Deep Reinforcement Learning
Advantage actor-critic (A2C, A3C)
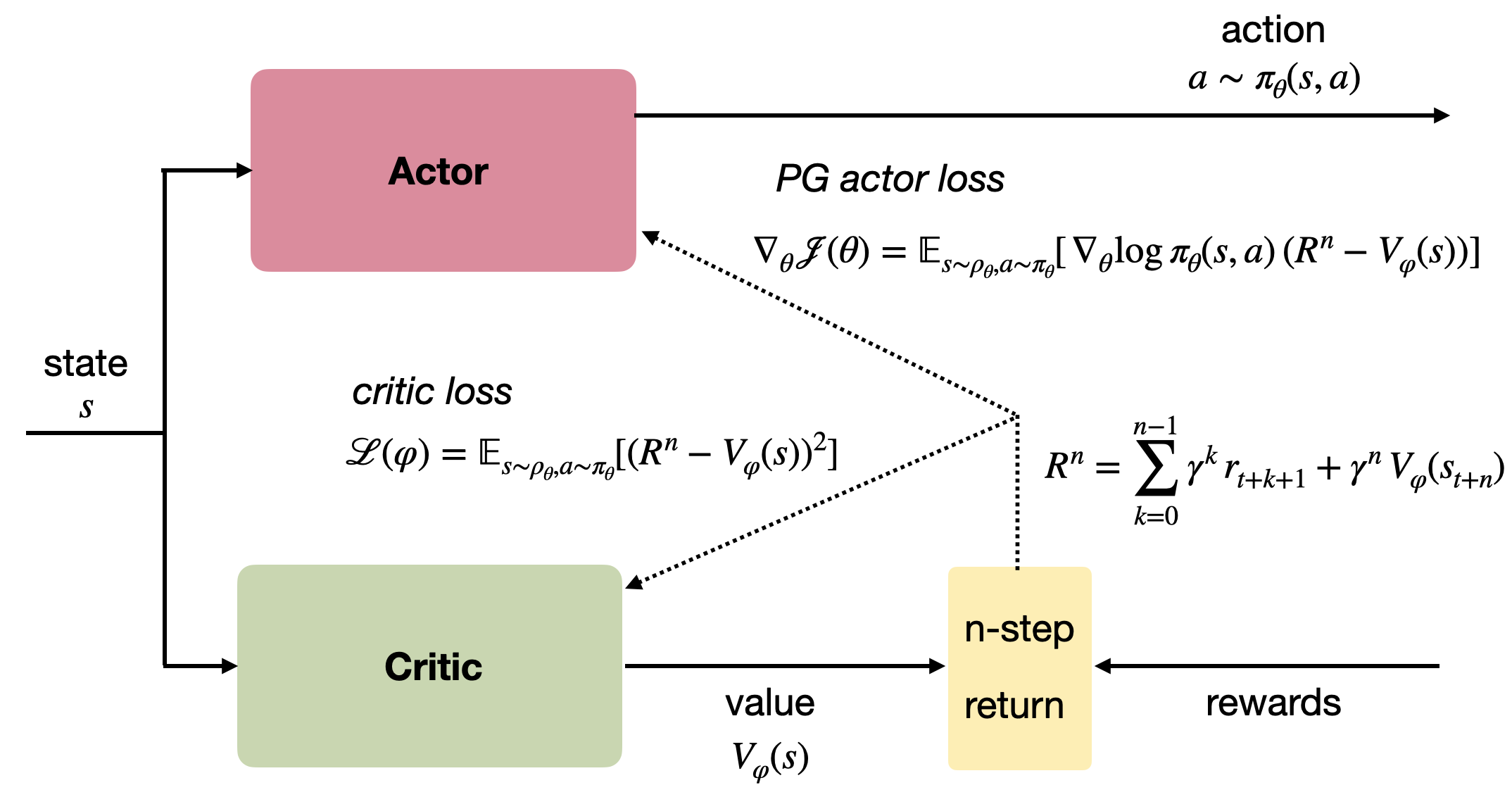
Advantage actor-critic
- Let’s consider an n-step advantage actor-critic:
A^n_t = R_t^n - V_\varphi (s_t) = \sum_{k=0}^{n-1} \gamma^{k} \, r_{t+k+1} + \gamma^n \, V_\varphi(s_{t+n}) - V_\varphi (s_t)
Distributed RL
- We cannot get an uncorrelated batch of transitions by acting sequentially with a single agent.
