Neurocomputing
Transformers
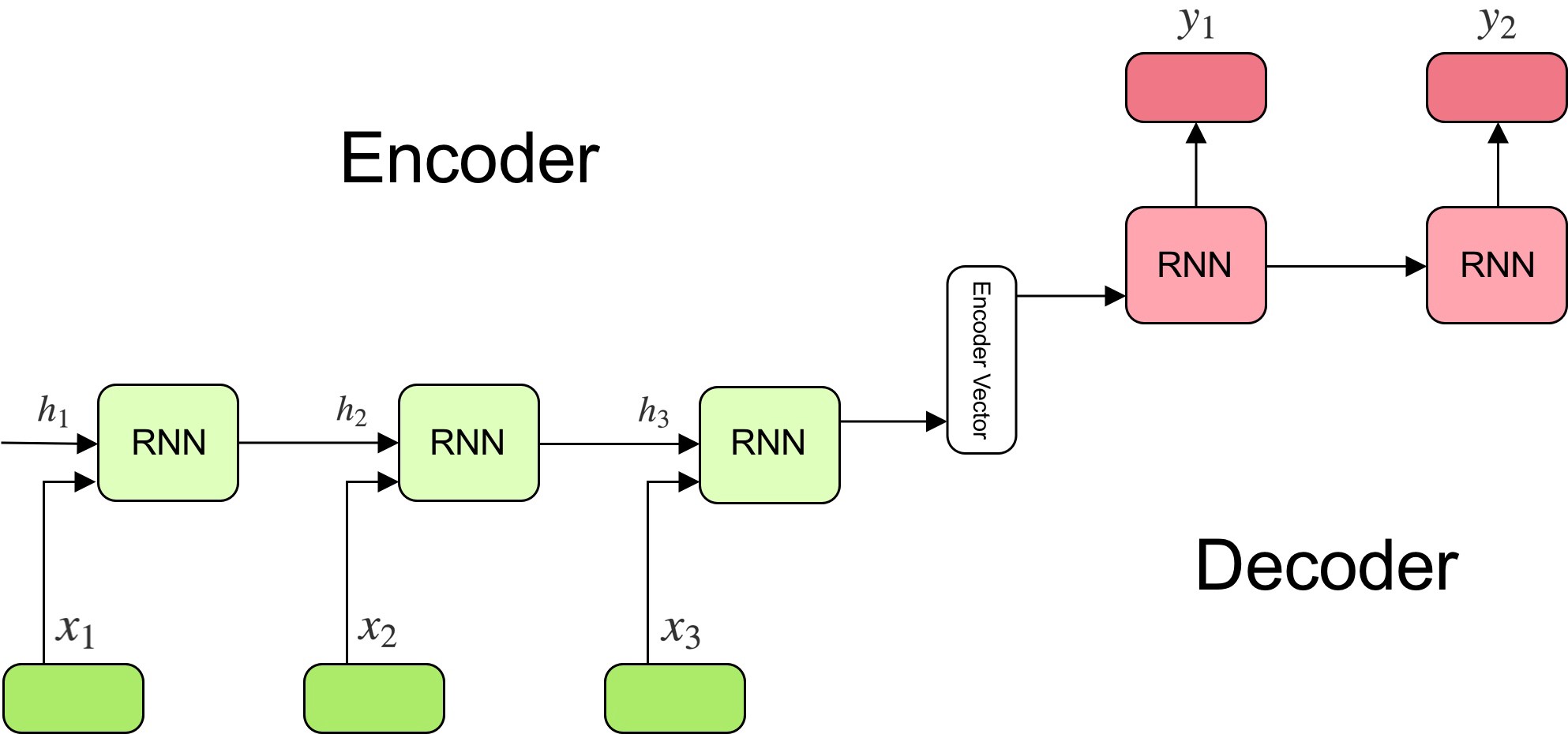
Many to Many: seq2seq
The state vector obtained at the end of a sequence can be reused as an initial state for another LSTM.
The goal of the encoder is to find a compressed representation of a sequence of inputs.
The goal of the decoder is to generate a sequence from that representation.
