Neurocomputing
Introduction
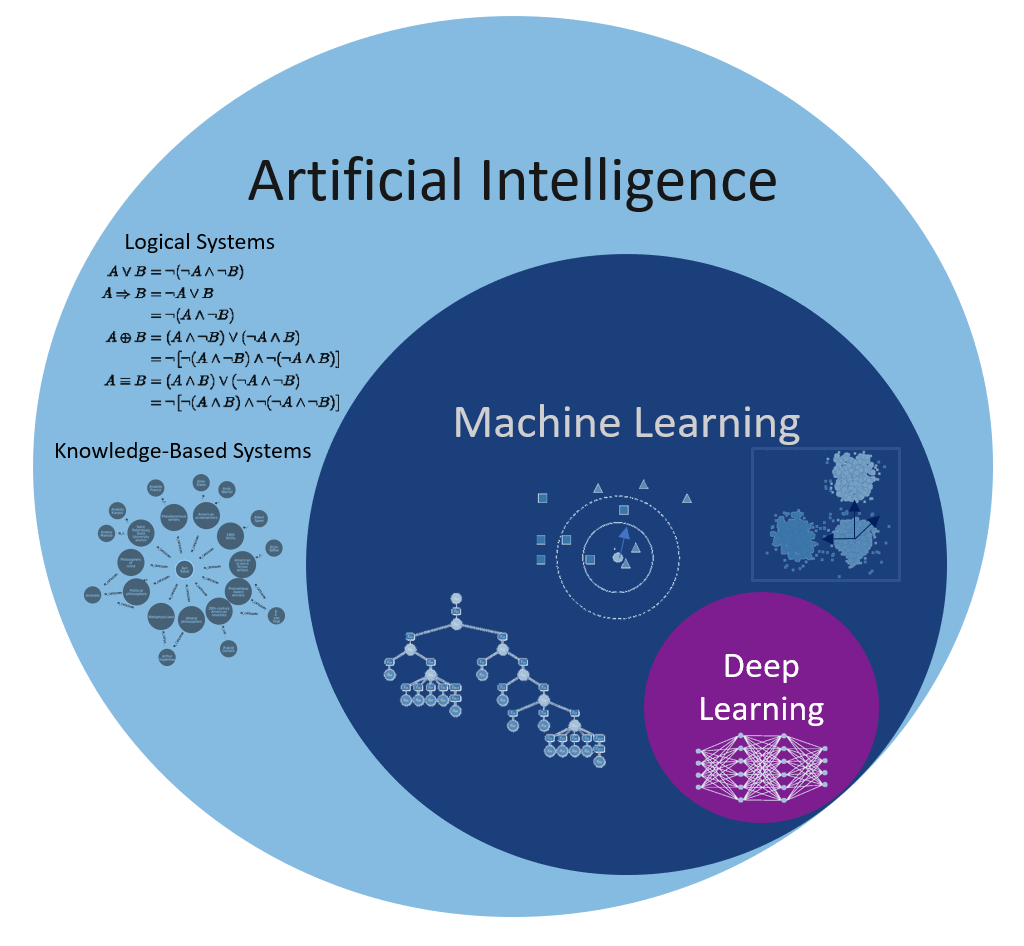
Artificial Intelligence, Machine Learning, Deep Learning, Neurocomputing
- The term Artificial Intelligence was coined by John McCarthy at the Dartmouth Summer Research Project on Artificial Intelligence in 1956.
The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.
Good old-fashion AI approaches (GOFAI) were purely symbolic (logical systems, knowledge-based systems) or using linear neural networks.
They were able to play checkers, prove mathematical theorems, make simple conversations (ELIZA), translate languages…
Artificial Intelligence, Machine Learning, Deep Learning, Neurocomputing
Machine learning (ML) is a branch of AI that focuses on learning from examples (data-driven).
ML algorithms include:
Neural Networks (multi-layer perceptrons)
Statistical analysis (Bayesian modeling, PCA)
Clustering algorithms (k-means, GMM, spectral clustering)
Support vector machines
Decision trees, random forests
Other names: big data, data science, operational research, pattern recognition…
Artificial Intelligence, Machine Learning, Deep Learning, Neurocomputing
Deep Learning is a recent re-branding of neural networks.
Deep learning focuses on learning high-level representations of the data, using:
Deep neural networks (DNN)
Convolutional neural networks (CNN)
Recurrent neural networks (RNN)
Generative models (GAN, VAE)
Deep reinforcement learning (DQN, PPO, AlphaGo)
Transformers
Graph neural networks
Artificial Intelligence, Machine Learning, Deep Learning, Neurocomputing

Neurocomputing is at the intersection between computational neuroscience and artificial neural networks (deep learning).
Computational neuroscience studies the functioning of the brain through detailed models.
Neurocomputing aims at bringing the mechanisms underlying human cognition into artificial intelligence.
AI hypes and AI winters

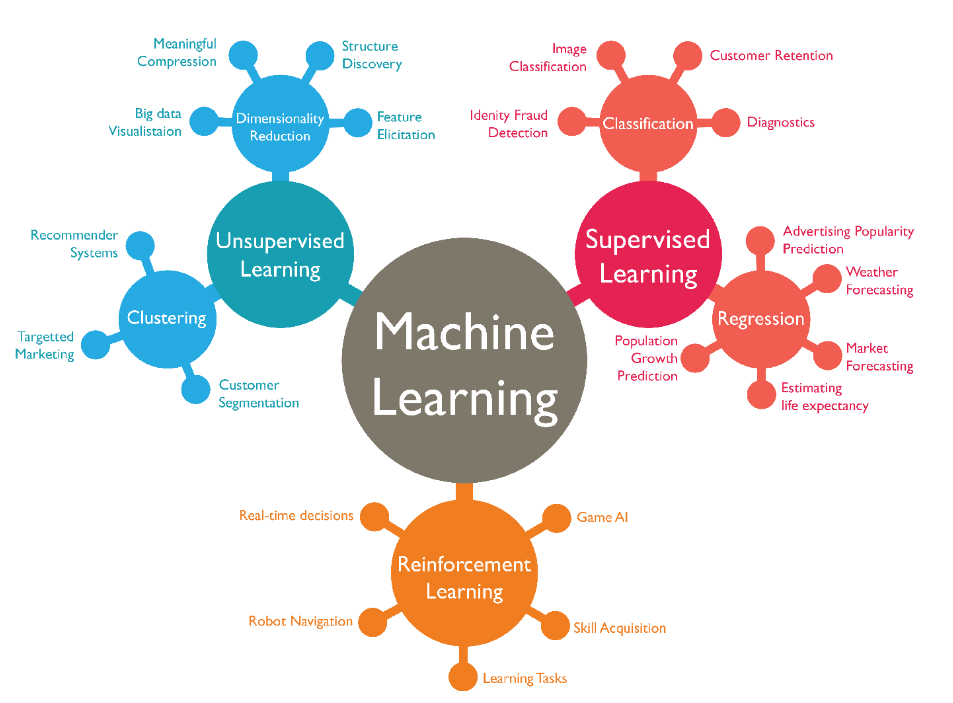
Classification of ML techniques
Supervised learning: The program is trained on a pre-defined set of training examples and used to make correct predictions when given new data.
Unsupervised learning: The program is given a bunch of data and must find patterns and relationships therein.
Reinforcement learning: The program explores its environment by producing actions and receiving rewards.
But also:
- Self-supervised learning, self-taught learning, developmental learning…
Supervised Learning
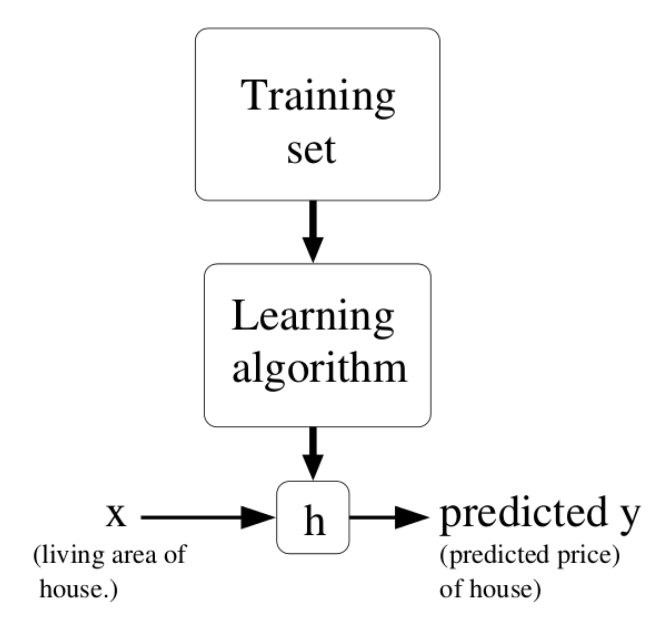
- Supervised learning consists in presenting a dataset of input and output samples (or examples) (x_i, t_i)_{i=1}^N to a parameterized model.
y_i = f_\theta(x_i)
- The goal of learning is to adapt the parameters \theta, so that the model reduces its prediction error on the training data.
\theta^* = \text{argmin} \sum_{i=1}^N || t_i - y_i||
When learning is successful, the model can be used on novel examples (generalisation).
The modality of the inputs and outputs does not really matter:
- Image \rightarrow Label : image classification
- Image \rightarrow Image : semantic segmentation
- Speech \rightarrow Text : speech recognition
- Text \rightarrow Speech : speech synthesis
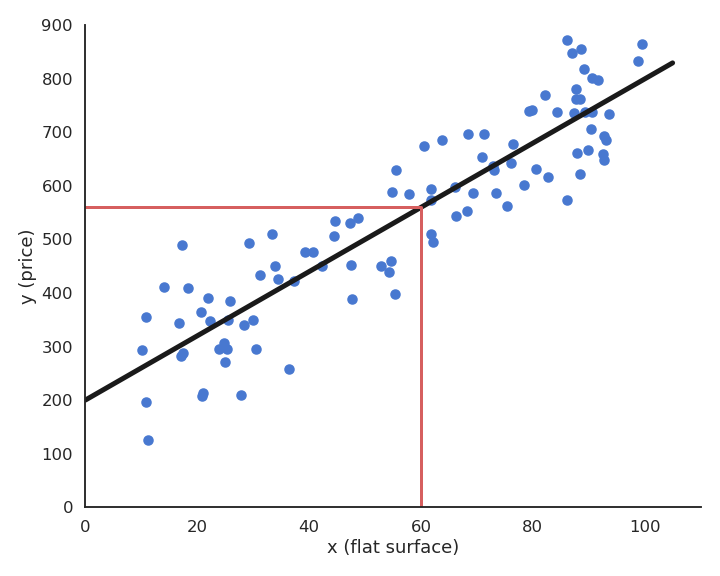
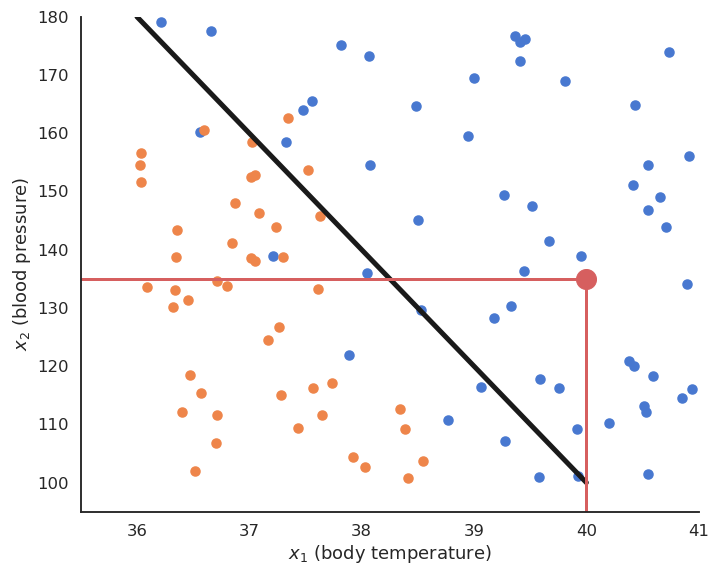
Supervised learning : regression
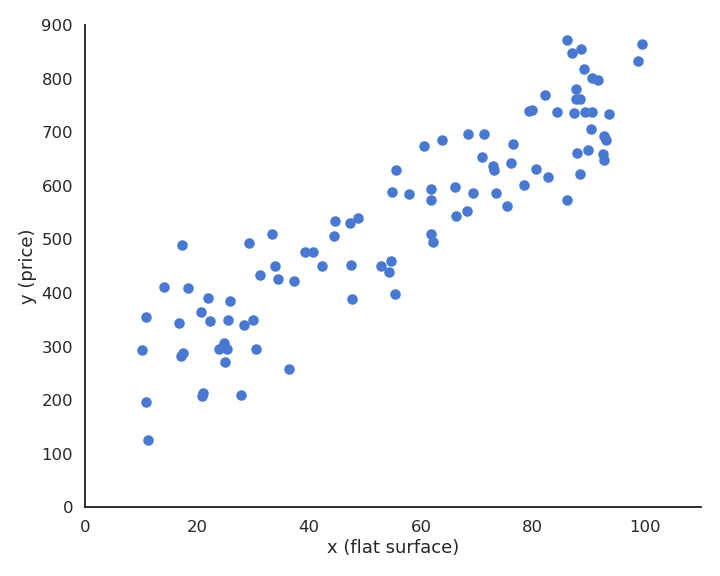
Supervised learning : regression
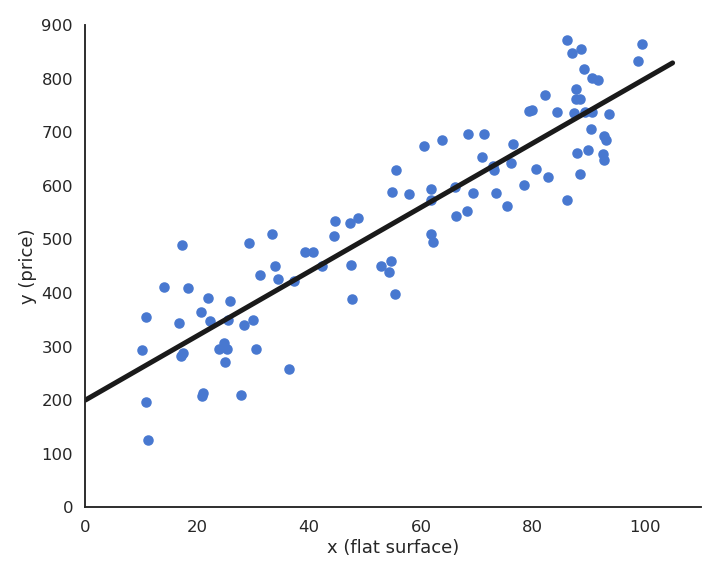
Supervised learning : regression
Supervised learning : classification
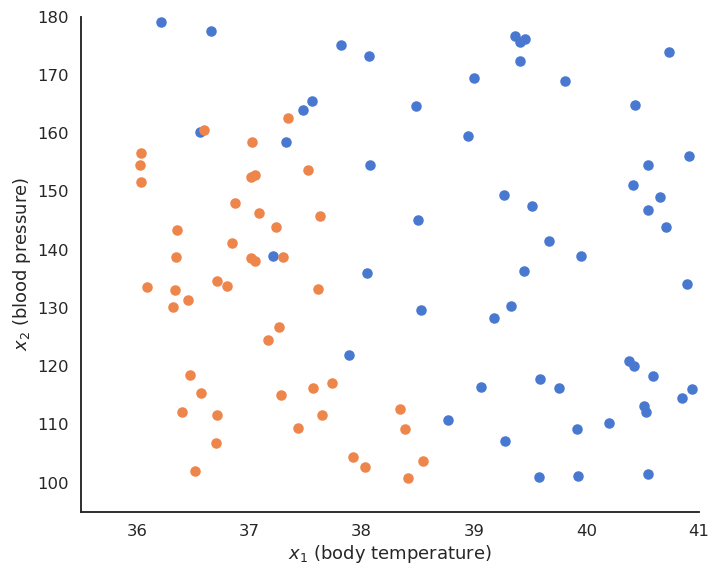
Supervised learning : classification
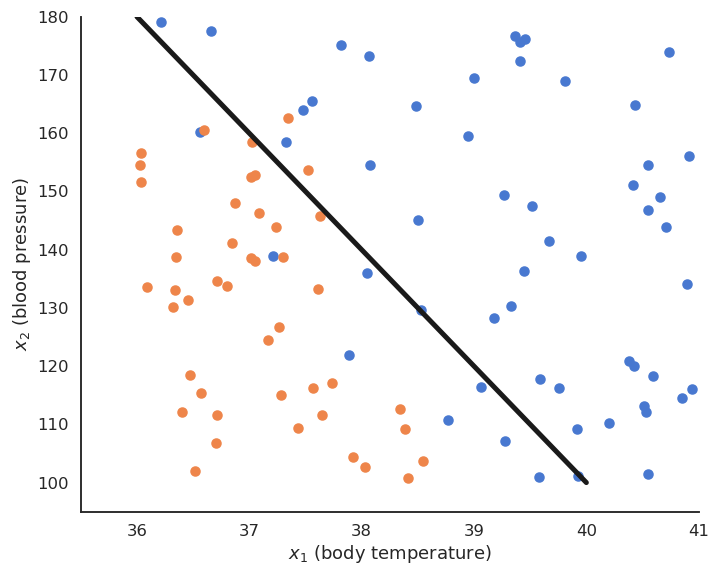
Supervised learning : classification
The artificial neuron
- A single artificial neuron is able to solve linear classification/regression problems:

