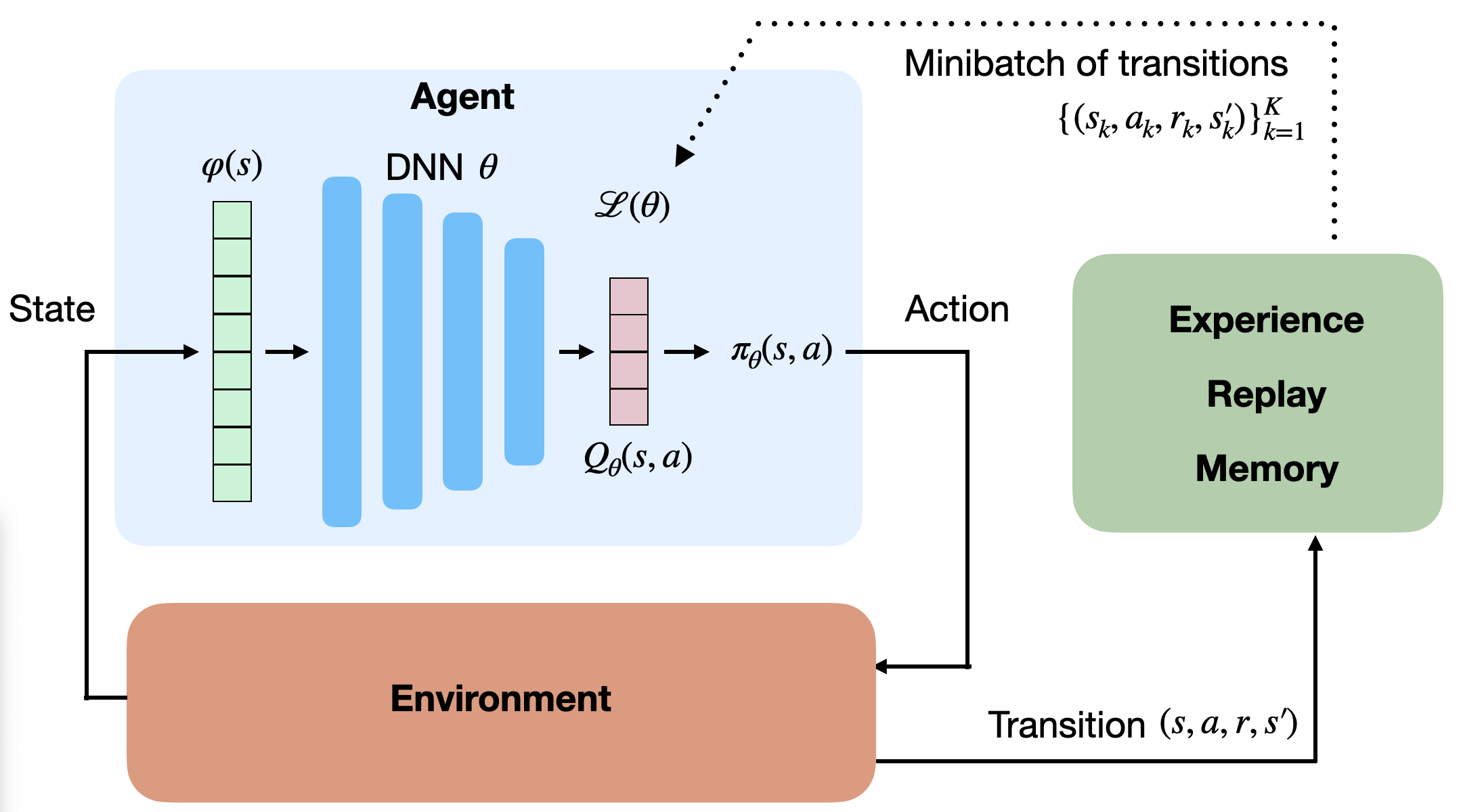
When the buffer is full, we simply overwrite old transitions.
The Q-learning update is only applied on a random minibatch of those past experiences, not the last transitions.
This ensures the independence of the samples (non-correlated samples).
Experience replay memory
But wait! The samples of the minibatch are still not i.i.d, as they are not identically distributed:
Some samples were generated with a very old policy \pi_{\theta_0}.
Some samples have been generated recently by the current policy \pi_\theta.
The samples of the minibatch do not come from the same distribution, so this should not work.
Target network
- The second problem when using DNN for RL is that the target is non-stationary, i.e. it changes over time: as the network becomes better, the Q-values have to increase.
- In DQN, the target for the update is not computed from the current deep network \theta:
r + \gamma \, \max_{a'} Q_\theta(s', a')
but from a target network \theta´ updated only every few thousands of iterations.
r + \gamma \, \max_{a'} Q_{\theta'}(s', a')
- \theta' is simply a copy of \theta from the past.