- A simple solution is to have multiple actors with the same weights \theta interacting in parallel with different copies of the environment.

Each rollout worker (actor) starts an episode in a different state: at any point of time, the workers will be in uncorrelated states.
From time to time, the workers all send their experienced transitions to the learner which updates the policy using a batch of uncorrelated transitions.
After the update, the workers use the new policy.
2 - A3C: Asynchronous advantage actor-critic

A3C: Asynchronous advantage actor-critic
Mnih et al. (2016) proposed the A3C algorithm (asynchronous advantage actor-critic).
The stochastic policy \pi_\theta is produced by the actor with weights \theta and learned using :
\nabla_\theta \mathcal{J}(\theta) = \mathbb{E}_{s_t \sim \rho_\theta, a_t \sim \pi_\theta}[\nabla_\theta \log \pi_\theta (s_t, a_t) \, (R^n_t - V_\varphi(s_t)) ]
- The value of a state V_\varphi(s) is produced by the critic with weights \varphi, which minimizes the mse with the n-step return:
\mathcal{L}(\varphi) = \mathbb{E}_{s_t \sim \rho_\theta, a_t \sim \pi_\theta}[(R^n_t - V_\varphi(s_t))^2]
R^n_t = \sum_{k=0}^{n-1} \gamma^{k} \, r_{t+k+1} + \gamma^n \, V_\varphi(s_{t+n})