y = f( \sum_{i=1}^d w_i \, x_i + b)
- A neuron integrates inputs x_i by multiplying them with weights w_i, adds a bias b and transforms the result into an output y using a transfer function (or activation function) f.
Artificial Neural Network
- A neural network (NN) is able to solve non-linear classification/regression problems by combining many artificial neurons.

Classical approach to pattern recognition
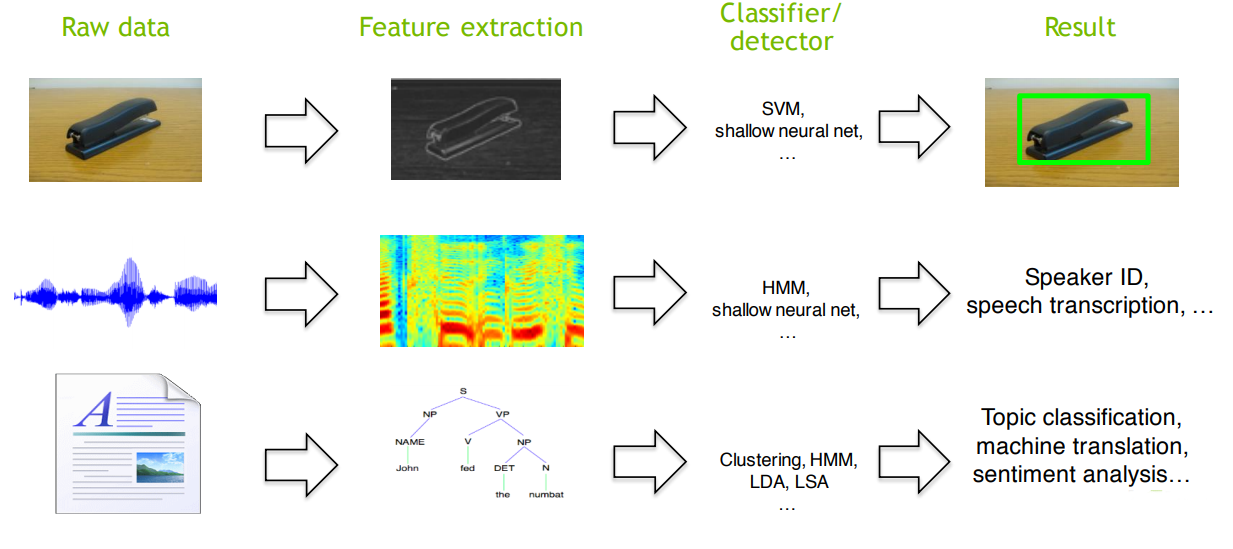
Deep Learning approach to pattern recognition
- End-to-end learning: the NN is trained directly on the raw data (pixels, sounds, text) and solves a non-linear classification/regression problem.
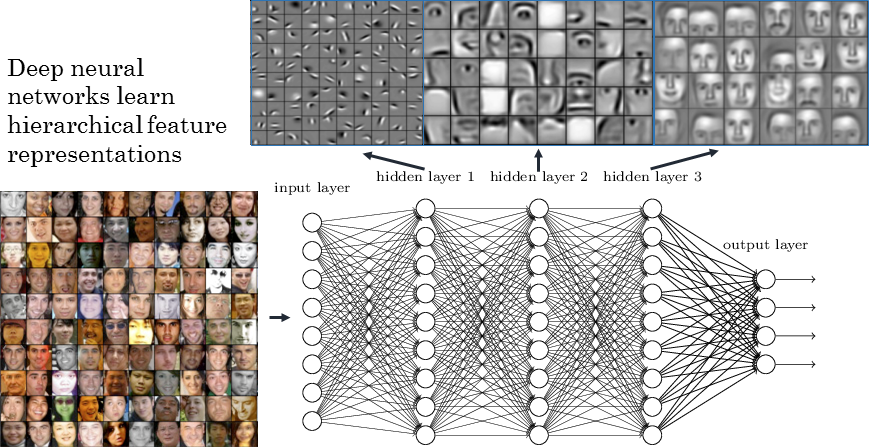
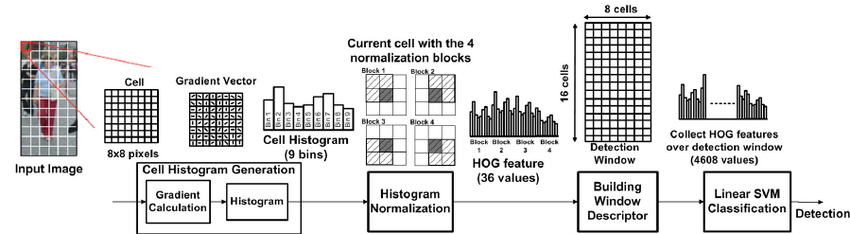
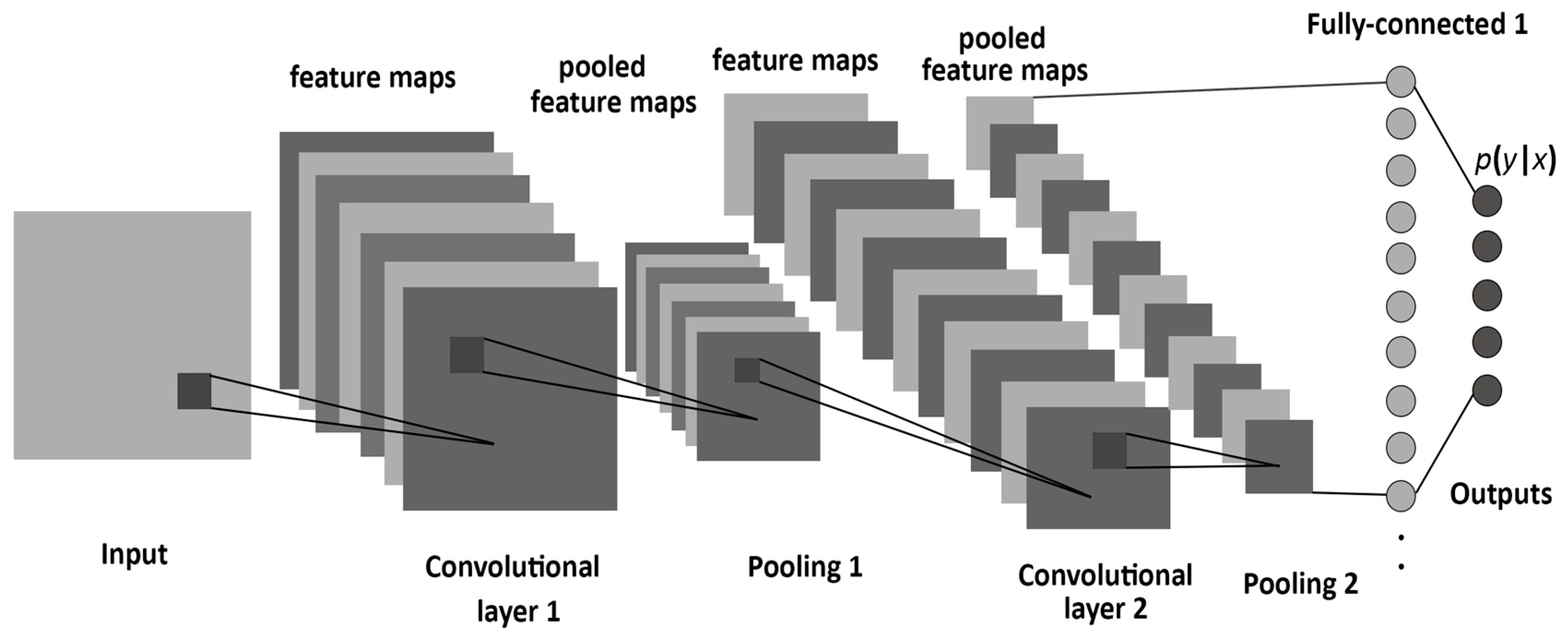
Convolutional neural networks
A convolutional neural network (CNN) is a cascade of convolution and pooling operations, extracting layer by layer increasingly complex features.
It can be trained on huge datasets of annotated examples.
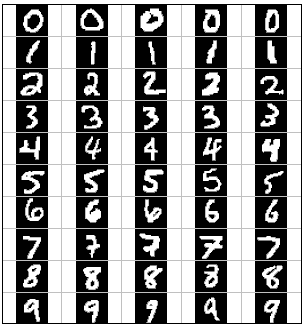
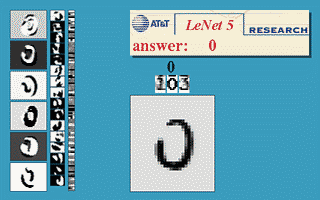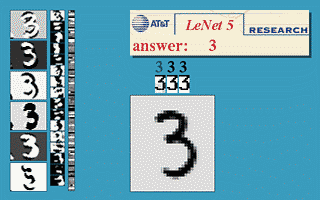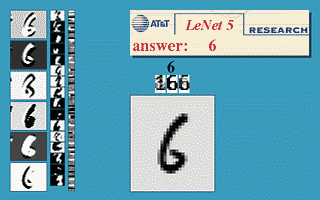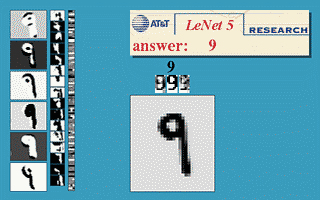
Handwriting recognition
The MNIST database is the simplest benchmark for object recognition (> 99.5 %).
One of the early functional CNN was LeNet5, able to classify digits.
ImageNet recognition challenge
- The ImageNet challenge was a benchmark for computer vision algorithms, providing millions of annotated images for object recognition, detection and segmentation.
Object recognition

Object detection

Object segmentation

AlexNet
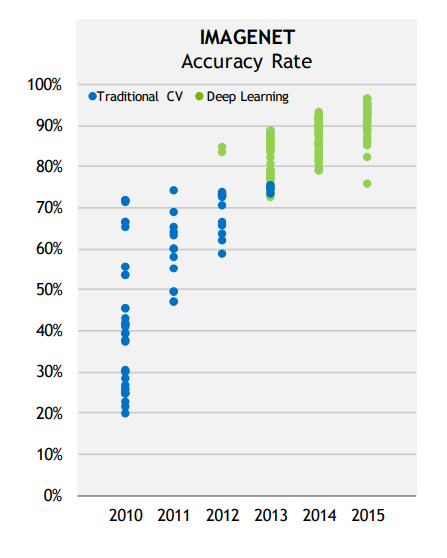
Classical computer vision methods obtained moderate results, with error rates around 30%.
In 2012, Alex Krizhevsky, Ilya Sutskever and Geoffrey E. Hinton (Uni Toronto) used a CNN (AlexNet) without any preprocessing, using directly images as inputs.
To the big surprise of everybody, they won with an error rate of 15%, half of what other methods could achieve.
Since then, everybody uses deep neural networks for object recognition.
The deep learning hype had just begun…
Computer vision
Natural language processing
Speech processing
Robotics, control
Object detection