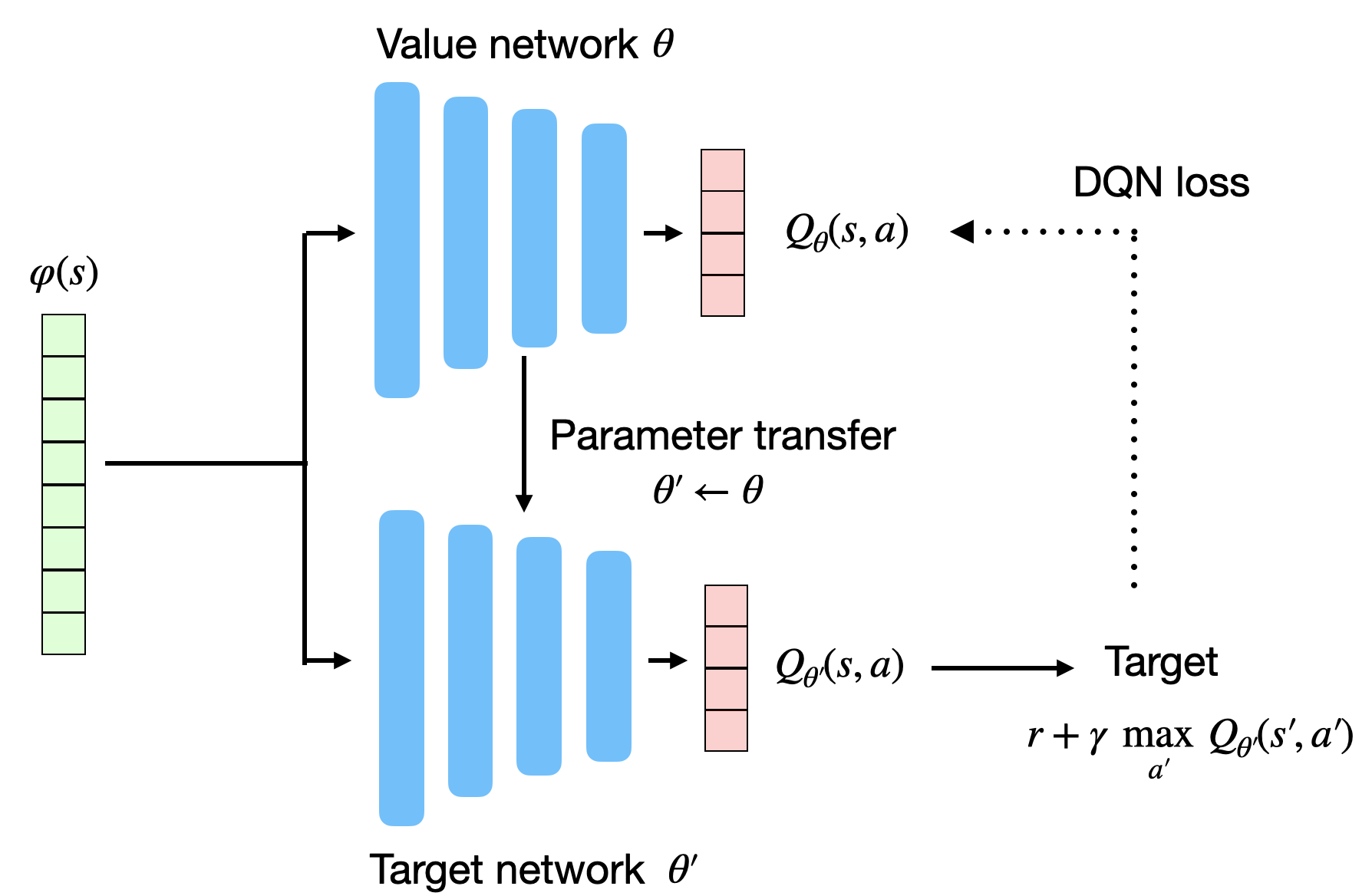
- DQN loss function:
\mathcal{L}(\theta) = \mathbb{E}_\mathcal{D} [(r + \gamma \, \max_{a'} Q_{\theta'}(s', a')) - Q_\theta(s, a))^2]
Target network
This allows the target r + \gamma \, \max_{a'} Q_{\theta'}(s', a') to be stationary between two updates.
It leaves time for the trained network to catch up with the targets.

- The update is simply replacing the parameters \theta' with the trained parameters \theta:
\theta' \leftarrow \theta
- The value network \theta basically learns using an older version of itself…
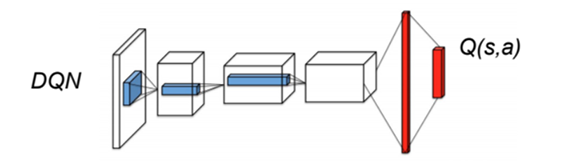
DQN: Deep Q-network
The deep network can be anything. Deep RL is only about defining the loss function adequately.
For pixel-based problems (e.g. video games), convolutional neural networks (without max-pooling) are the weapon of choice.
