Neurocomputing
Multi-layer Perceptron
Multi-layer perceptron

A Multi-Layer Perceptron (MLP) or feedforward neural network is composed of:
an input layer for the input vector \mathbf{x}
one or several hidden layers allowing to project non-linearly the input into a space of higher dimensions \mathbf{h}_1, \mathbf{h}_2, \mathbf{h}_3, \ldots.
an output layer for the output \mathbf{y}.
If there is a single hidden layer \mathbf{h}, it corresponds to the feature space.
Each layer takes inputs from the previous layer.
If the hidden layer is adequately chosen, the output neurons can learn to replicate the desired output \mathbf{t}.
Fully-connected layer
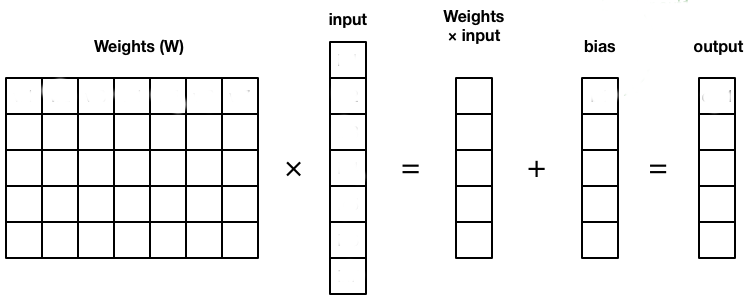
- The operation performed by each layer can be written in the form of a matrix-vector multiplication:
\mathbf{h} = f(\textbf{net}_\mathbf{h}) = f(W^1 \, \mathbf{x} + \mathbf{b}^1) \mathbf{y} = f(\textbf{net}_\mathbf{y}) = f(W^2 \, \mathbf{h} + \mathbf{b}^2)
Fully-connected layers (FC) transform an input vector \mathbf{x} into a new vector \mathbf{h} by multiplying it by a weight matrix W and adding a bias vector \mathbf{b}.
A non-linear activation function transforms each element of the net activation.
Activation functions
![]()
Modern activation functions
- Rectified linear function - ReLU (output is continuous and positive).
f(x) = \max(0, x) = \begin{cases} x \quad \text{if} \quad x \geq 0 \\ 0 \quad \text{otherwise.} \end{cases}
- Parametric Rectifier Linear Unit - PReLU (output is continuous).
f(x) = \begin{cases} x \quad \text{if} \quad x \geq 0 \\ \alpha \, x \quad \text{otherwise.}\end{cases}
Softmax activation function
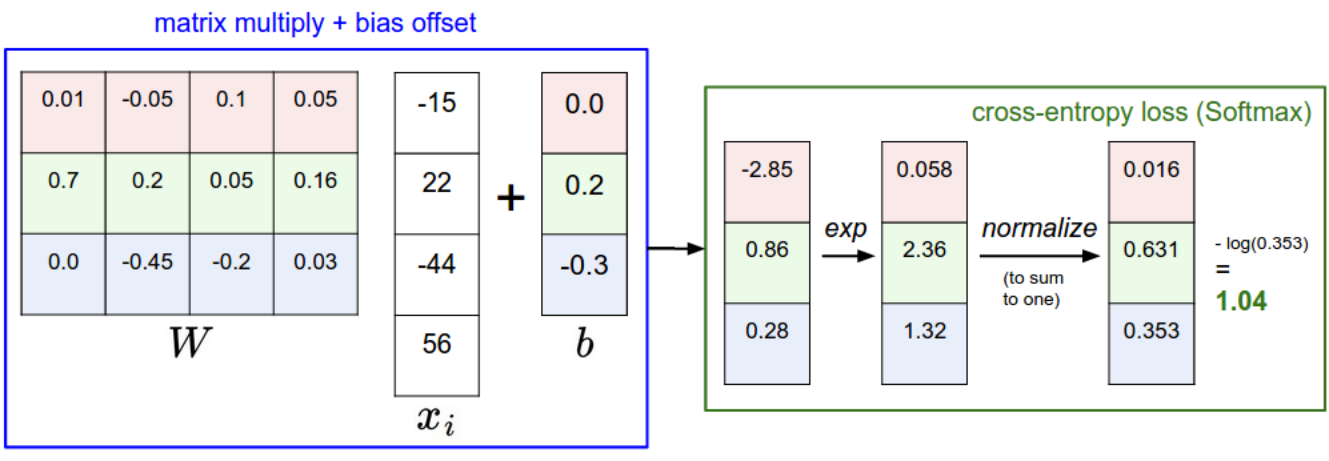
- For classification problems, the softmax activation function can be used in the output layer to make sure that the sum of the outputs \mathbf{y} = \{y_j\} over all output neurons is one.