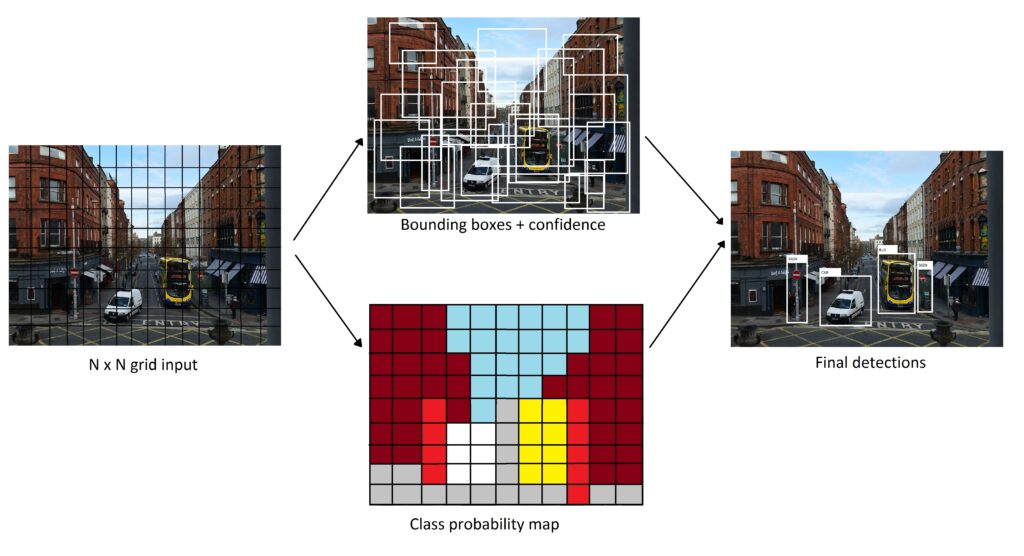
Object detection
It turns out object detection is both a classification (what) and regression (where) problem.
Neural networks can be trained to do it given enough annotated data.
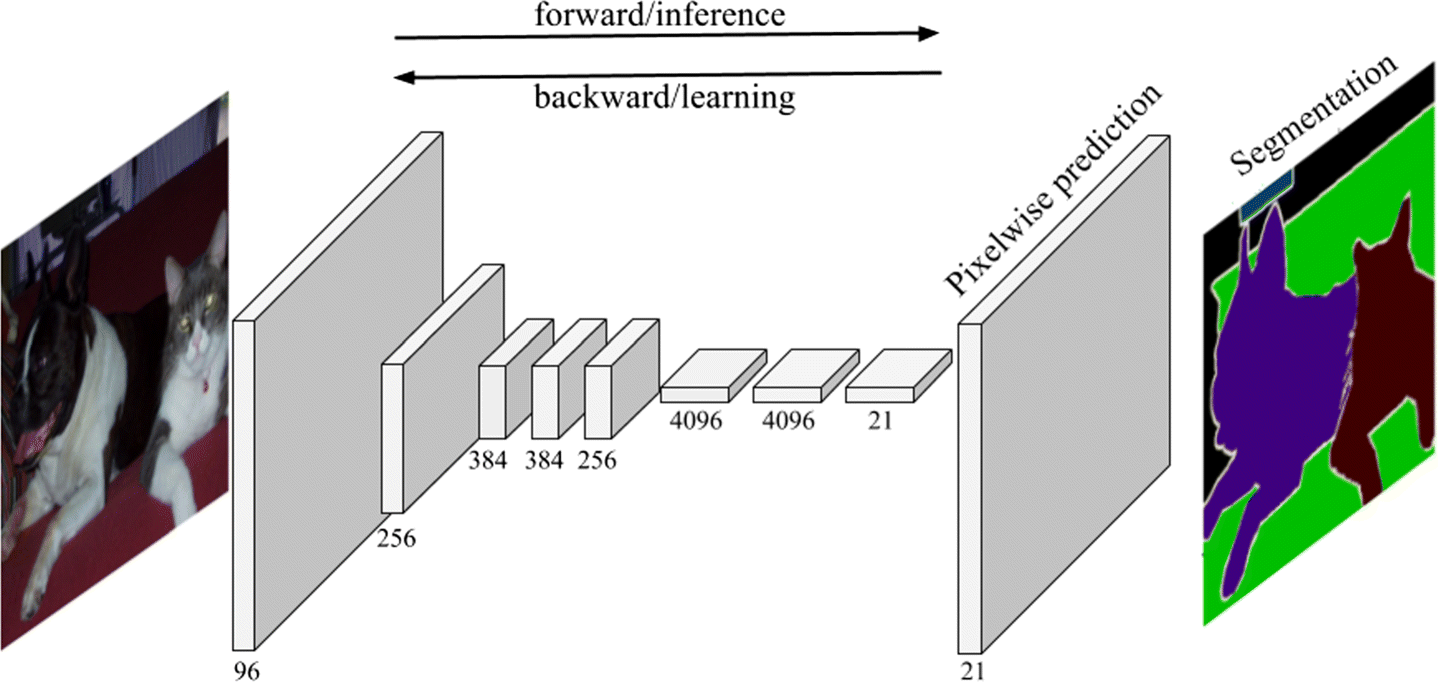
Semantic segmentation
- Classes can be predicted at the pixel level, allowing semantic segmentation.
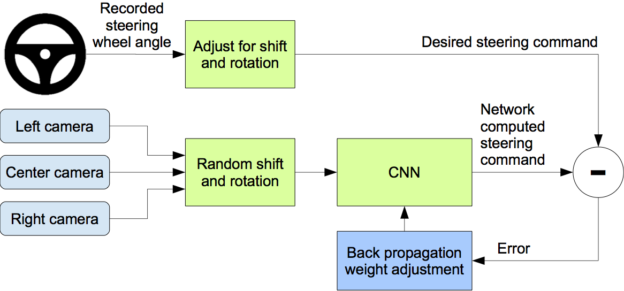
Dave2 : NVIDIA’s self-driving car
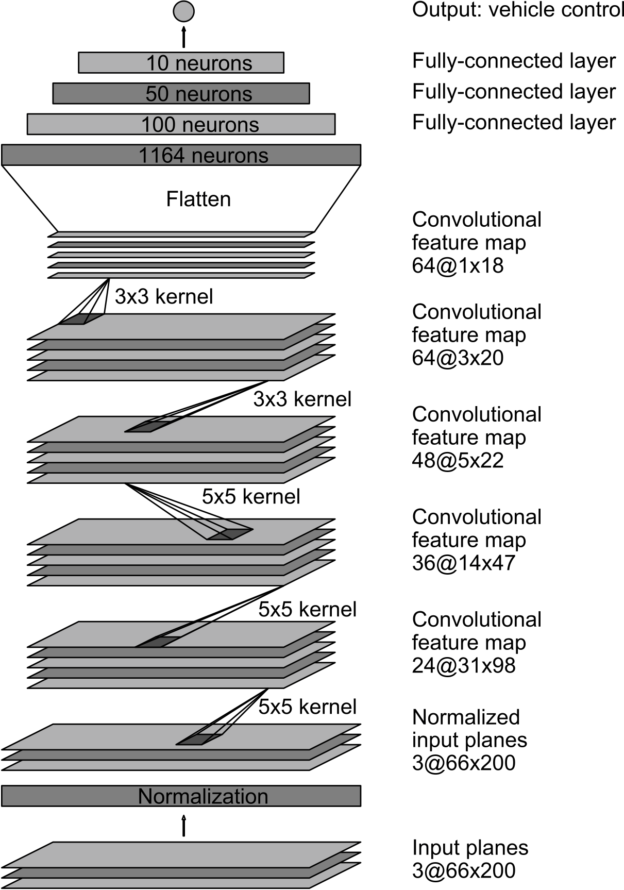
NVIDIA trained a CNN to reproduce wheel steerings from experienced drivers using only a front camera.
After training, the CNN took control of the car.
Facial recognition

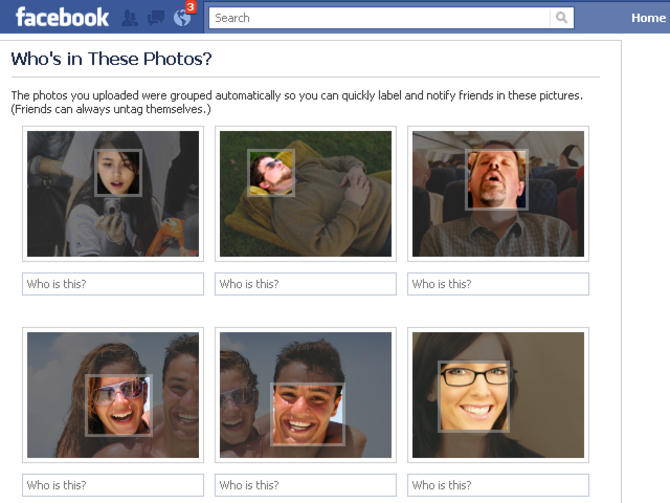
Facebook used 4.4 million annotated faces from 4030 users to train DeepFace.
Accuracy of 97.35% for recognizing faces, on par with humans.
Used now to recognize new faces from single examples (transfer learning, one-shot learning).
Recurrent neural networks