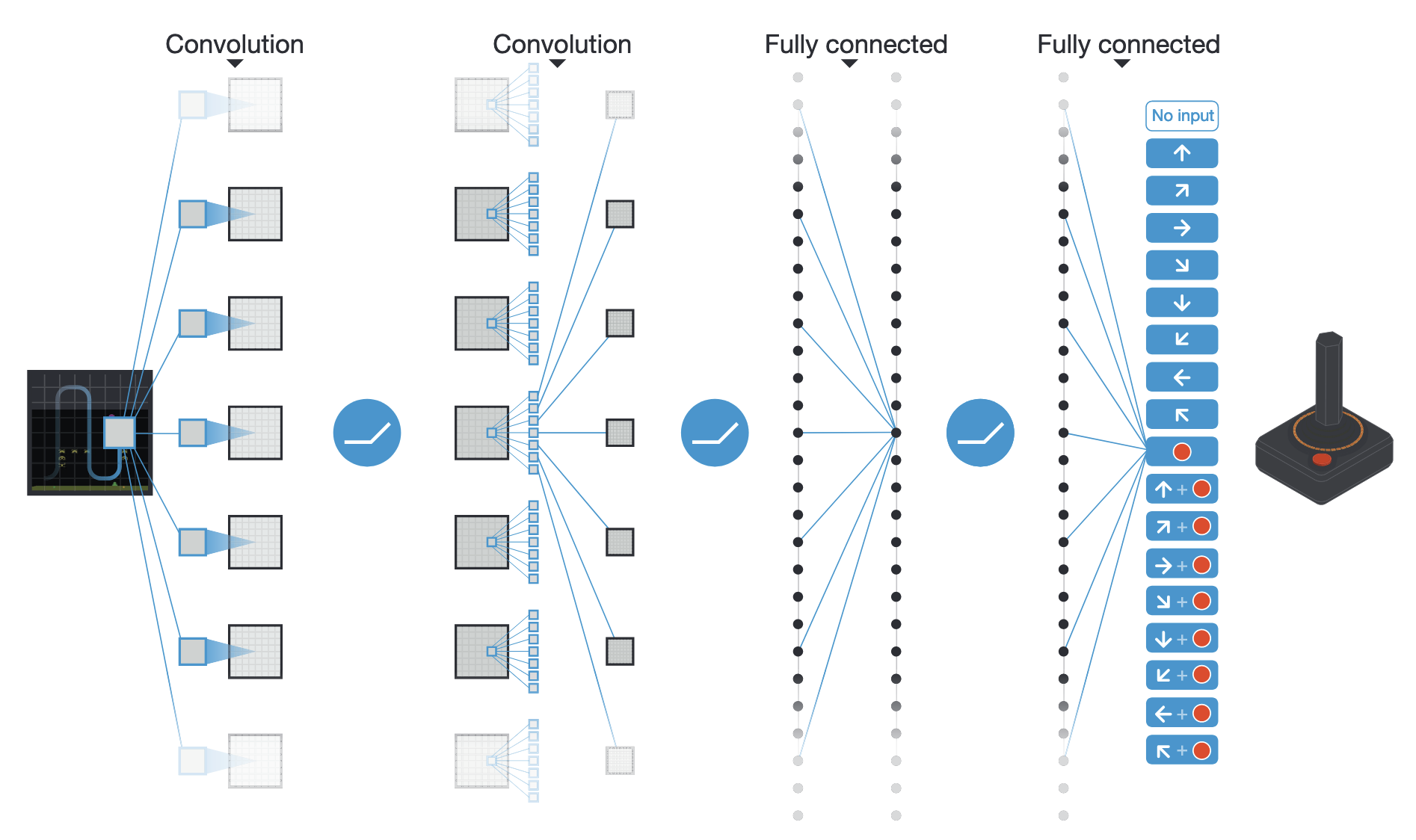
Why no max-pooling?
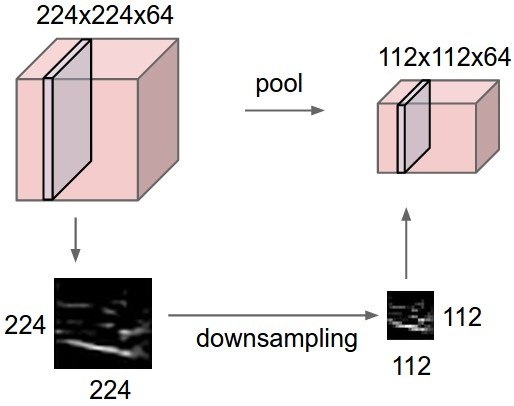
The goal of max-pooling is to get rid of the spatial information in the image.
For object recognition, you do not care whether the object is in the center or on the side of the image.
Max-pooling brings spatial invariance.
In video games, you want to keep the spatial information: the optimal action depends on where the ball is relative to the paddle.
Are individual frames good representations of states?
- Is the ball moving from the child to the baseball player, or the other way around?

Using video frames as states breaks the Markov property: the speed and direction of the ball is a very relevant information for the task, but not contained in a single frame.
This characterizes a Partially-observable Markov Decision Process (POMDP).
Markov property in video games
The simple solution retained in the original DQN paper is to stack the last four frames to form the state representation.
Having the previous positions of the ball, the network can learn to infer its direction of movement.
