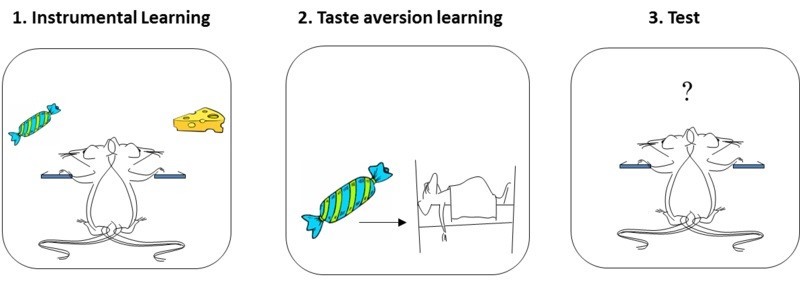
Habits are developed by overtraining Stimulus \rightarrow Response associations.
The main difference is that habits are not influenced by outcome devaluation, i.e. when rewards lose their value.
Source: Bernard W. Balleine
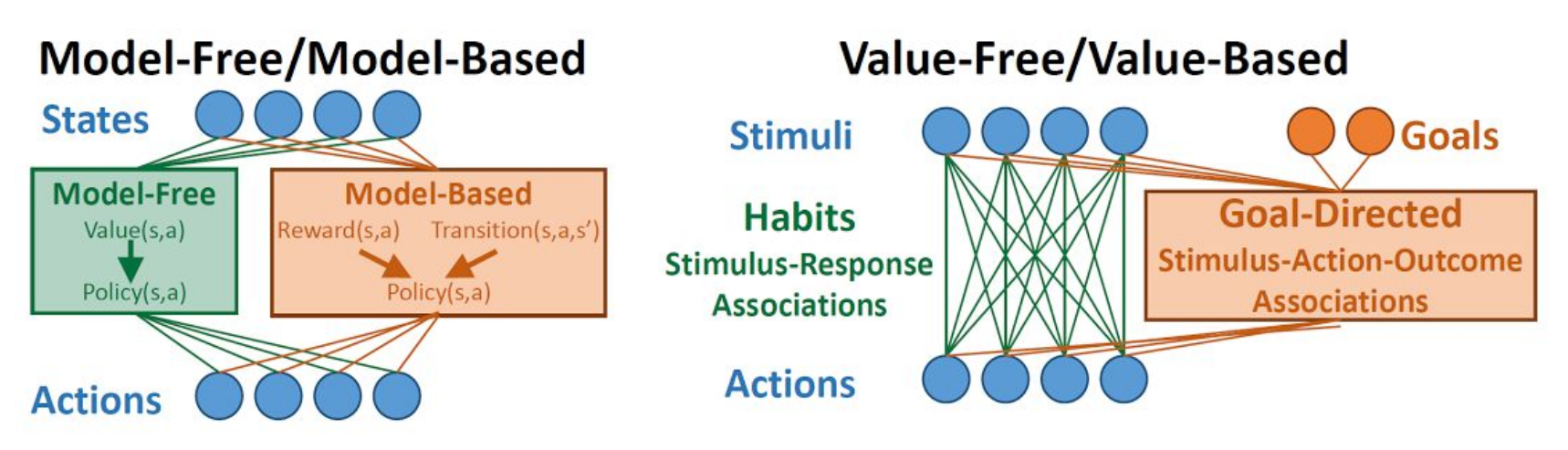
Goal-directed / habits = MB / MF ?
The classical theory assigns MF to habits and MB to goal-directed, mostly because their sensitivity to outcome devaluation.
The open question is the arbitration mechanism between these two segregated process: who takes control?
Recent work suggests both systems are largely overlapping.
References
Doll, B. B., Simon, D. A., and Daw, N. D. (2012). The ubiquity of model-based reinforcement learning. Current Opinion in Neurobiology 22, 1075–1081. doi:10.1016/j.conb.2012.08.003.
Miller, K., Ludvig, E. A., Pezzulo, G., and Shenhav, A. (2018). “Re-aligning models of habitual and goal-directed decision-making,” in Goal-Directed Decision Making : Computations and Neural Circuits, eds. A. Bornstein, R. W. Morris, and A. Shenhav (Academic Press)
2 - Successor representations
Successor Representations (SR)
Successor representations (SR) have been introduced to combine MF and MB properties. Let’s split the definition of the value of a state:
where \mathbb{I}(s_{t}) is 1 when the agent is in s_t at time t, 0 otherwise.