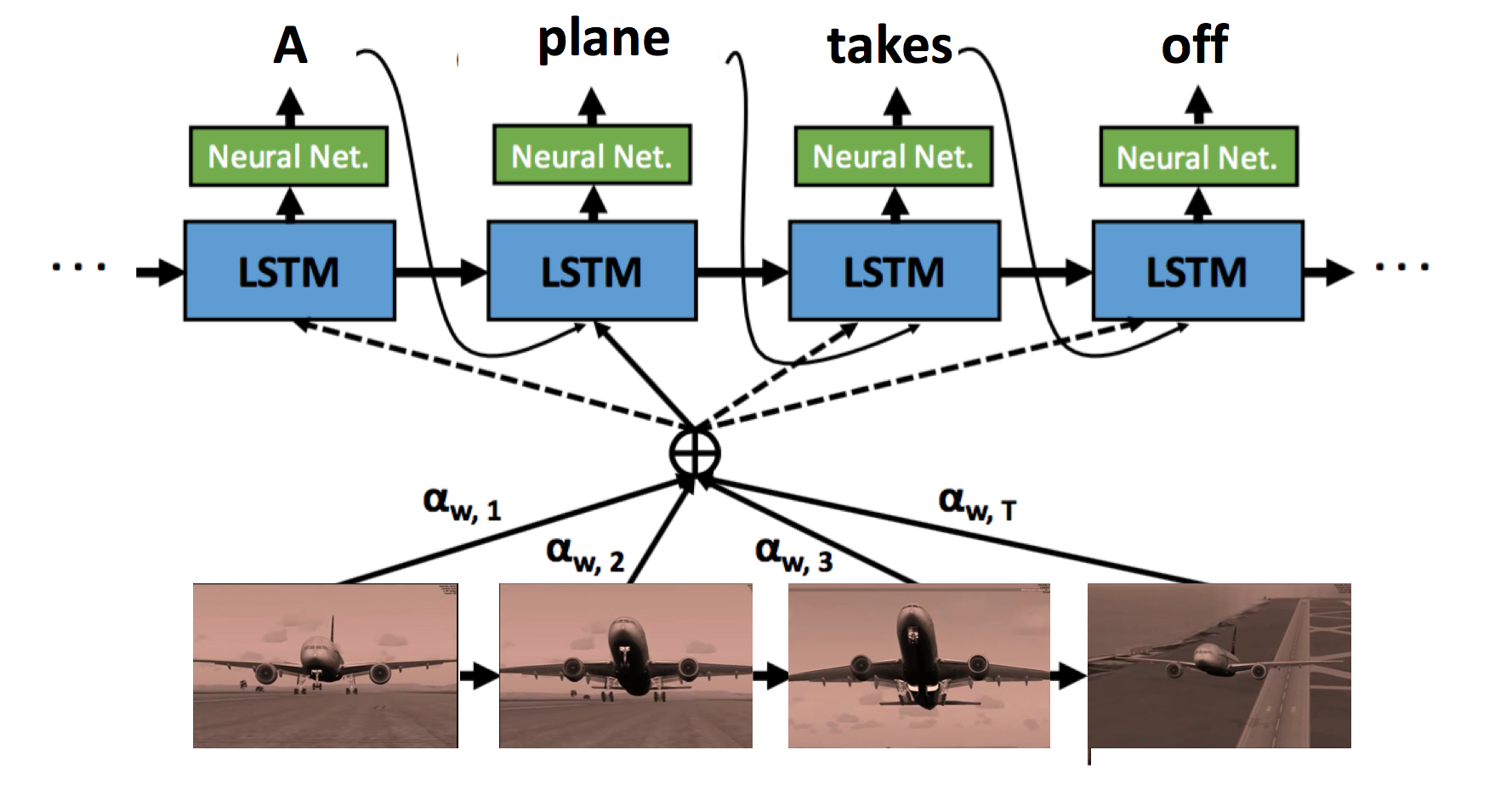
A recurrent neural network (RNN) uses it previous output as an additional input (context).
The inputs are integrated over time to deliver a response at the correct moment.
This allows to deal with time series (texts, videos) without increasing the input dimensions.
The input to the RNN can even be the output of a pre-trained CNN.
The most efficient RNN is called LSTM (Long short-term memory networks) (Hochreiter and Schmidhuber, 1997).
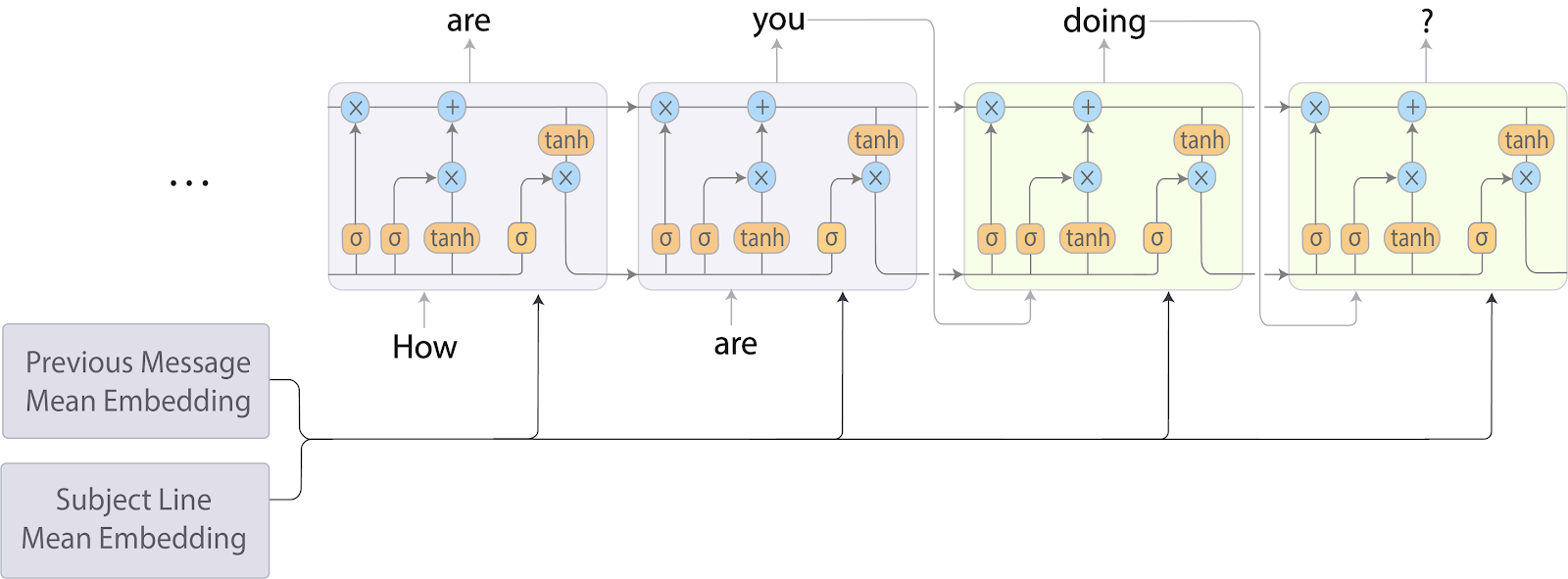
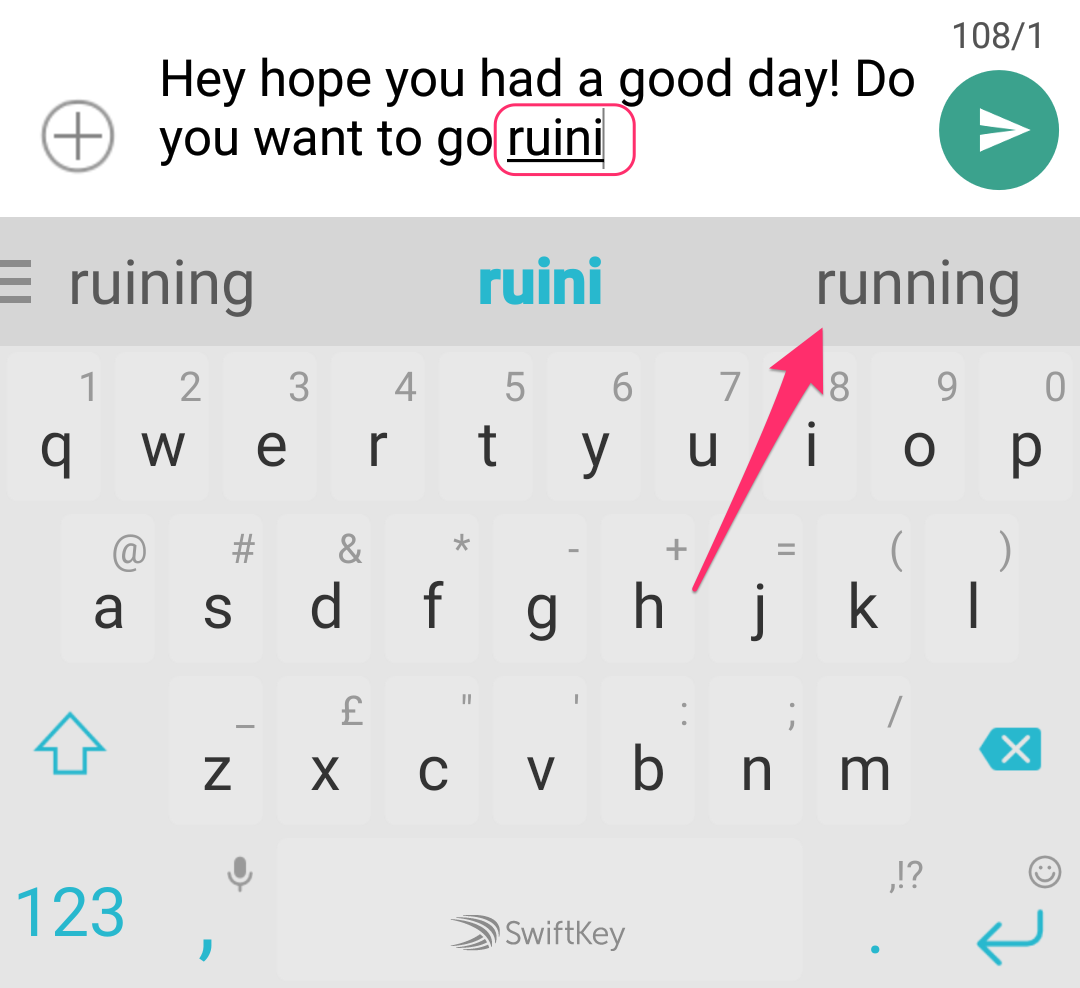
Natural Language Processing : Automatic word/sentence completion
Natural Language Processing : text translation
![]()
![]()
Two LSTM can be stacked to perform sequence-to-sequence translation (seq2seq).
One is the encoder, the other the decoder.
Natural Language Processing : Google Neural Machine Translation
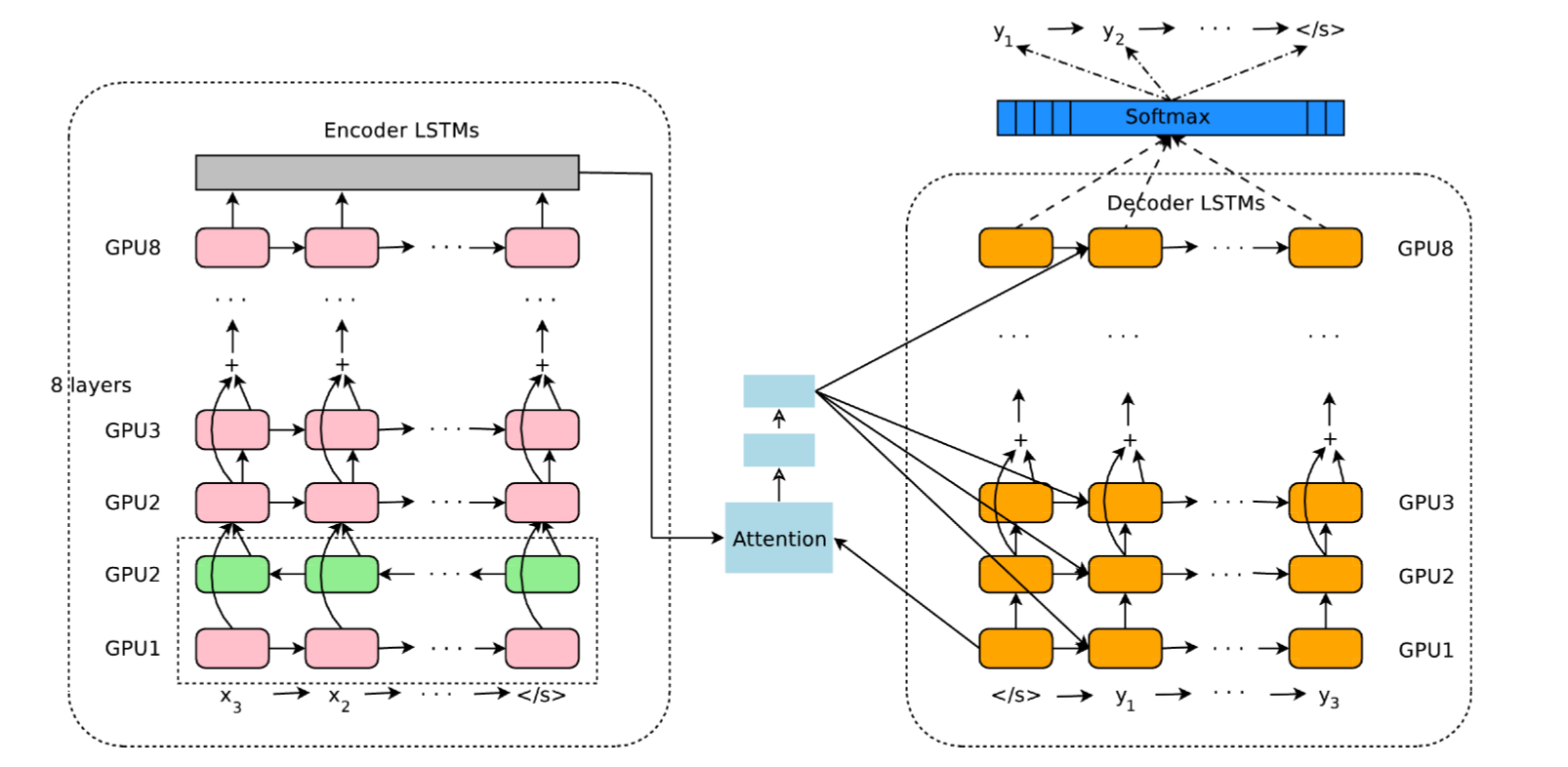
Same idea, but with much more layers…
Can translate any pair of languages!
Transformers
GPT - Generative Pre-trained Transformer
- GPT can be fine-tuned (transfer learning) to perform machine translation.
GPT - Generative Pre-trained Transformer
- GPT can be fine-tuned to summarize Wikipedia articles.
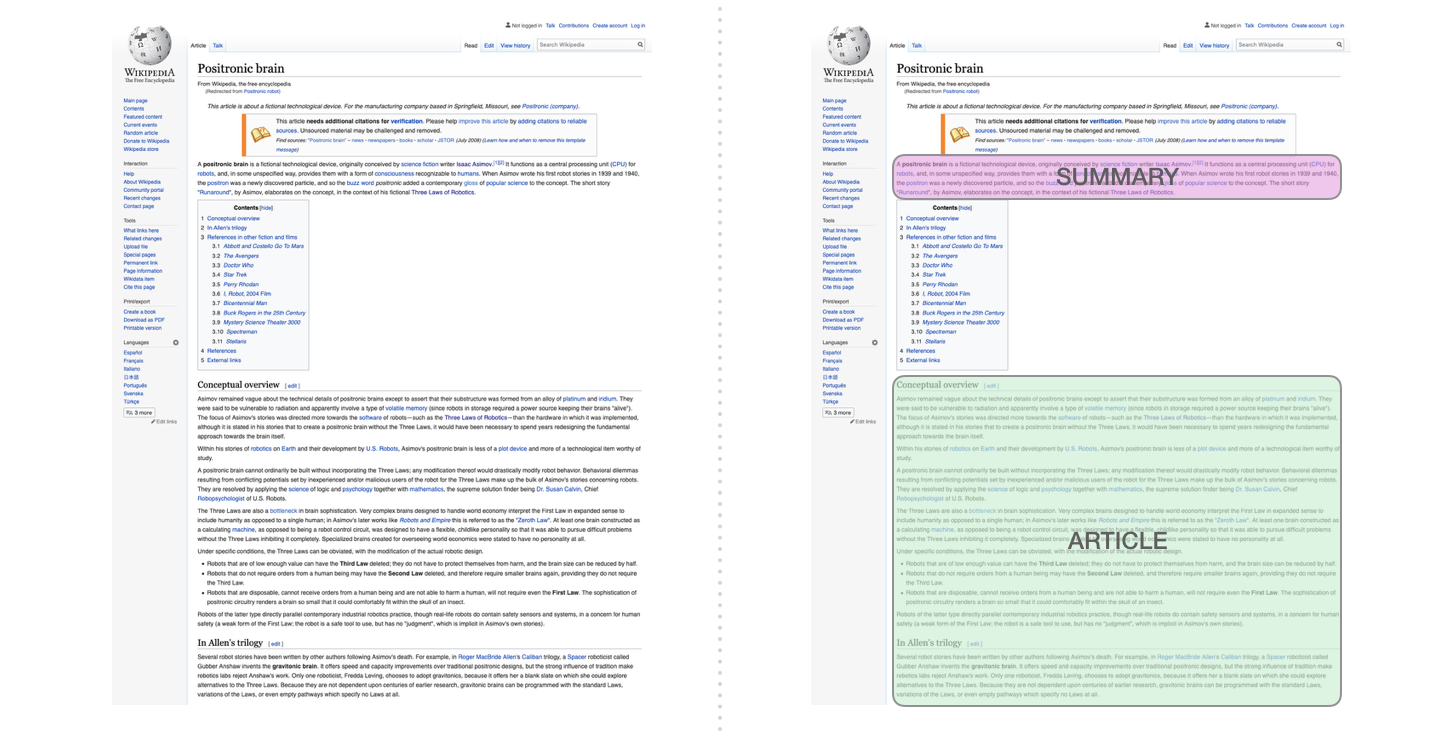
Try transformers at https://huggingface.co/
pip install transformers![]()
Github copilot
Github and OpenAI trained a GPT-3-like architecture on the available open source code.
Copilot is able to “autocomplete” the code based on a simple comment/docstring.
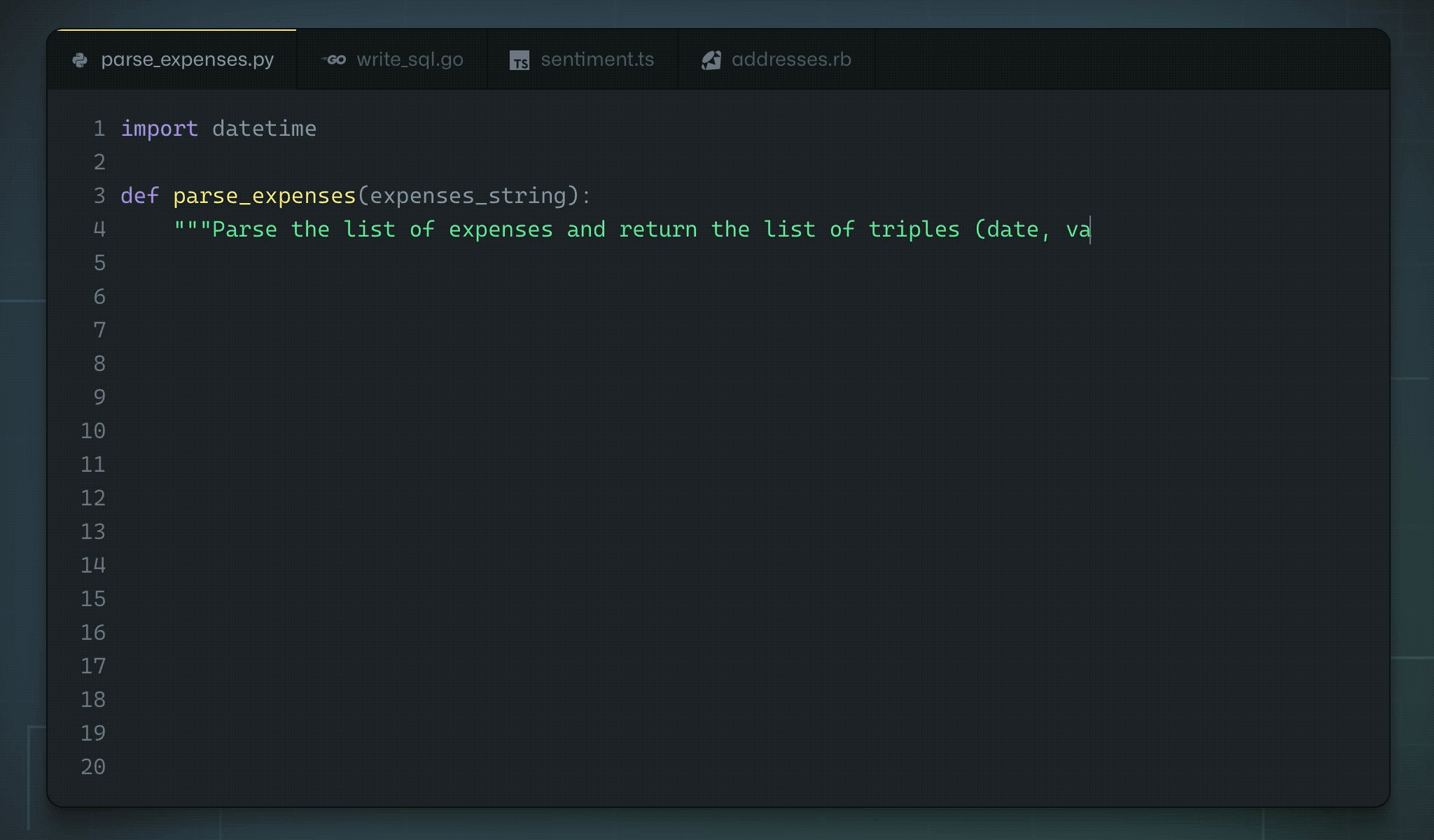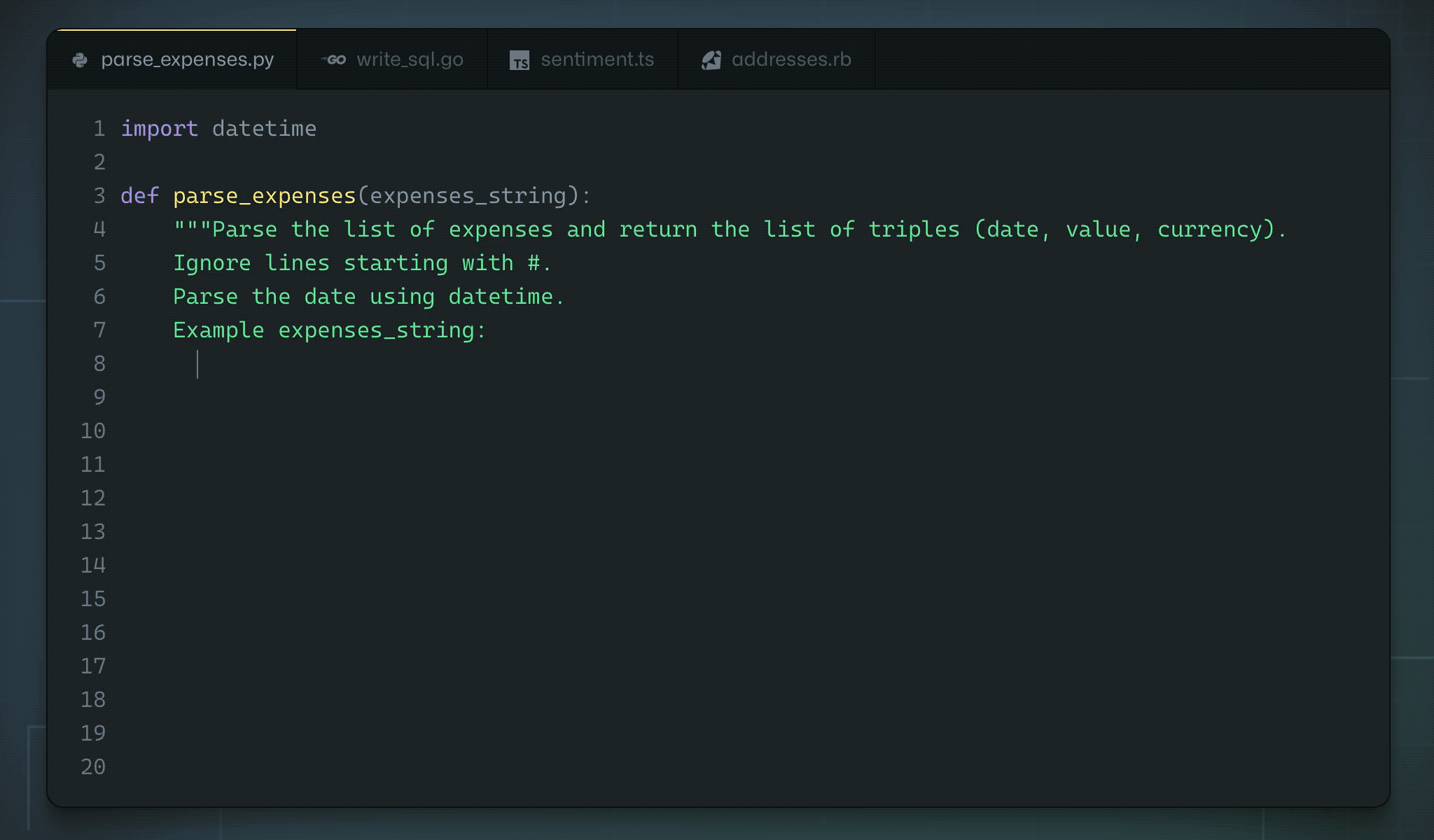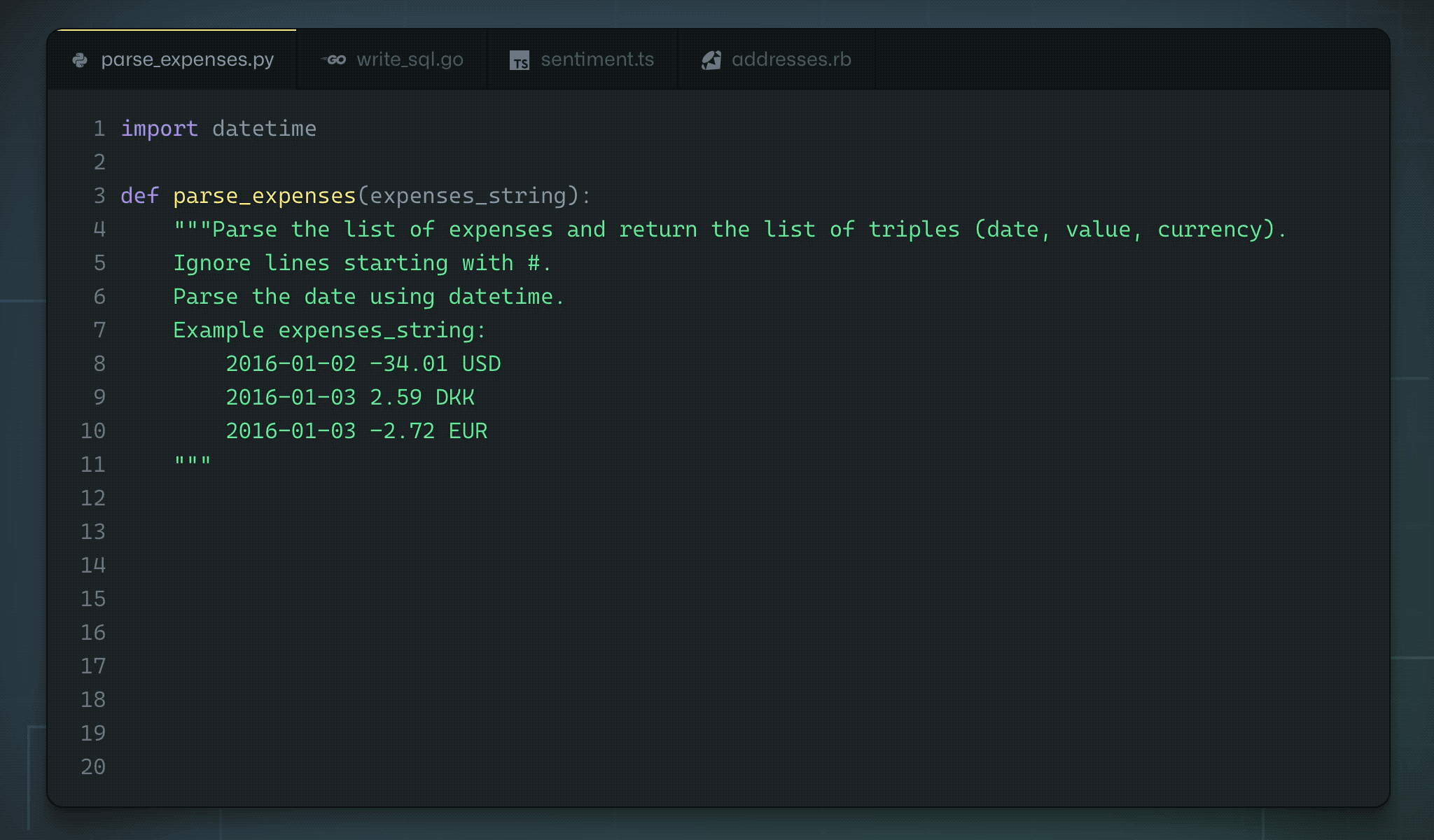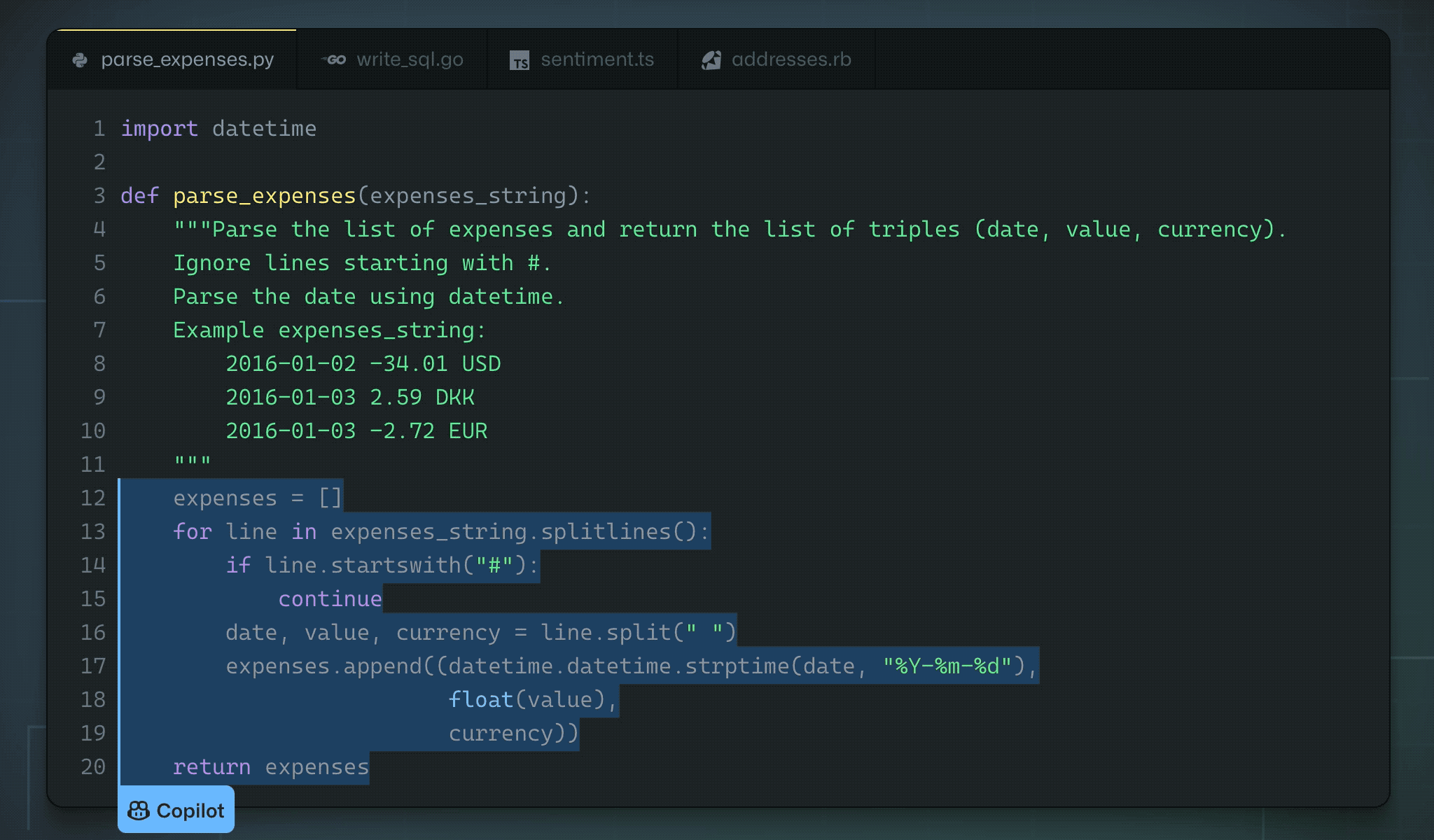
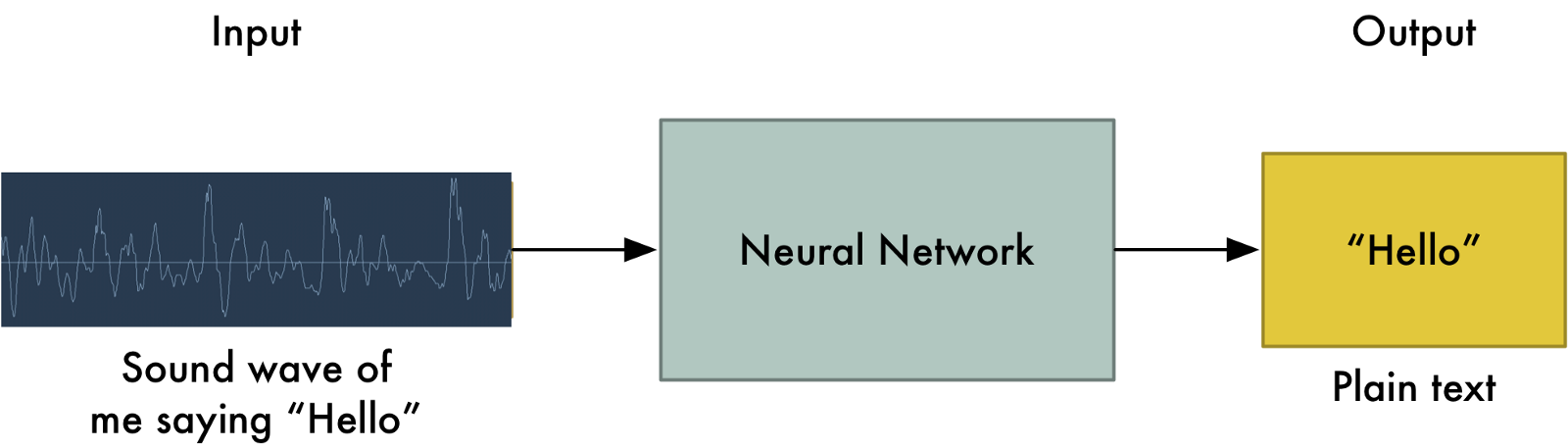
Voice recognition
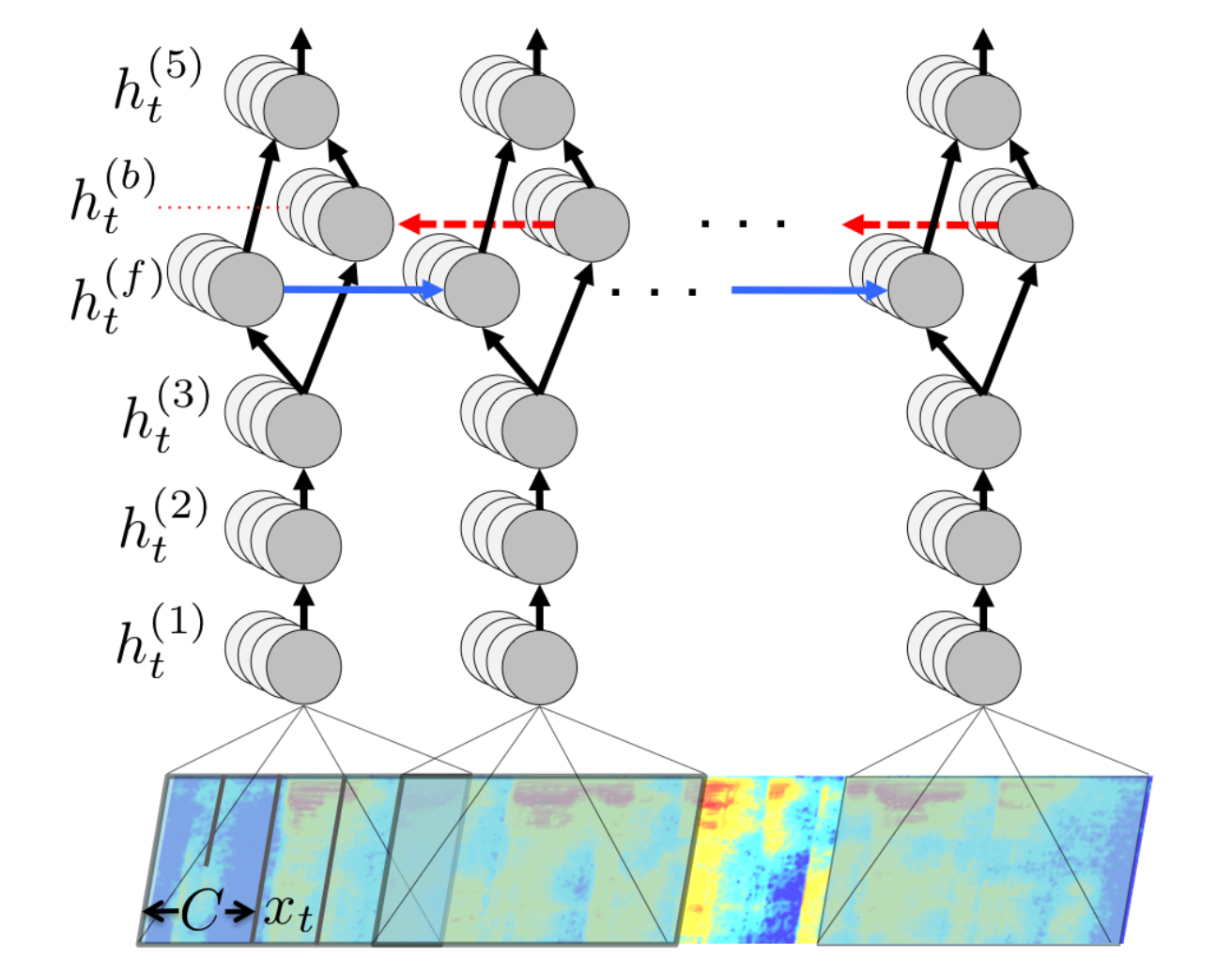
CNNs are not limited to images, voice signals can also be recognized using their mel-spectrum.
Siri, Alexa, Google now, etc. use recurrent CNNs to recognize vocal commands and respond.
DeepSpeech from Baidu is one of the state-of-the-art approach.
Unsupervised learning
- In unsupervised learning, only raw input data is provided to the algorithm, which has to analyze the statistical properties of the data.
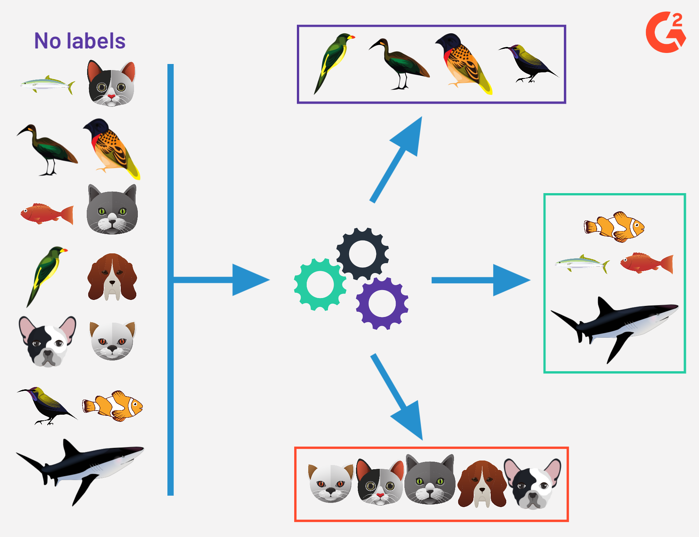
The goal of unsupervised learning is to build a model or find useful representations of the data, for example:
finding groups of similar data and model their density (clustering).
reduce the redundancy of the input dimensions (dimensionality reduction).
finding good explanations / representations of the data (latent data modeling).
generate new data (generative models).
Clustering: learning topologies in film preferences
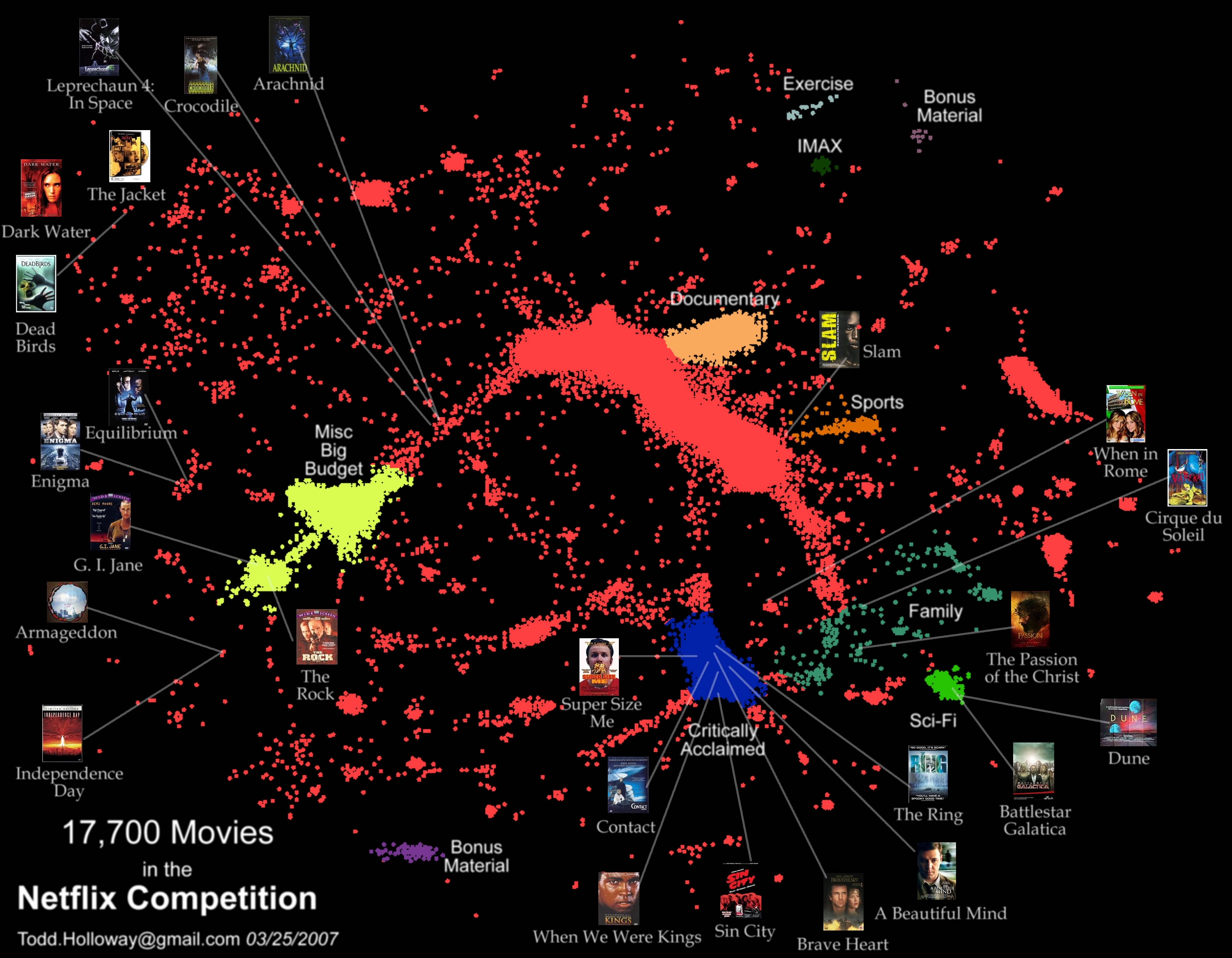
Dimensionality reduction: finding the right latent space
Images have a lot of dimensions (pixels), most of which are redundant.
Dimensionality reduction techniques allow to reduce this number of dimensions by projecting the data into a latent space.
Autoencoders are NN that learn to reproduce their inputs by compressing information through a bottleneck.
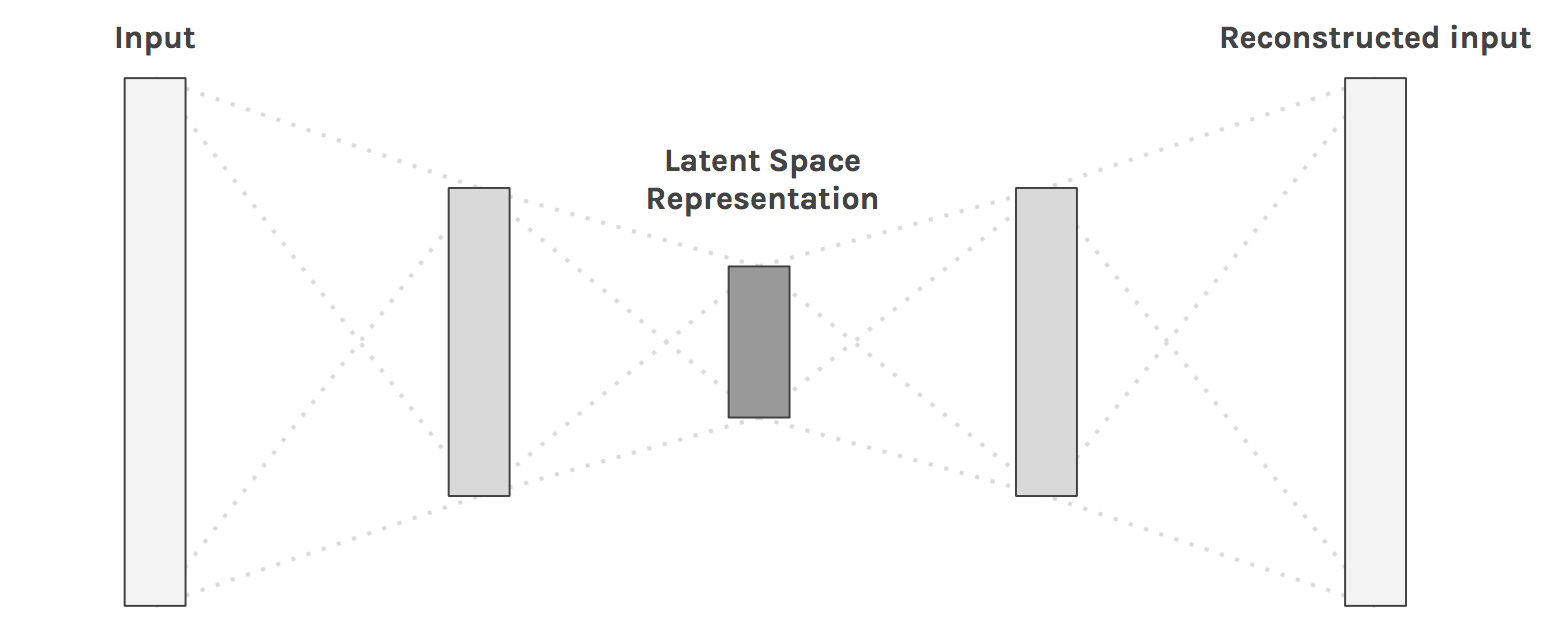
Dimensionality reduction: visualization
- If the latent space has two or three dimensions, you can use dimensionality reduction to visualize your data.