Both the actor and the critic are trained on batches of transitions collected using parallel workers.
Two things are different from the general distributed approach: workers compute partial gradients and updates are asynchronous.
A3C: Asynchronous advantage actor-critic
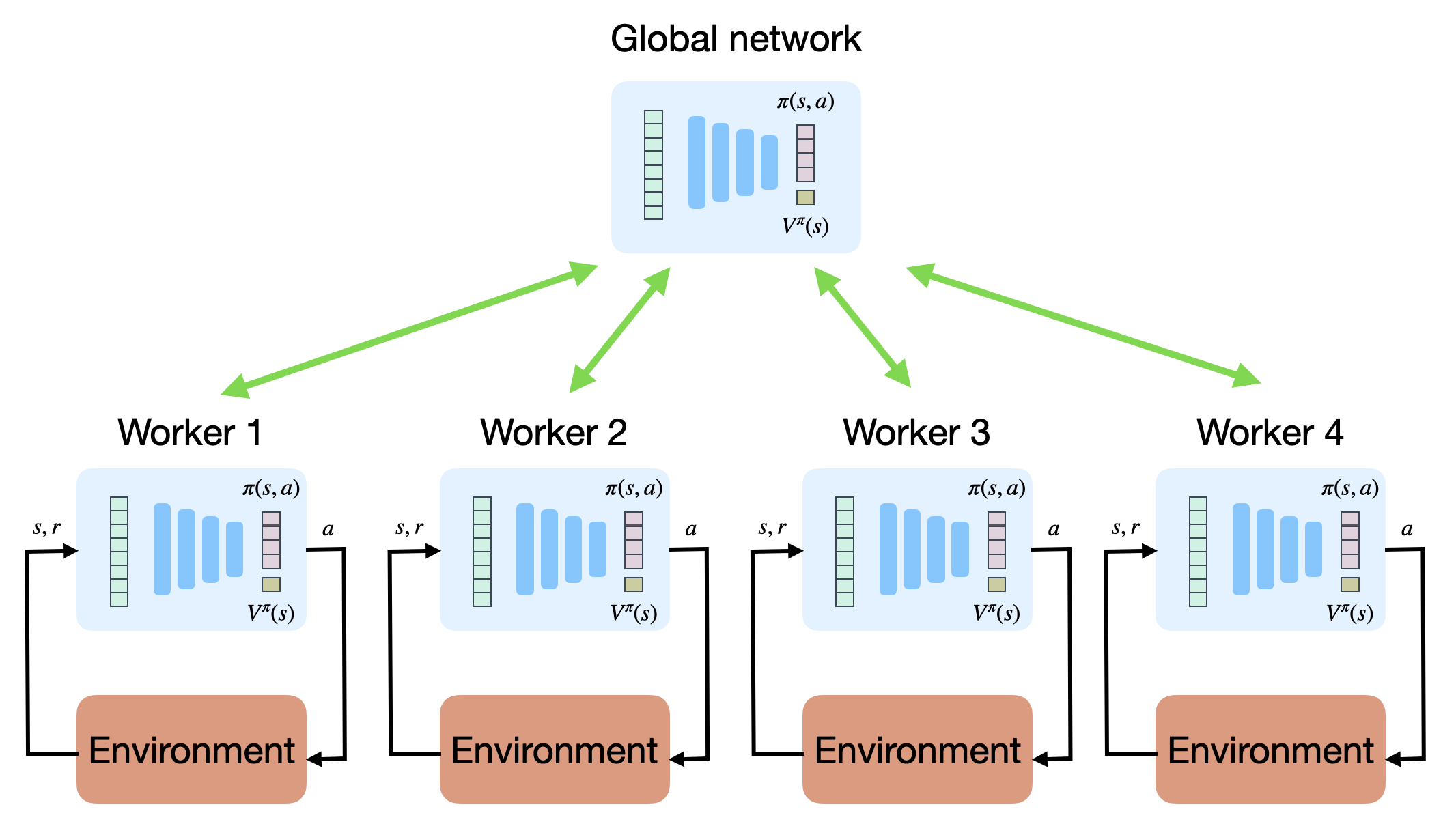
A3C: Asynchronous advantage actor-critic
A3C does not use an experience replay memory, but relies on multiple parallel workers to distribute learning.
Each worker has a copy of the actor and critic networks, as well as an instance of the environment.
Weight updates are synchronized regularly though a master network using Hogwild!-style updates (every n=5 steps!).
Because the workers learn different parts of the state-action space, the weight updates are not very correlated.
It works best on shared-memory systems (multi-core) as communication costs between GPUs are huge.
As an actor-critic method, it can deal with continuous action spaces.
A3C : results
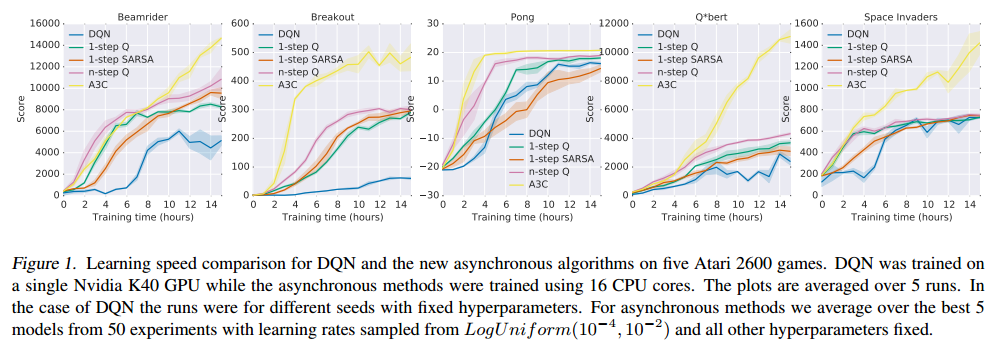
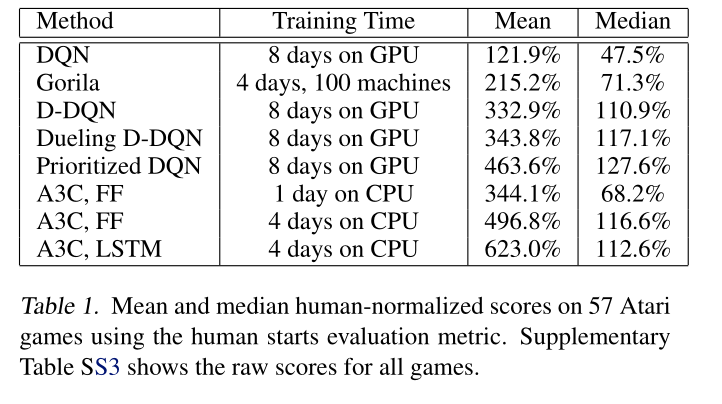
A3C set a new record for Atari games in 2016.
The main advantage is that the workers gather experience in parallel: training is much faster than with DQN.