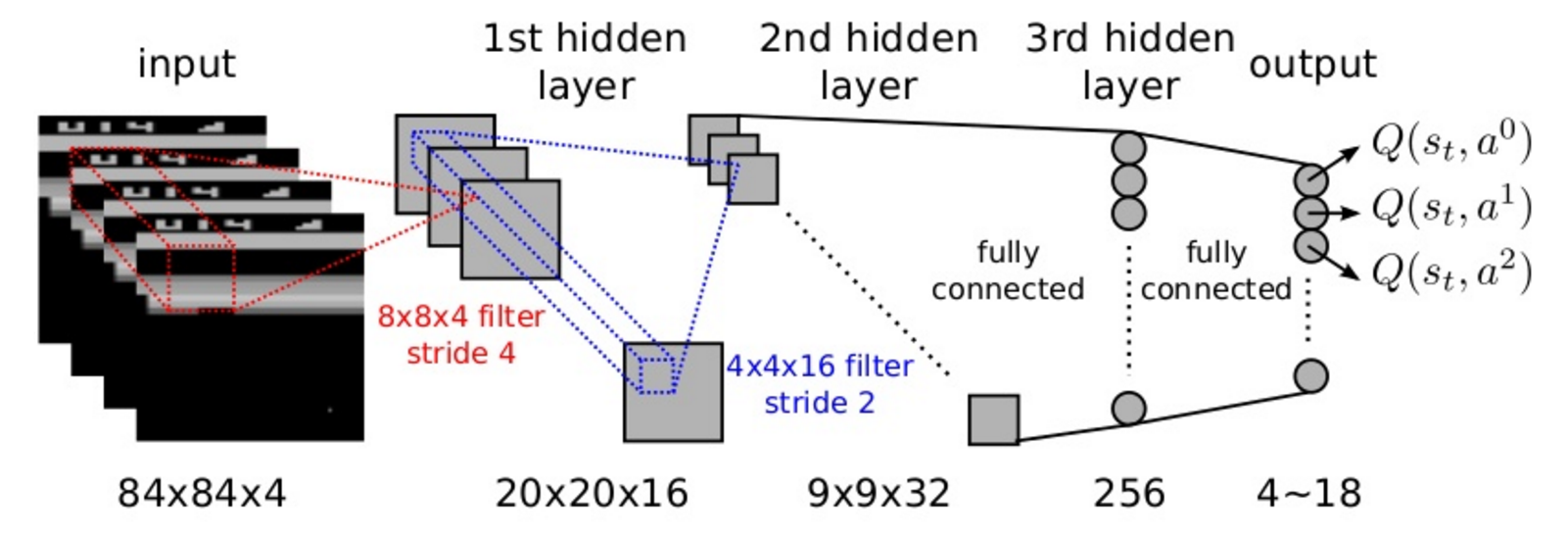
DQN training
50M frames (38 days of game experience) per game. Replay buffer of 1M frames.
Action selection: \epsilon-greedy with \epsilon = 0.1 and annealing. Optimizer: RMSprop with a batch size of 32.

DQN to solve multiple Atari games
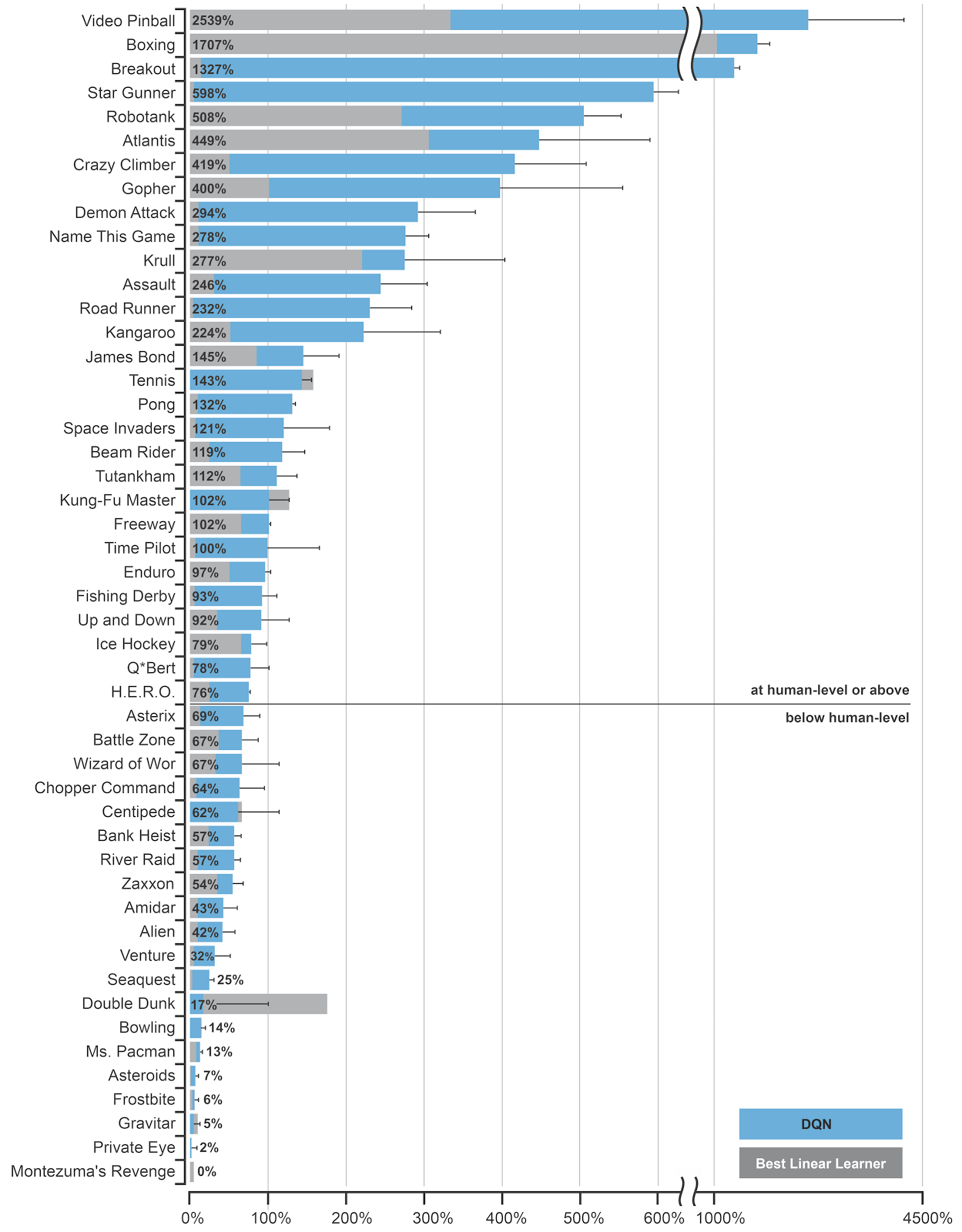
The DQN network was trained to solve 49 different Atari 2600 games with the same architecture and hyperparameters.