Classical machine learning algorithms include PCA (principal component analysis) or t-SNE.
NN autoencoders can also be used for visualization, e.g. UMAP.
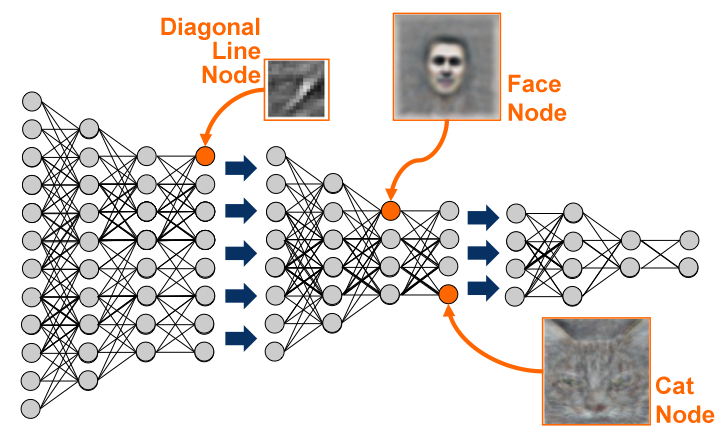
Feature extraction: self-taught learning
- Pretrain a neural network on huge unlabeled datasets (e.g. Youtube videos) before applying it to small-data supervised problems.
Generative models
- If the latent space is well organized, you can even sample from it to generate new images using variational autoencoders (VAE).