LSTMs can be used to improve the performance.
A3C : results
- Learning is only marginally better with more threads:
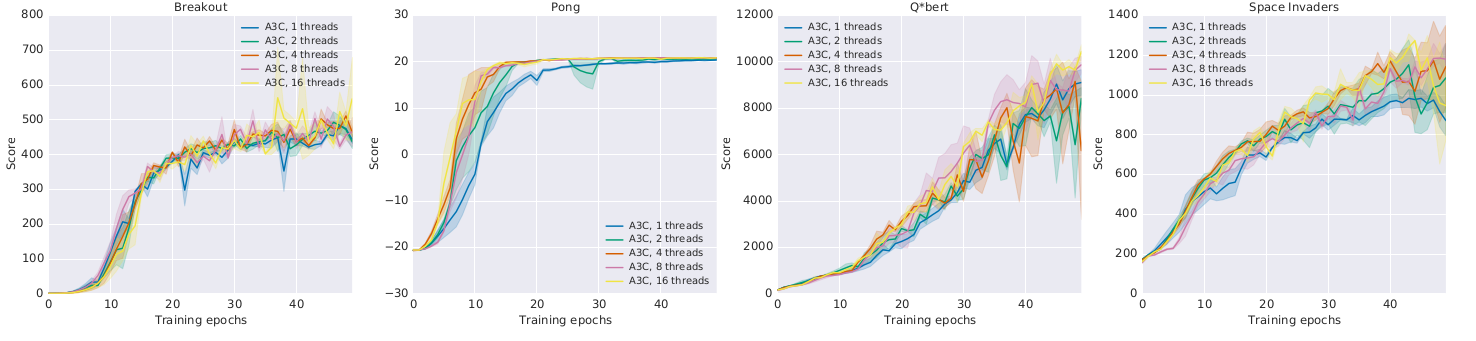
but much faster!
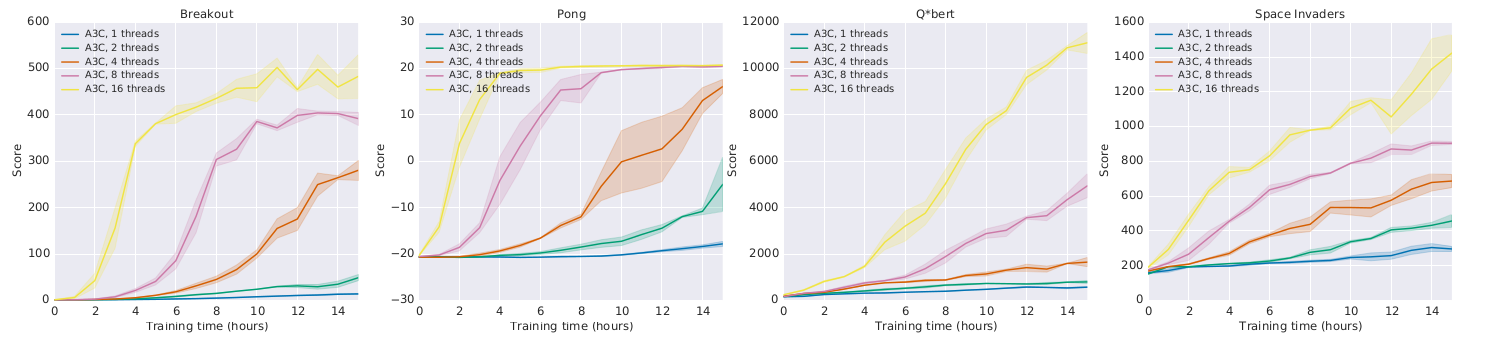
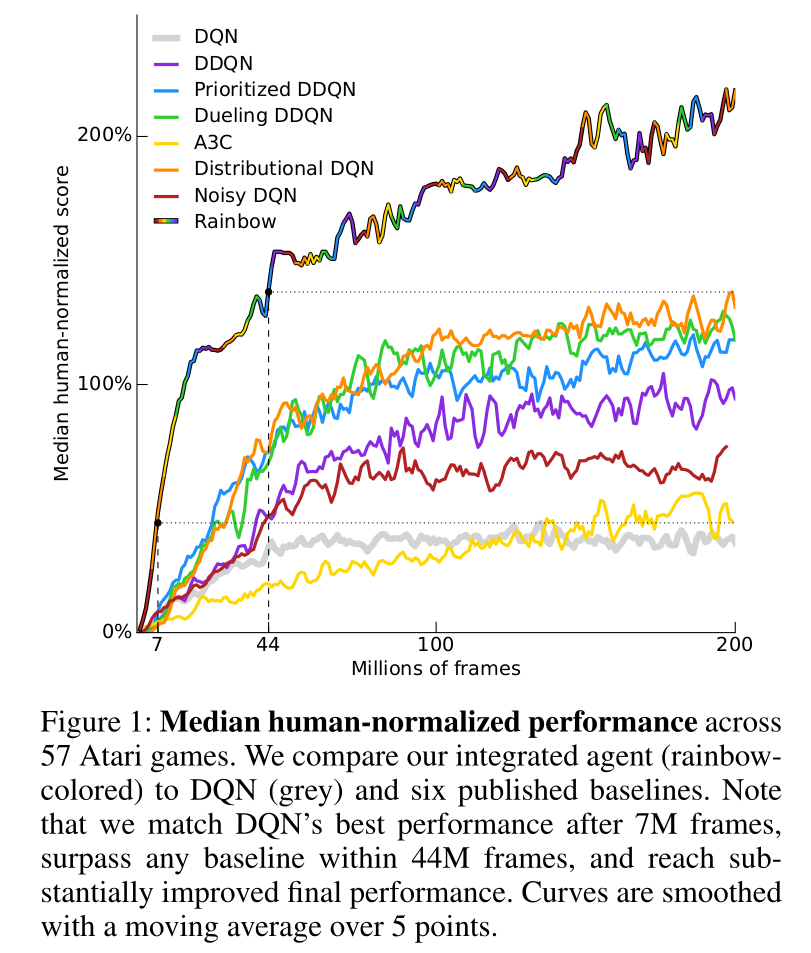
Comparison with DQN