y_j = P(\text{class = j}) = \frac{\exp(\text{net}_j)}{\sum_k \exp(\text{net}_k)}
The higher the net activation \text{net}_j, the higher the probability that the example belongs to class j.
Softmax is not per se a transfer function (not local to each neuron), but the idea is similar.
Backpropagation on a shallow network
\mathbf{h} = f(\textbf{net}_\mathbf{h}) = f(W^1 \, \mathbf{x} + \mathbf{b}^1) \mathbf{y} = f(\textbf{net}_\mathbf{y}) = f(W^2 \, \mathbf{h} + \mathbf{b}^2)
- The chain rule gives us for the parameters of the output layer:
\frac{\partial \mathcal{L}(\theta)}{\partial W^2} = \frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{y}} \times \frac{\partial \mathbf{y}}{\partial \textbf{net}_\mathbf{y}} \times \frac{\partial \textbf{net}_\mathbf{y}}{\partial W^2}
\frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{b}^2} = \frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{y}} \times \frac{\partial \mathbf{y}}{\partial \textbf{net}_\mathbf{y}} \times \frac{\partial \textbf{net}_\mathbf{y}}{\partial \mathbf{b}^2}
- and for the hidden layer:
\frac{\partial \mathcal{L}(\theta)}{\partial W^1} = \frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{y}} \times \frac{\partial \mathbf{y}}{\partial \textbf{net}_\mathbf{y}} \times \frac{\partial \textbf{net}_\mathbf{y}}{\partial \mathbf{h}} \times \frac{\partial \mathbf{h}}{\partial \textbf{net}_\mathbf{h}} \times \frac{\partial \textbf{net}_\mathbf{h}}{\partial W^1}
\frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{b}^1} = \frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{y}} \times \frac{\partial \mathbf{y}}{\partial \textbf{net}_\mathbf{y}} \times \frac{\partial \textbf{net}_\mathbf{y}}{\partial \mathbf{h}} \times \frac{\partial \mathbf{h}}{\partial \textbf{net}_\mathbf{h}} \times \frac{\partial \textbf{net}_\mathbf{h}}{\partial \mathbf{b}^1}
- If we can compute all these partial derivatives / gradients individually, the problem is solved.
Backpropagated error
- The backpropagated error \mathbf{\delta_h} is a vector assigning an error to each of the hidden neurons:
\mathbf{\delta_h} = - \frac{\partial \mathcal{l}(\theta)}{\partial \textbf{net}_\mathbf{h}} = \mathbf{\delta_y} \times \frac{\partial \textbf{net}_\mathbf{y}}{\partial \mathbf{h}} \times \frac{\partial \mathbf{h}}{\partial \textbf{net}_\mathbf{h}}
- As :
\textbf{net}_\mathbf{y} = W^2 \, \mathbf{h} + \mathbf{b}^2
\mathbf{h} = f(\textbf{net}_\mathbf{h})
we obtain:
\mathbf{\delta_h} = f'(\textbf{net}_\mathbf{h}) \, (W^2)^T \times \mathbf{\delta_y}
If \mathbf{h} and \mathbf{\delta_h} have K elements and \mathbf{y} and \mathbf{\delta_y} have C elements, the matrix W^2 is C \times K as W^2 \times \mathbf{h} must be a vector with C elements.