The left part corresponds to the transition dynamics: which states will be visited by the policy, discounted by \gamma.
The right part corresponds to the immediate reward in each visited state.
Couldn’t we learn the transition dynamics and the reward distribution separately in a model-free manner?
Successor Representations (SR)
SR rewrites the value of a state into an expected discounted future state occupancyM^\pi(s, s') and an expected immediate rewardr(s') by summing over all possible states s' of the MDP:
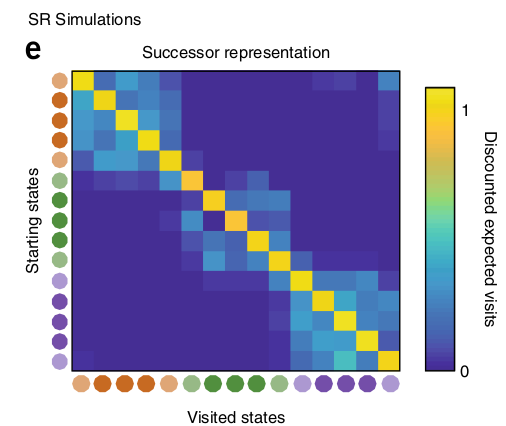
What matters is the states that you will visit and how interesting they are, not the order in which you visit them.
Knowing that being in the mensa will eventually get you some food is enough to know that being in the mensa is a good state: you do not need to remember which exact sequence of transitions will put food in your mouth.
Successor Representations (SR)
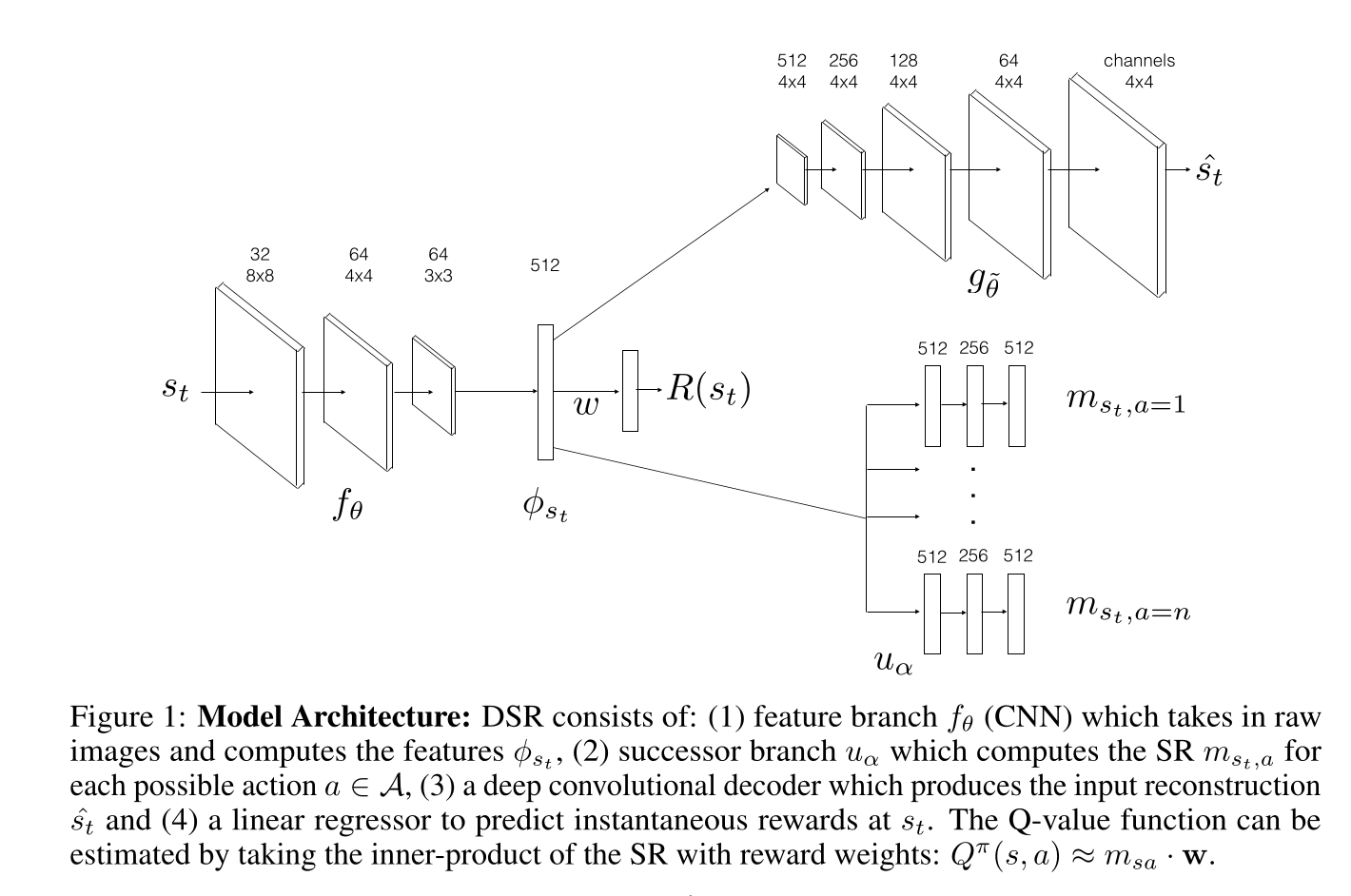
SR algorithms must estimate two quantities:
The expected immediate reward received after each state:
r(s) = \mathbb{E} [r_{t+1} | s_t = s]
The expected discounted future state occupancy (the SR itself):
This is reminiscent of TDM: the remaining distance to the goal is 0 if I am already at the goal, or gamma the distance from the next state to the goal.
Instead of predicting when the agent will see a cat after being in the current state s, the SFR predicts when it will see eyes, ears or whiskers independently:
The interesting property is that you do not need rewards to learn:
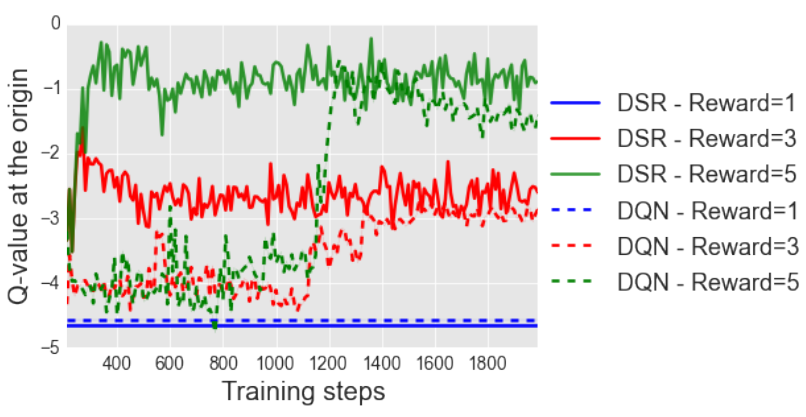
A random agent can be used to learn the encoder and the SR, but \mathbf{w} can be left untouched.
When rewards are introduced (or changed), only \mathbf{w} has to be adapted, while DQN would have to re-learn all Q-values.
This is the principle of latent learning in animal psychology: fooling around in an environment without a goal allows to learn the structure of the world, what can speed up learning when a task is introduced.
The SR is a cognitive map of the environment: learning task-unspecific relationships.