- A3C came up in 2016. A lot of things happened since then…
Actor-critic neural architectures
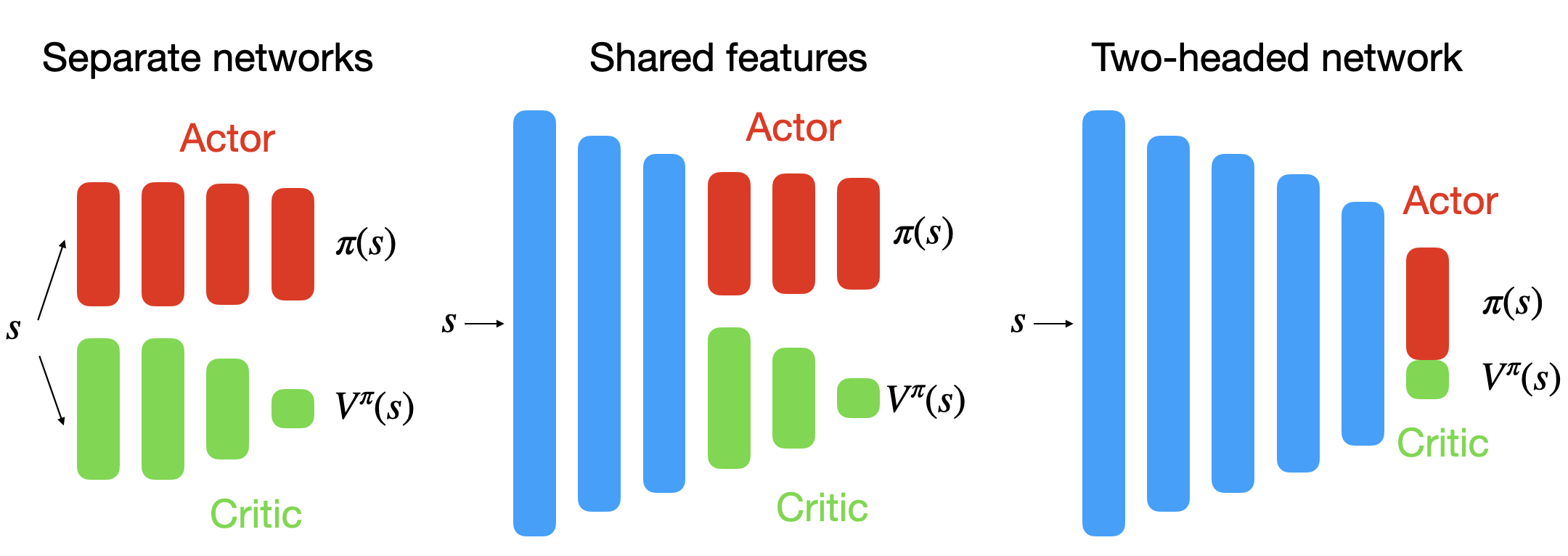
- We have considered that actor-critic architectures consist of two separate neural networks, both taking the state s (or observation o) as an input.