(W^2)^T \times \mathbf{\delta_y} is therefore a vector with K elements, which is then multiplied element-wise with the derivative of the transfer function to obtain \mathbf{\delta_h}.
Backpropagation for a shallow MLP
- For a shallow MLP with one hidden layer:
\mathbf{h} = f(\textbf{net}_\mathbf{h}) = f(W^1 \, \mathbf{x} + \mathbf{b}^1) \mathbf{y} = f(\textbf{net}_\mathbf{y}) = f(W^2 \, \mathbf{h} + \mathbf{b}^2)
the output error:
\mathbf{\delta_y} = - \frac{\partial \mathcal{l}(\theta)}{\partial \textbf{net}_\mathbf{y}} = (\mathbf{t} - \mathbf{y})
is backpropagated to the hidden layer:
\mathbf{\delta_h} = f'(\textbf{net}_\mathbf{h}) \, (W^2)^T \times \mathbf{\delta_y}
what allows to apply the delta learning rule to all parameters:
\begin{cases} \Delta W^2 = \eta \, \mathbf{\delta_y} \times \mathbf{h}^T \\ \Delta \mathbf{b}^2 = \eta \, \mathbf{\delta_y} \\ \Delta W^1 = \eta \, \mathbf{\delta_h} \times \mathbf{x}^T \\ \Delta \mathbf{b}^1 = \eta \, \mathbf{\delta_h} \\ \end{cases}
What is backpropagated?
Let’s have a closer look at what is backpropagated using single neurons and weights.
The output neuron y_k computes:
y_k = f(\sum_{j=1}^K W^2_{jk} \, h_j + b^2_k)
- All output weights W^2_{jk} are updated proportionally to the output error of the neuron y_k:
\Delta W^2_{jk} = \eta \, \delta_{{y}_k} \, h_j = \eta \, (t_k - y_k) \, h_j
- This is possible because we know the output error directly from the data t_k.
What is backpropagated?
- The hidden neuron h_j computes:
h_j = f(\sum_{i=1}^d W^1_{ij} \, x_i + b^1_j)
- We want to learn the hidden weights W^1_{ij} using the delta learning rule:
\Delta W^1_{ij} = \eta \, \delta_{{h}_j} \, x_i
but we do not know the ground truth of the hidden neuron in the data:
\delta_{{h}_j} = (? - h_j)
- We need to estimate the backpropagated error using the output error.
What is backpropagated?
\mathbf{\delta_h} = f'(\textbf{net}_\mathbf{h}) \, (W^2)^T \times \mathbf{\delta_y}
- If we omit the derivative of the transfer function, the backpropagated error for the hidden neuron h_j is:
\delta_{{h}_j} = - \sum_{k=1}^C W^2_{jk} \, \delta_{{y}_k}
- The backpropagated error is an average of the output errors \delta_{{y}_k}, weighted by the output weights between the hidden neuron h_j and the output neurons y_k.
The backpropagated error is the contribution of each hidden neuron h_j to the output error:
If there is no output error, there is no hidden error.
If a hidden neuron sends strong weights |W^2_{jk}| to an output neuron y_k with a strong prediction error \delta_{{y}_k}, this means that it participates strongly to the output error and should learn from it.
If the weight |W^2_{jk}| is small, it means that the hidden neuron does not take part in the output error.
Deep Neural Network
- A MLP with more than one hidden layer is a deep neural network.