In most of the games, the network reaches super-human performance.
Some games are still badly performed (e.g. Montezuma’s revenge), as they require long-term planning.
It was the first RL algorithm able to learn different tasks (no free lunch theorem).
The 2015 paper in Nature started the hype for deep RL.
2 - Double DQN

Double DQN
- Q-learning methods, including DQN, tend to overestimate Q-values, especially for the non-greedy actions:
Q_\theta(s, a) > Q^\pi(s, a)
- This does not matter much in action selection, as we apply \epsilon-greedy or softmax on the Q-values anyway, but it may make learning slower (sample complexity) and less optimal.
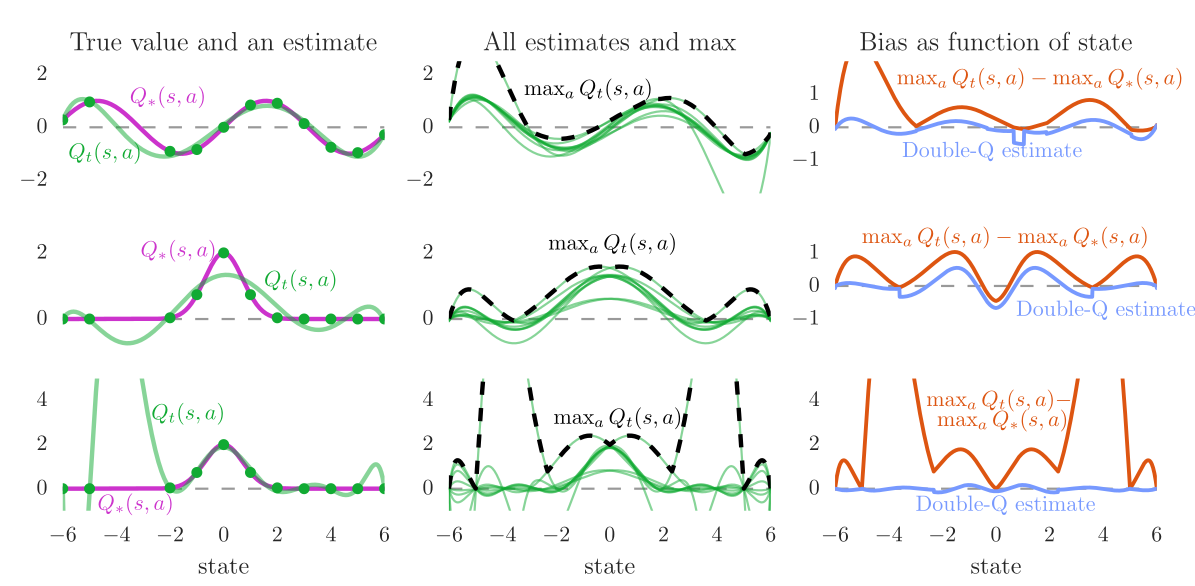
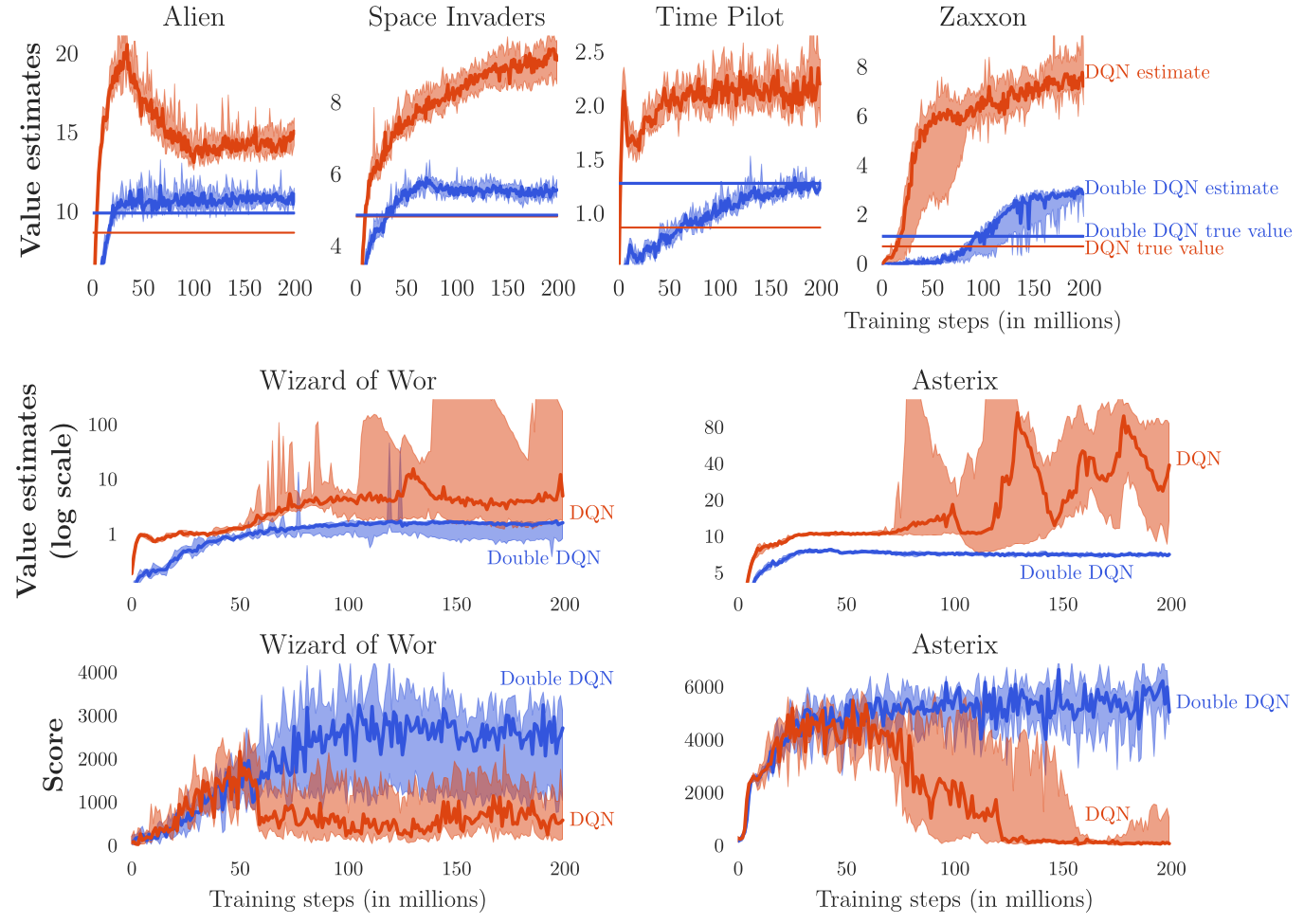
3 - Prioritized Experience Replay

Prioritized Experience Replay
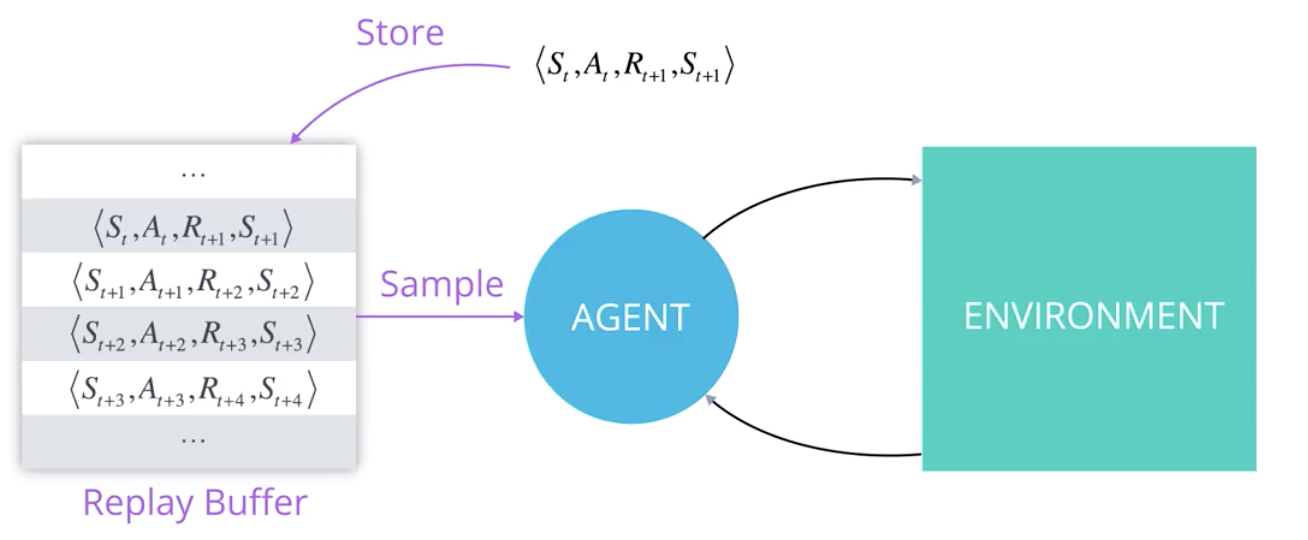
The experience replay memory or replay buffer is used to store the last 1M transitions (s, a, r, s').
The learning algorithm randomly samples a minibatch of size K to update its parameters.
Not all transitions are interesting:
Some transitions were generated by a very old policy, the current policy won’t take them anymore.
Some transitions are already well predicted: the TD error is small, there is nothing to learn from.
\delta_t = r_{t+1} + \gamma \, \max_{a'} Q_\theta(s_{t+1}, a_{t+1}) - Q_\theta(s_t, a_t) \approx 0
Prioritized Experience Replay
The experience replay memory makes learning very slow: we need a lot of samples to learn something useful:
- High sample complexity.
We need a smart mechanism to preferentially pick the transitions that will boost learning the most, without introducing a bias.
- Prioritized sweeping is actually a quite old idea:
Moore and Atkeson (1993) Prioritized sweeping: Reinforcement learning with less data and less time. Machine Learning, 13(1):103–130.
Prioritized Experience Replay
The main drawback is that inserting and sampling can be computationally expensive if we simply sort the transitions based on (|\delta_k| + \epsilon)^\alpha:
Insertion: \mathcal{O}(N \, \log N).
Sampling: \mathcal{O}(N).