Each of these networks have their own loss function. They share nothing except the “data”.
Is it really the best option?
Early visual features
When working on images, the first few layers of the CNNs are likely to learn the same visual features (edges, contours).
It would be more efficient to share some of the extracted features.
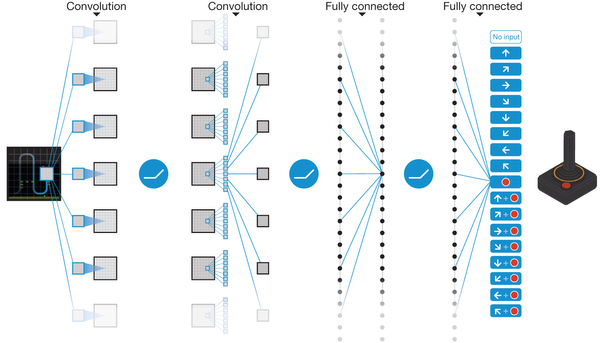
Shared architectures
Actor-critic architectures can share layers between the actor and the critic, sometimes up to the output layer.
A compound loss sums the losses for the actor and the critic. Tensorflow/pytorch know which parameters influence which part of the loss.
\mathcal{L}(\theta) = \mathcal{L}_\text{actor}(\theta) + \mathcal{L}_\text{critic}(\theta)
For pixel-based environments (Atari), the networks often share the convolutional layers.
For continuous environments (Mujoco), separate networks sometimes work better than two-headed networks.
Continuous action spaces
One of the main advantages of actor-critic / PG methods over value-based methods is that they can deal with continuous action-spaces.
Suppose that we want to control a robotic arm with n degrees of freedom.
An action \mathbf{a} could be a vector of joint displacements:
\mathbf{a} = \begin{bmatrix} \Delta \theta_1 & \Delta \theta_2 & \ldots \, \Delta \theta_n\end{bmatrix}^T
The output layer of the policy network can very well represent this vector, but how would we implement exploration?
\epsilon-greedy and softmax action selection would not work, as all neurons are useful.
The most common solution is to use a stochastic Gaussian policy.


Gaussian policies
A Gaussian policy considers the vector \mathbf{a} to be sampled from the normal distribution \mathcal{N}(\mu_\theta(s), \sigma_\theta(s)).
The mean \mu_\theta(s) and standard deviation \sigma_\theta(s) are output vectors of the actor with parameters \theta.
Sampling an action from the normal distribution is done through the reparameterization trick:
\mathbf{a} = \mu_\theta(s) + \sigma_\theta(s) \, \xi
where \xi \sim \mathcal{N}(0, I) comes from the standard normal distribution.