Backpropagation for deep neural networks
- Backpropagation still works if we have many hidden layers \mathbf{h}_1, \ldots, \mathbf{h}_n:
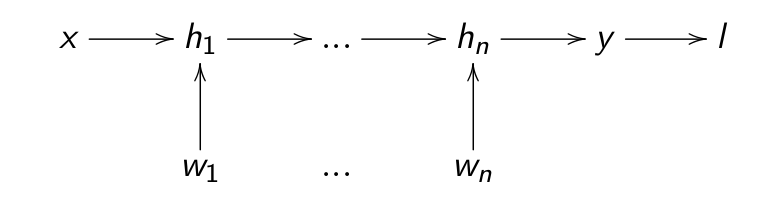
- If each layer is differentiable, i.e. one can compute its gradient \frac{\partial \mathbf{h}_{k}}{\partial \mathbf{h}_{k-1}}, we can chain backwards each partial derivatives to know how to update each layer:
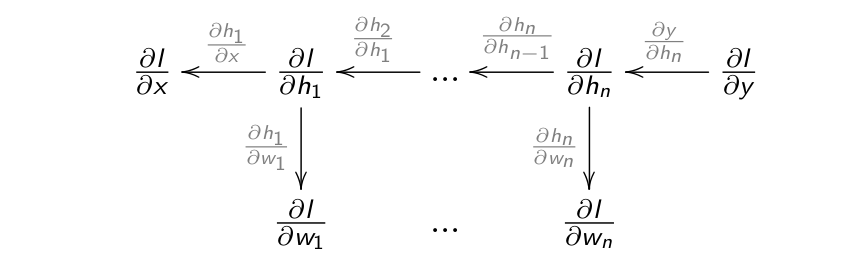
- Backpropagation is simply an efficient implementation of the chain rule: the partial derivatives are iteratively reused in the backwards phase.
Gradient of a fully connected layer
- A fully connected layer transforms an input vector \mathbf{h}_{k-1} into an output vector \mathbf{h}_{k} using a weight matrix W^k, a bias vector \mathbf{b}^k and a non-linear activation function f:
\mathbf{h}_{k} = f(\textbf{net}_{\mathbf{h}^k}) = f(W^k \, \mathbf{h}_{k-1} + \mathbf{b}^k)
- The gradient of its output w.r.t the input \mathbf{h}_{k-1} is (using the chain rule):
\frac{\partial \mathbf{h}_{k}}{\partial \mathbf{h}_{k-1}} = f'(\textbf{net}_{\mathbf{h}^k}) \, W^k
- The gradients of its output w.r.t the free parameters W^k and \mathbf{b}_{k} are:
\frac{\partial \mathbf{h}_{k}}{\partial W^{k}} = f'(\textbf{net}_{\mathbf{h}^k}) \, \mathbf{h}_{k-1}
\frac{\partial \mathbf{h}_{k}}{\partial \mathbf{b}_{k}} = f'(\textbf{net}_{\mathbf{h}^k})
Gradient of a fully connected layer
- A fully connected layer \mathbf{h}_{k} = f(W^k \, \mathbf{h}_{k-1} + \mathbf{b}^k) receives the gradient of the loss function w.r.t. its output \mathbf{h}_{k} from the layer above:
\frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k}}
- It adds to this gradient its own contribution and transmits it to the previous layer:
\frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k-1}} = \frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k}} \times \frac{\partial \mathbf{h}_{k}}{\partial \mathbf{h}_{k-1}} = f'(\textbf{net}_{\mathbf{h}^k}) \, (W^k)^T \times \frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k}}
- It then updates its parameters W^k and \mathbf{b}_{k} with:
\begin{cases} \dfrac{\partial \mathcal{L}(\theta)}{\partial W^{k}} = \dfrac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k}} \times \dfrac{\partial \mathbf{h}_{k}}{\partial W^{k}} = f'(\textbf{net}_{\mathbf{h}^k}) \, \dfrac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k}} \times \mathbf{h}_{k-1}^T \\ \\ \dfrac{\partial \mathcal{L}(\theta)}{\partial \mathbf{b}_{k}} = \dfrac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k}} \times \dfrac{\partial \mathbf{h}_{k}}{\partial \mathbf{b}_{k}} = f'(\textbf{net}_{\mathbf{h}^k}) \, \dfrac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k}} \\ \end{cases}
Training a deep neural network with backpropagation
- A feedforward neural network is an acyclic graph of differentiable and parameterized layers.