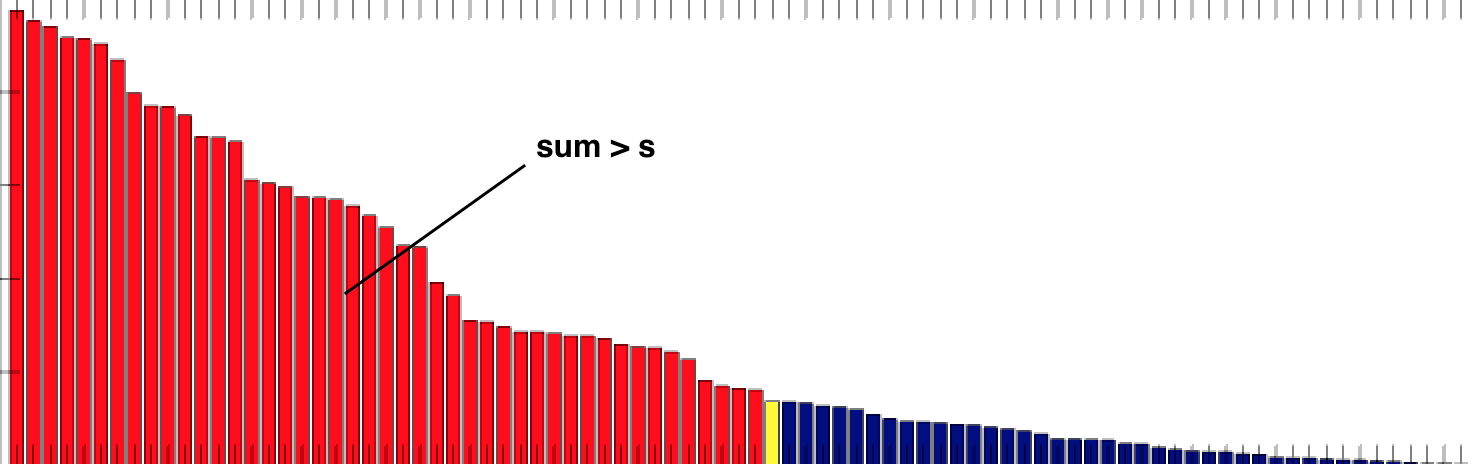
Prioritized Experience Replay
Using binary sumtrees, prioritized experience replay can be made efficient in both insertion (\mathcal{O}(\log N)) and sampling (\mathcal{O}(1)).
Instead of a linear queue, we use a binary tree to store the transitions.
Details in a real computer science course…
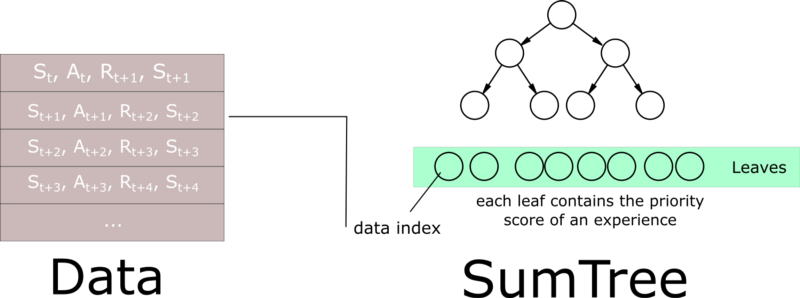
Prioritized Experience Replay
Prioritized Experience Replay

4 - Dueling networks

Dueling networks
- DQN and its variants learn to predict directly the Q-value of each available action.
Several problems with predicting Q-values with a DNN:
The Q-values can take high values, especially with different values of \gamma.
The Q-values have a high variance, between the minimum and maximum returns obtained during training.
For a transition (s_t, a_t, s_{t+1}), a single Q-value is updated, not all actions in s_t.
Dueling networks
- Enduro game.


The exact Q-values of all actions are not equally important.
In bad states (low V^\pi(s)), you can do whatever you want, you will lose.
In neutral states, you can do whatever you want, nothing happens.
In good states (high V^\pi(s)), you need to select the right action to get rewards, otherwise you lose.
Advantage functions

- An important notion is the advantage A^\pi(s, a) of an action:
A^\pi(s, a) = Q^\pi(s, a) - V^\pi(s)
It tells how much return can be expected by taking the action a in the state s, compared to what is usually obtained in s with the current policy.
If a policy \pi is deterministic and always selects a^* in s, we have:
A^\pi(s, a^*) = 0 A^\pi(s, a \neq a^*) < 0
This is particularly true for the optimal policy.
But if we have separate estimates V_\varphi(s) and Q_\theta(s, a), some actions may have a positive advantage.
Advantages have less variance than Q-values.
Dueling networks
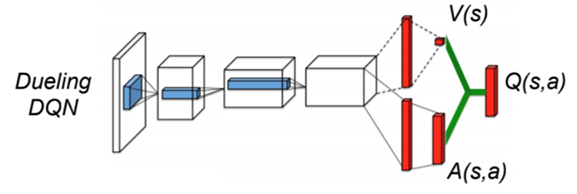
- In dueling networks, the network is forced to decompose the estimated Q-value Q_\theta(s, a) into a state value V_\alpha(s) and an advantage function A_\beta(s, a):
Q_\theta(s, a) = V_\alpha(s) + A_\beta(s, a)
The parameters \alpha and \beta are just two shared subparts of the NN \theta.
The loss function
\mathcal{L}(\theta) = \mathbb{E}_\mathcal{D} [(r + \gamma \, Q_{\theta'}(s´, \text{argmax}_{a'} Q_{\theta}(s', a')) - Q_\theta(s, a))^2]
is exactly the same as in (D)DQN: only the internal structure of the NN changes.
Visualization of the value and advantage functions
- Which pixels change the most the value and advantage functions?