DeepFake
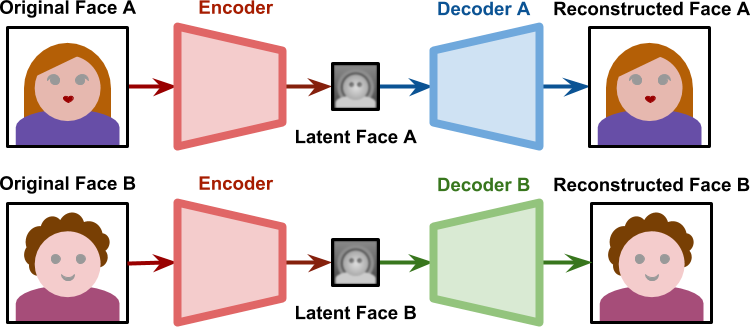
- During training, each autoencoder learns to reproduce the face of one person.
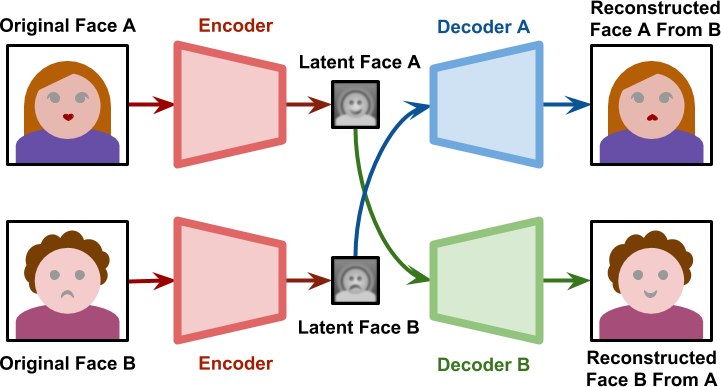
- When generating the deepfake, the decoder of person B is used on the encoder of person A.
Generative Adversarial Networks
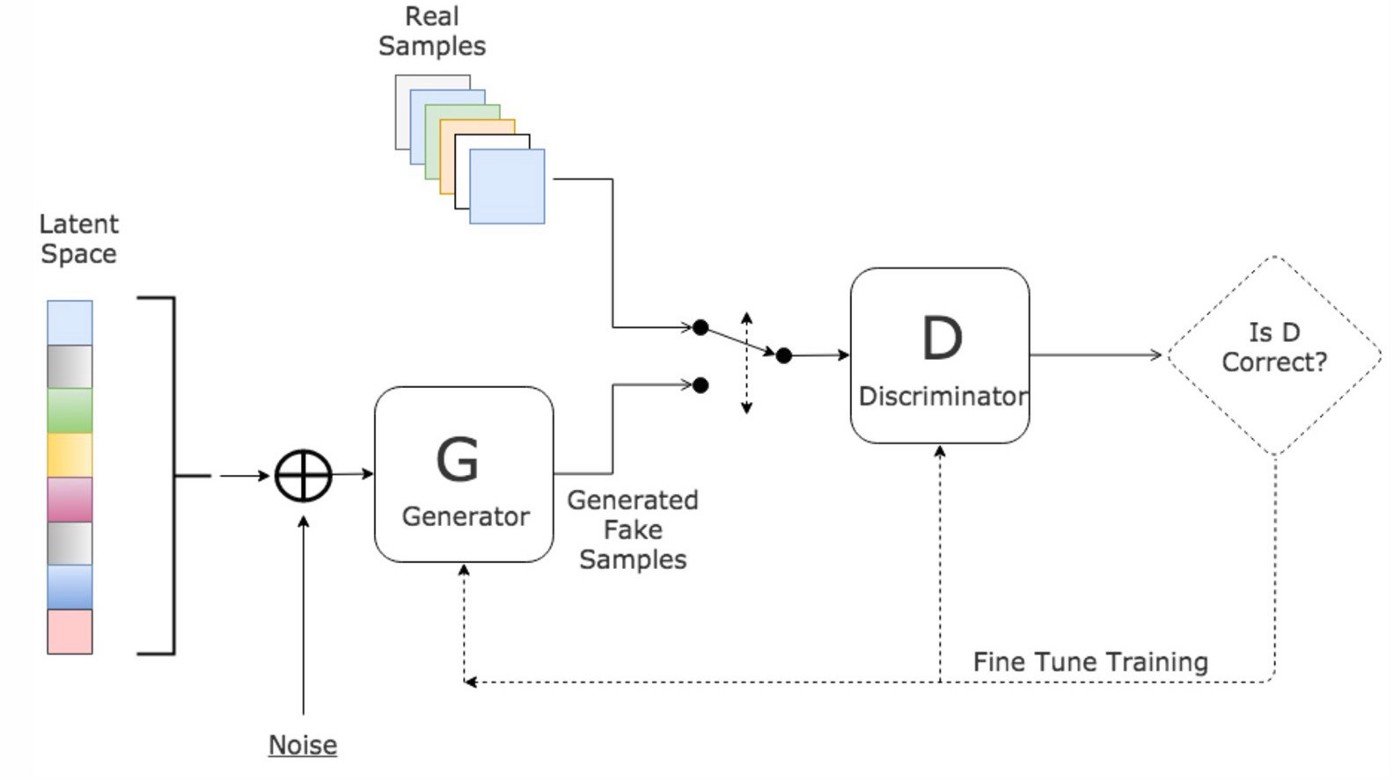
A Generative Adversarial Network (GAN) is composed of two networks:
The generator learns to produce realistic images.
The discriminator learn to differentiate real data from generated data.
Both compete to reach a Nash equilibrium:
\min_G \max_D \, V(D, G) = \mathbb{E}_{x \sim P_\text{data}(x)} [\log D(x)] + \mathbb{E}_{z \sim P_z(z)} [\log(1 - D(G(z)))]
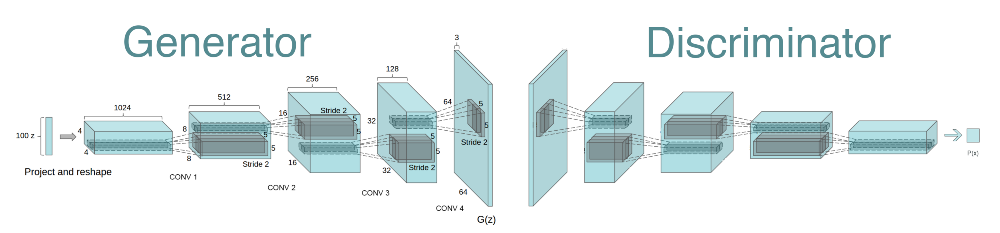
DCGAN : Deep convolutional GAN