\mathbf{x} \rightarrow \mathbf{h}_1 \rightarrow \mathbf{h}_2 \rightarrow \ldots \rightarrow \mathbf{h}_n \rightarrow \mathbf{y}
- The backpropagation algorithm is used to assign the gradient of the loss function \mathcal{L}(\theta) to each layer using backward chaining:
\frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k-1}} = \frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k}} \times \frac{\partial \mathbf{h}_{k}}{\partial \mathbf{h}_{k-1}}
- Stochastic gradient descent is then used to update the parameters of each layer:
\Delta W^k = - \eta \, \frac{\partial \mathcal{L}(\theta)}{\partial W^{k}} = - \eta \, \frac{\partial \mathcal{L}(\theta)}{\partial \mathbf{h}_{k}} \times \frac{\partial \mathbf{h}_{k}}{\partial W^{k}}
MLP example
- Let’s try to solve this non-linear binary classification problem:
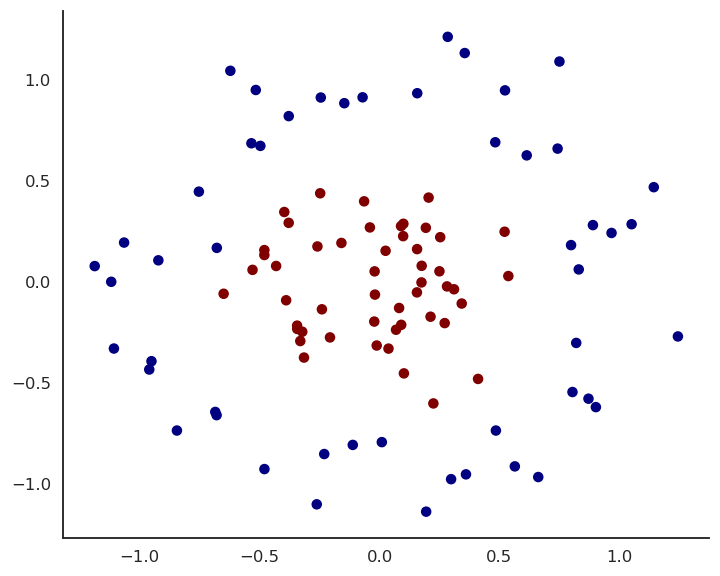
MLP example

We can create a shallow MLP with:
Two input neurons x_1, x_2 for the two input variables.
Enough hidden neurons (e.g. 20), with a sigmoid or ReLU activation function.
One output neuron with the logistic activation function.
The cross-entropy (negative log-likelihood) loss function.
We train it on the input data using the backpropagation algorithm and the SGD optimizer.
MLP example
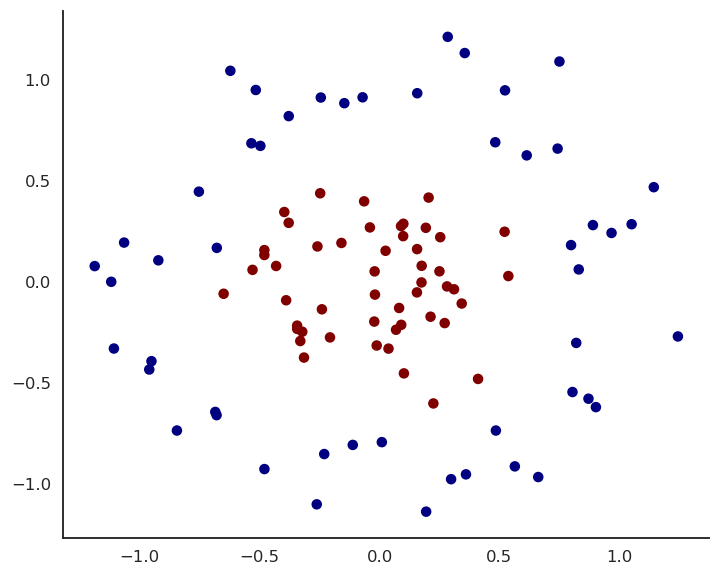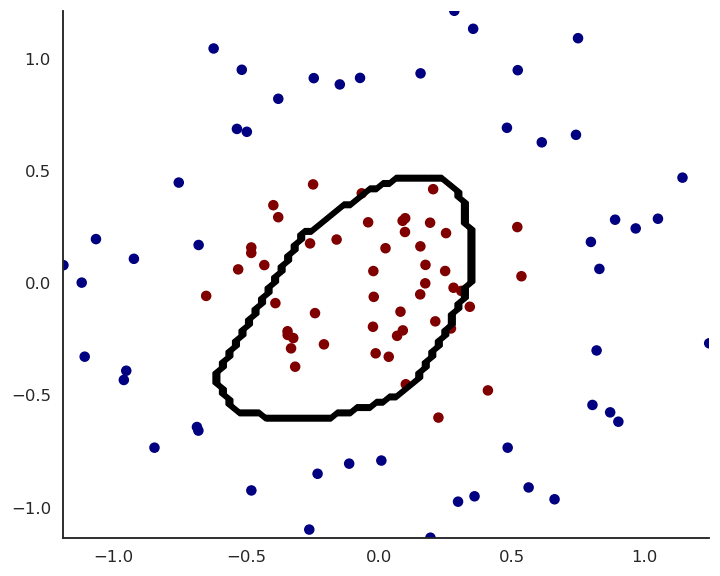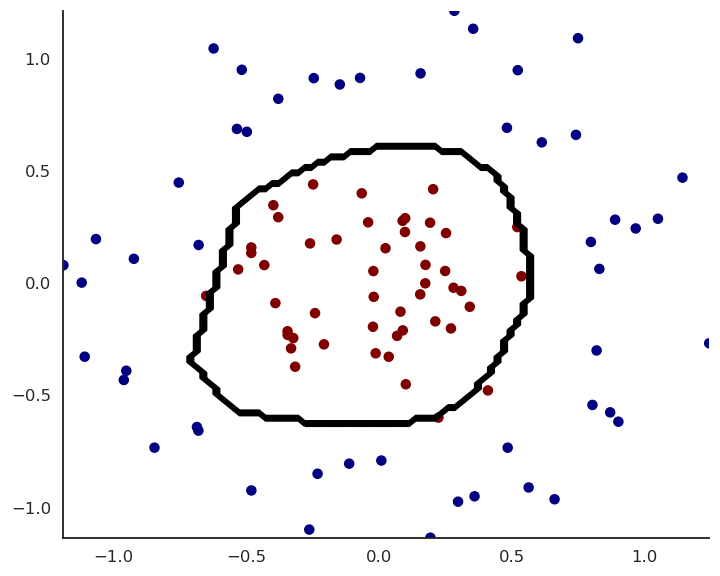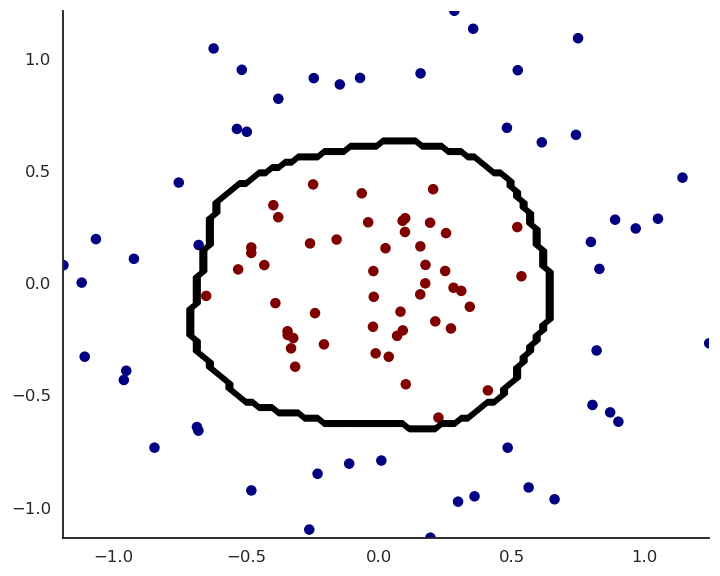
- Experiment live on https://playground.tensorflow.org/!