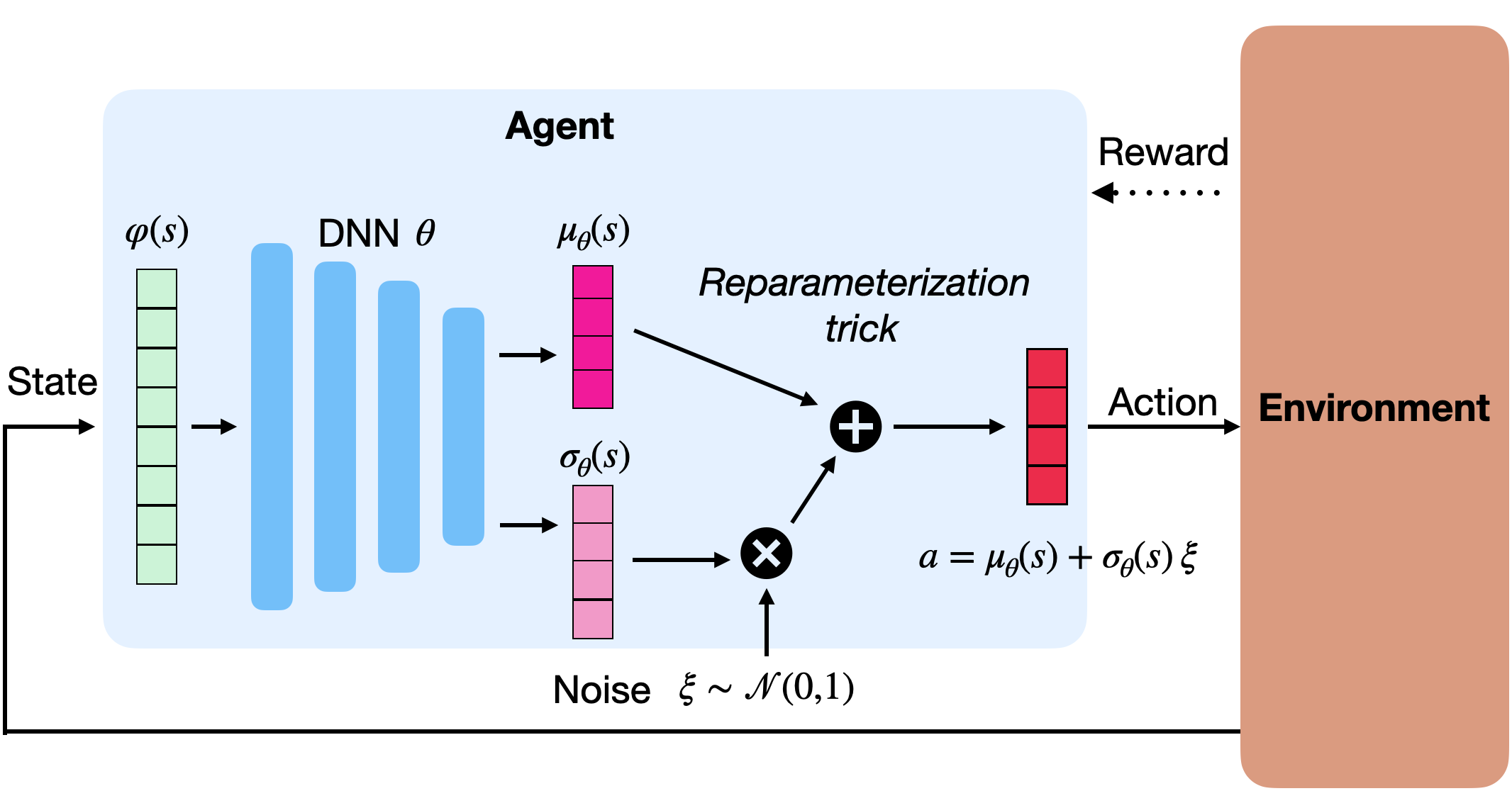
Gaussian policies
- A Gaussian policy samples actions from the normal distribution \mathcal{N}(\mu_\theta(s), \sigma_\theta(s)), with \mu_\theta(s) and \sigma_\theta(s) being the output of the actor.
\mathbf{a} = \mu_\theta(s) + \sigma_\theta(s) \, \xi
- The score \nabla_\theta \log \pi_\theta (s, a) can be obtained easily using the output of the actor:
\begin{cases} \nabla_{\mu_\theta(s)} \log \pi_\theta (s, a) = \dfrac{a - \mu_\theta(s)}{\sigma_\theta(s)^2} \\ \\ \nabla_{\sigma_\theta(s)} \log \pi_\theta (s, a) = \dfrac{(a - \mu_\theta(s))^2}{\sigma_\theta(s)^3} - \dfrac{1}{\sigma_\theta(s)}\\ \end{cases}
The rest of the score (\nabla_\theta \mu_\theta(s) and \nabla_\theta \sigma_\theta(s)) is the problem of tensorflow/pytorch.
This is the same reparametrization trick used in variational autoencoders to allow backpropagation to work through a sampling operation.
Beta distributions are an even better choice to parameterize stochastic policies (Chou et al., 2017).