cGAN : conditional GAN for image synthesis
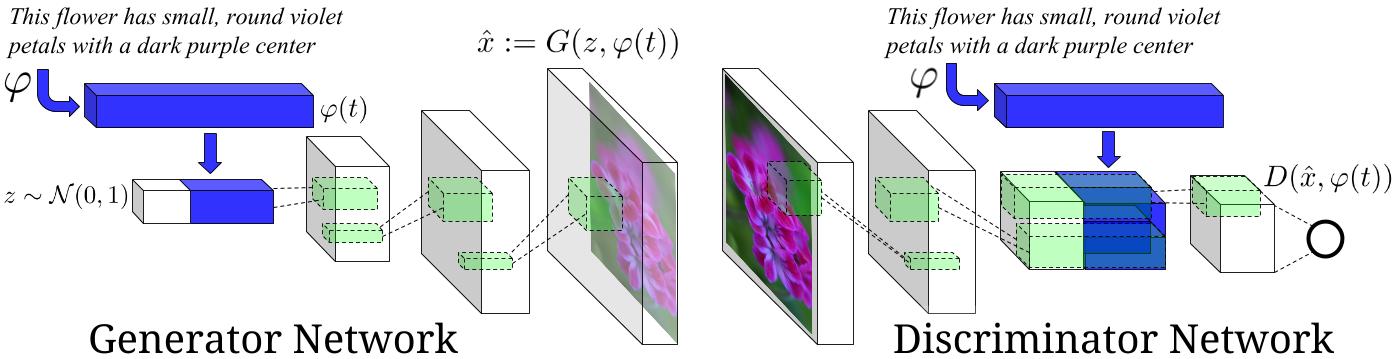

pix2pix : Image translation
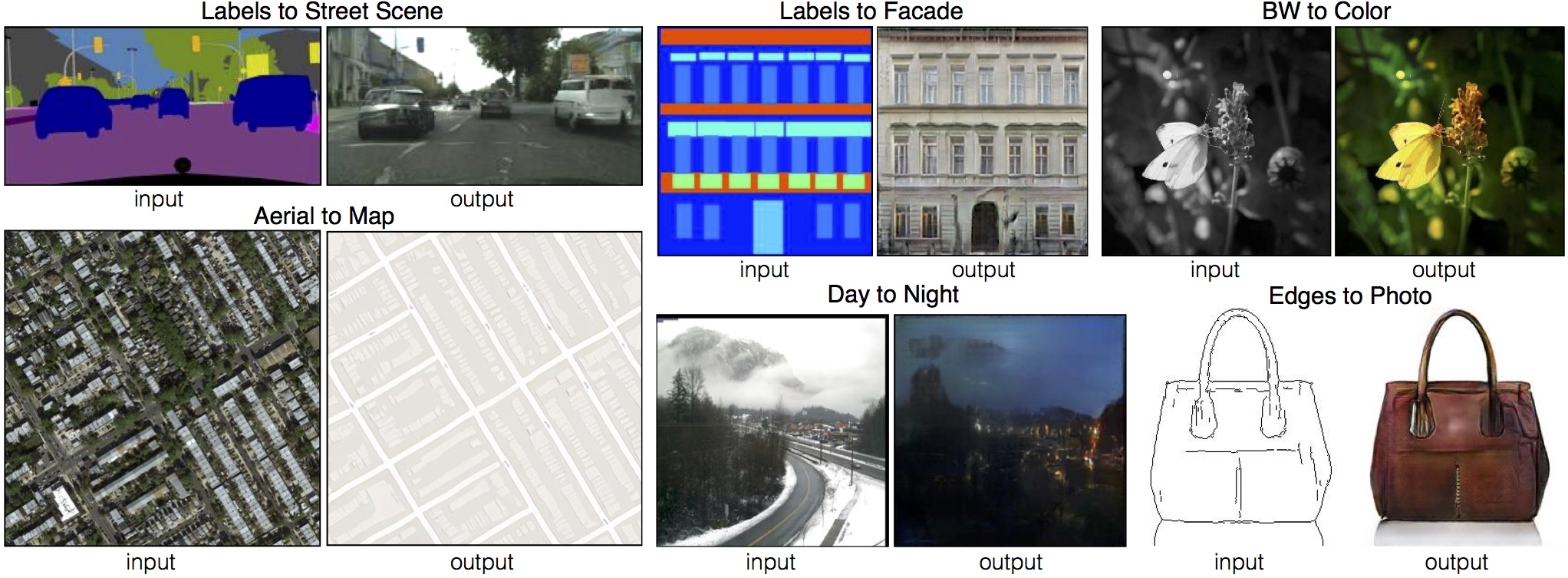
CycleGAN : Monet Paintings to Photo