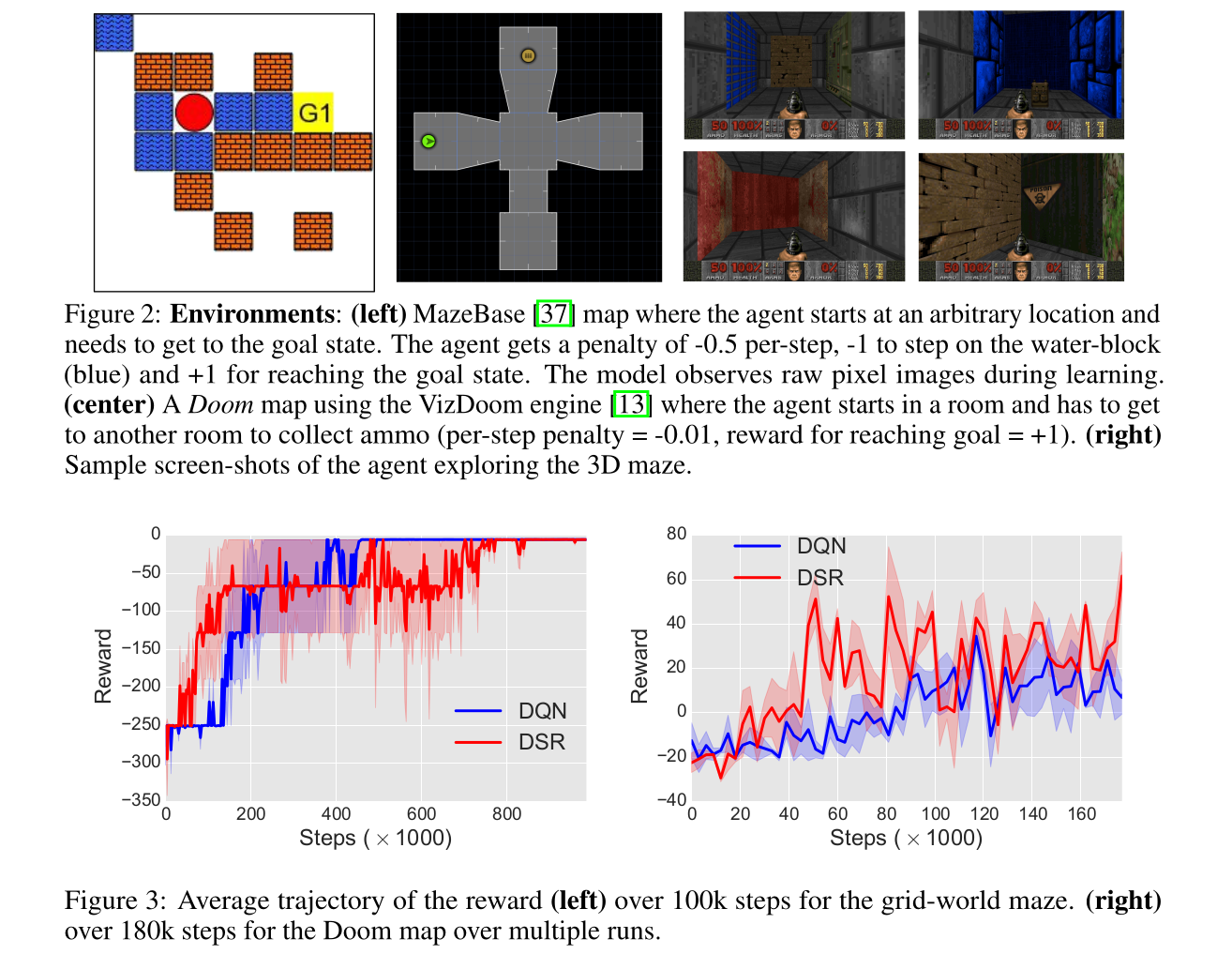
Visual Semantic Planning using Deep Successor Representations
References
Dayan, P. (1993). Improving Generalization for Temporal Difference Learning: The Successor Representation. Neural Computation 5, 613–624. doi:10.1162/neco.1993.5.4.613.
Kulkarni, T. D., Saeedi, A., Gautam, S., and Gershman, S. J. (2016). Deep Successor Reinforcement Learning. http://arxiv.org/abs/1606.02396.
Momennejad, I., Russek, E. M., Cheong, J. H., Botvinick, M. M., Daw, N. D., and Gershman, S. J. (2017). The successor representation in human reinforcement learning. Nature Human Behaviour 1, 680–692. doi:10.1038/s41562-017-0180-8.
Russek, E. M., Momennejad, I., Botvinick, M. M., Gershman, S. J., and Daw, N. D. (2017). Predictive representations can link model-based reinforcement learning to model-free mechanisms. PLOS Computational Biology 13, e1005768. doi:10.1371/journal.pcbi.1005768.
Stachenfeld, K. L., Botvinick, M. M., and Gershman, S. J. (2017). The hippocampus as a predictive map. Nature Neuroscience 20, 1643–1653. doi:10.1038/nn.4650.
Zhu, Y., Gordon, D., Kolve, E., Fox, D., Fei-Fei, L., Gupta, A., et al. (2017). Visual Semantic Planning using Deep Successor Representations. http://arxiv.org/abs/1705.08080.