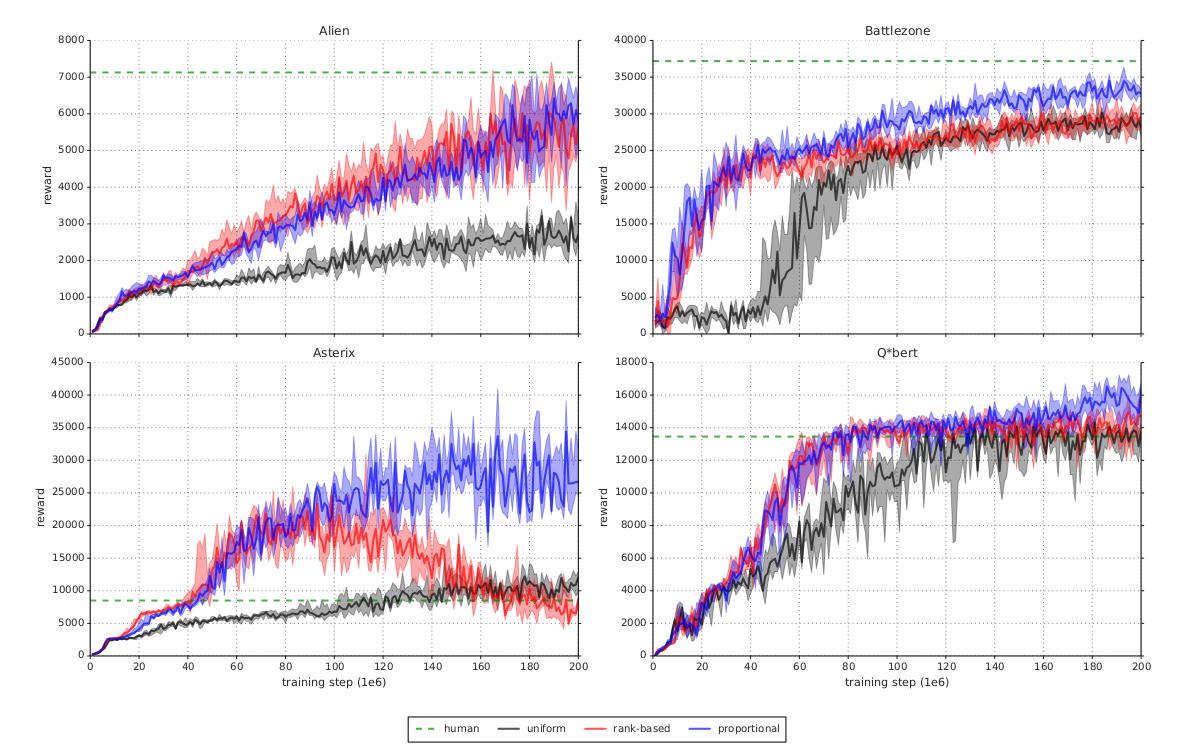
Improvement over prioritized DDQN
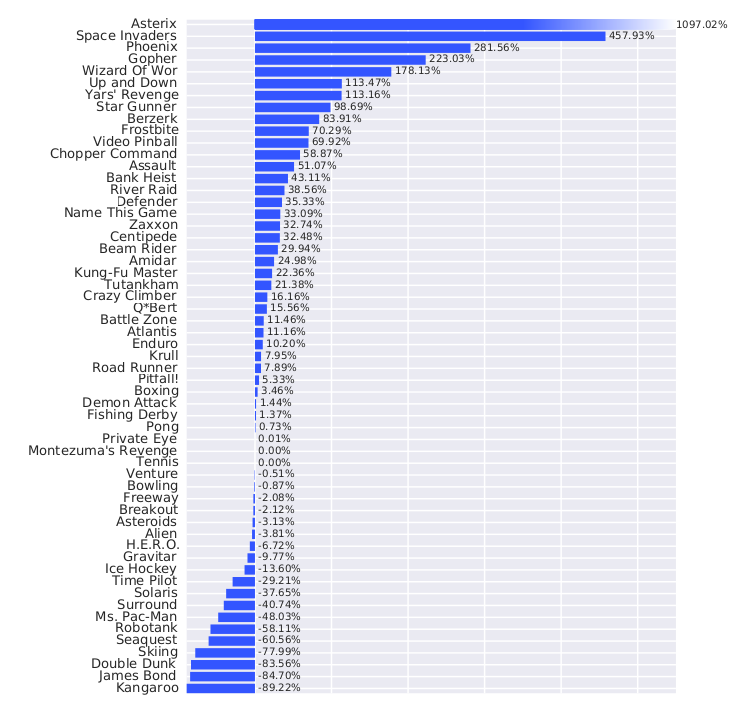
Summary of DQN
DQN and its early variants (double duelling DQN with PER) are an example of value-based deep RL.
The value Q_\theta(s, a) of each possible action in a given state is approximated by a convolutional neural network.
The NN has to minimize the mse between the predicted Q-values and the target value corresponding to the Bellman equation:
\mathcal{L}(\theta) = \mathbb{E}_\mathcal{D} [(r + \gamma \, Q_{\theta'}(s´, \text{argmax}_{a'} Q_{\theta}(s', a')) - Q_\theta(s, a))^2]
The use of an experience replay memory and of target networks allows to stabilize learning and avoid suboptimal policies.
The main drawback of DQN is sample complexity: it needs huge amounts of experienced transitions to find a correct policy. The sample complexity come from the deep network itself (gradient descent is iterative and slow), but also from the ERM: it contains 1M transitions, most of which are outdated.
Only works for small and discrete action spaces (one output neuron per action).