CycleGAN : Neural Style Transfer

CycleGAN : Object Transfiguration

Reinforcement learning
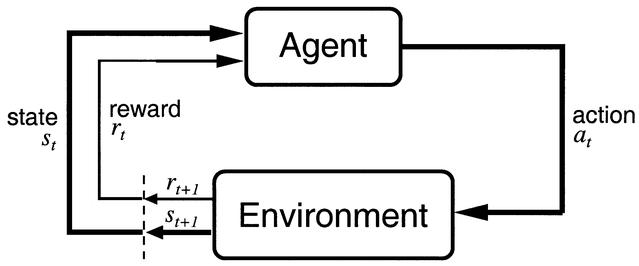
Supervised learning allows to learn complex input/output mappings, given there is enough data.
Sometimes we do not know the correct output, only whether the proposed output is correct or not (partial feedback).
Reinforcement Learning (RL) can be used to learn by trial and error an optimal policy \pi(s,a).
Each action (=output) is associated to a reward.
The goal of the system is to find a policy that maximizes the sum of the rewards on the long-term (return).
R(s_t, a_t) = \sum_{k=0}^\infty \gamma^k\, r_{t+k+1}
- See the deep reinforcement learning course:
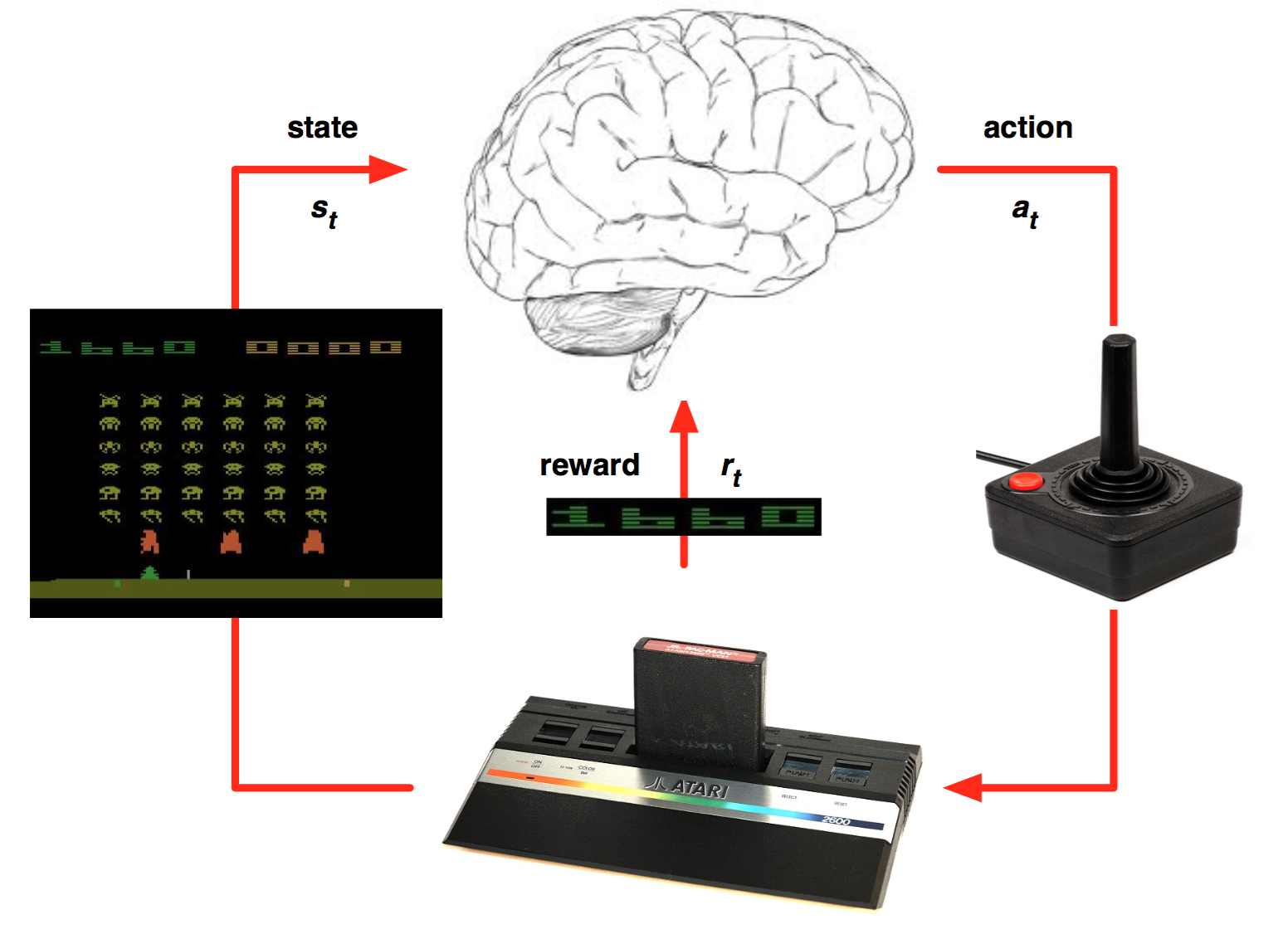
DQN : learning to play Atari games
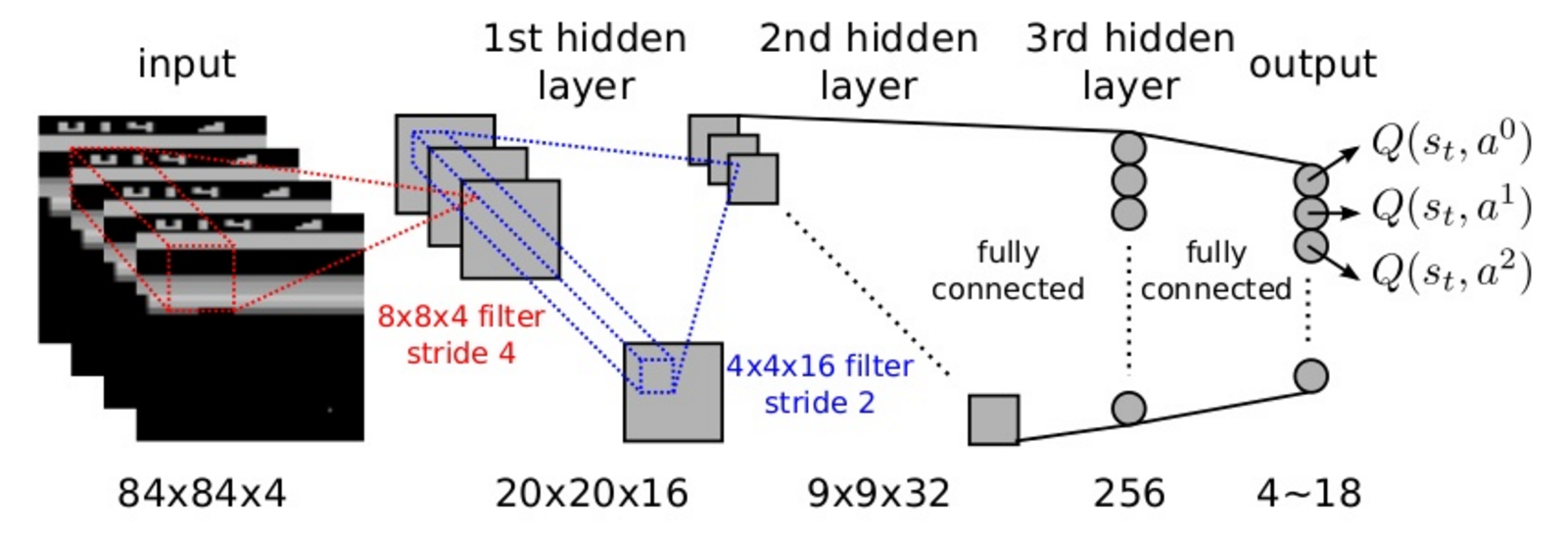
A CNN takes raw images as inputs and outputs the probabilities of taking particular actions.
Learning is only based on trial and error: what happens if I do that?
The goal is simply to maximize the final score.
AlphaStar : learning to play Starcraft II
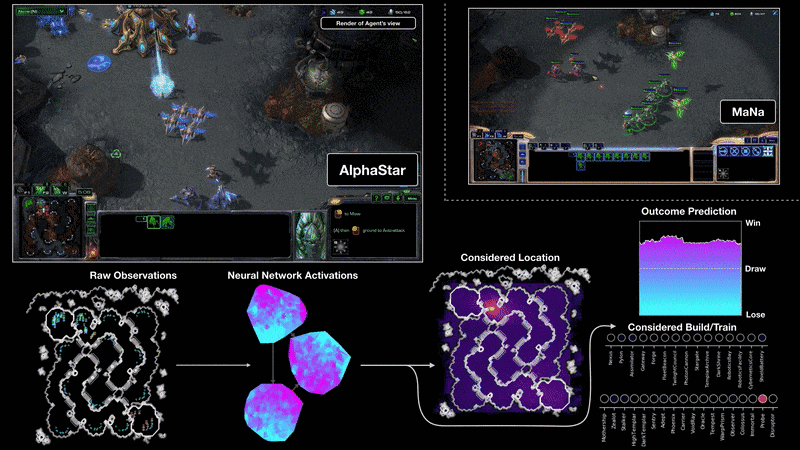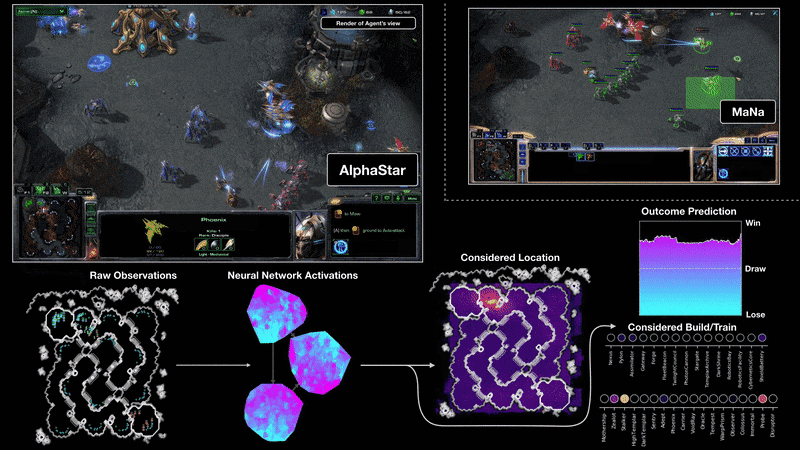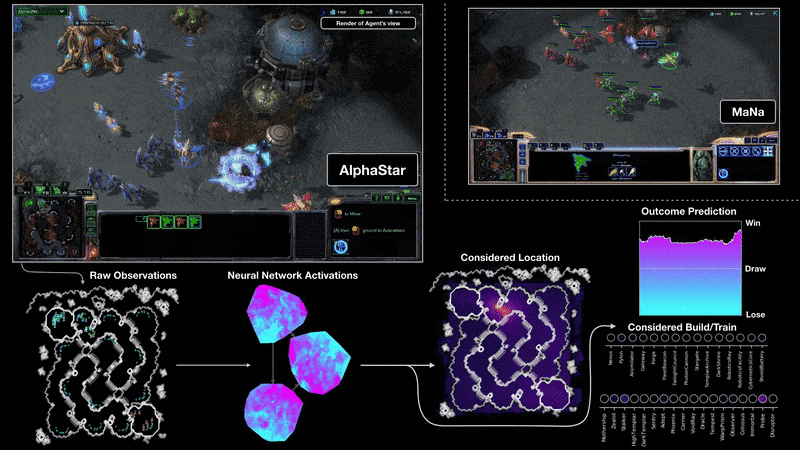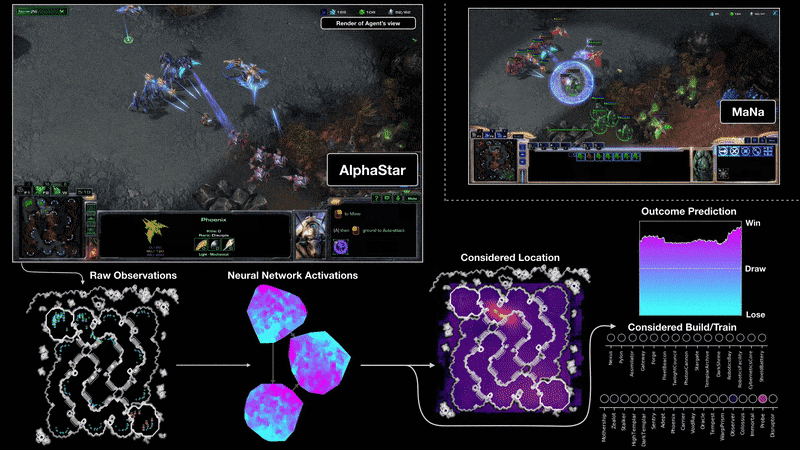
Google Deepmind - AlphaGo
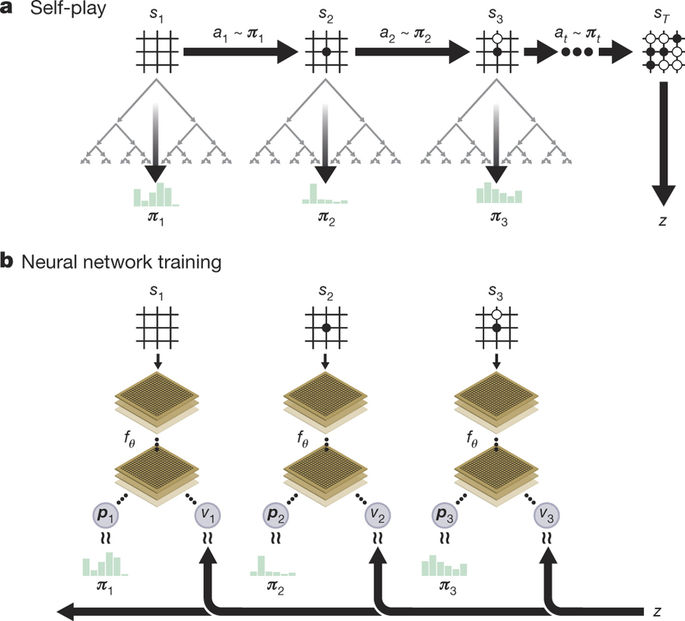
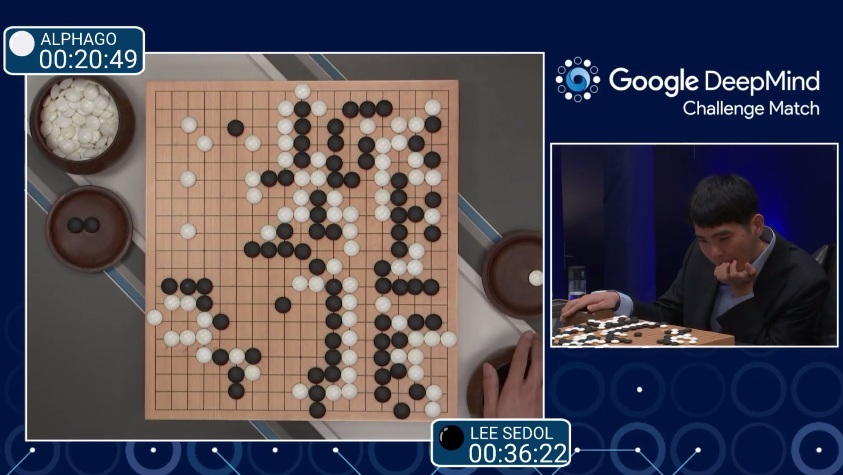
In 2015, Google Deepmind surprised everyone by publishing AlphaGo, a Go AI able to beat the world’s best players, including Lee Sedol in 2016, 19 times world champion.
The RL agent discovers new strategies by using self-play: during the games against Lee Sedol, it was able to use novel moves which were never played before and surprised its opponent.
The new version AlphaZero also plays chess and sokoban at the master level.