Sequence-to-sequence (seq2seq) models are recurrent autoencoders.
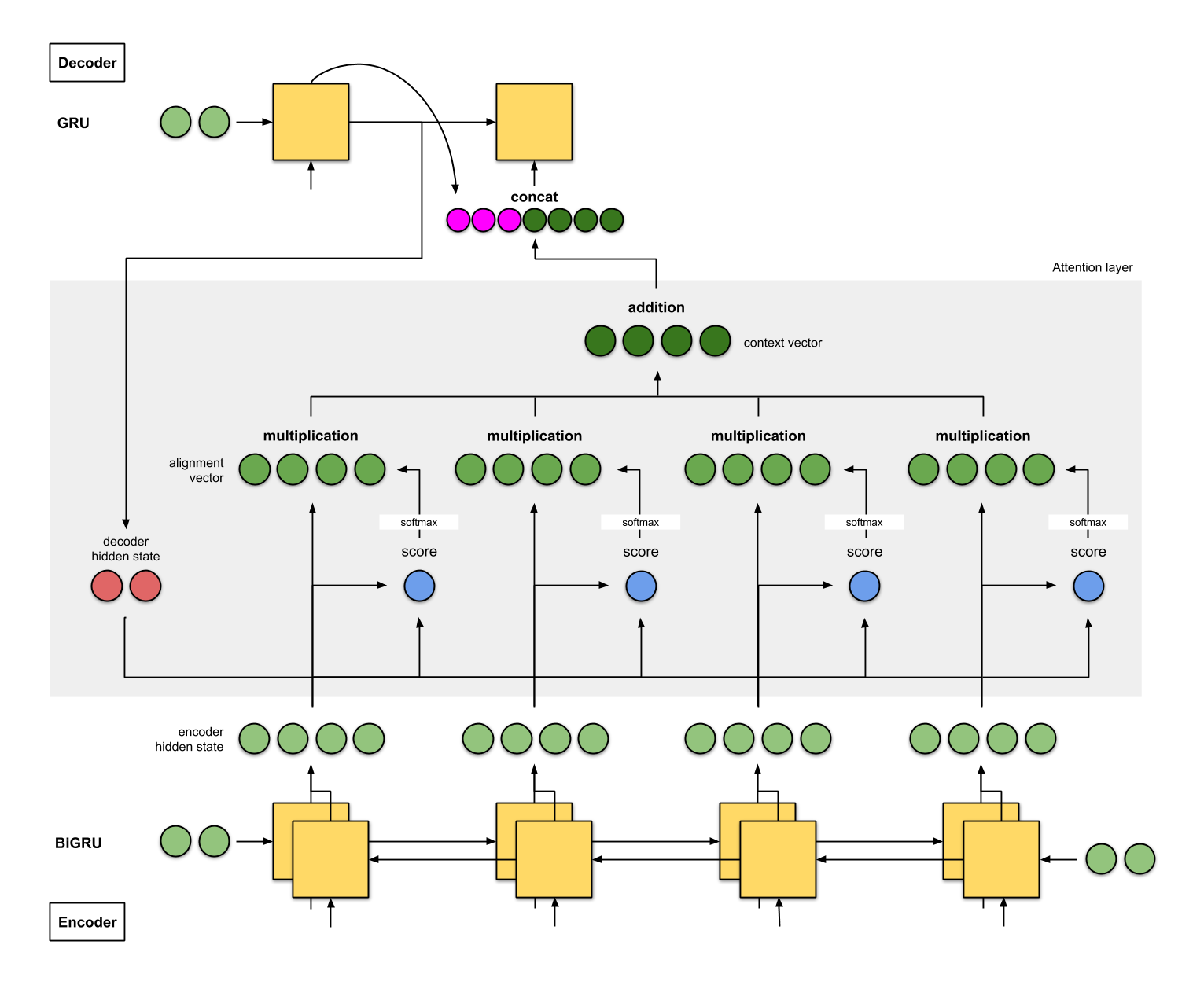
Attentional recurrent networks
- Attentional mechanisms let the decoder decide (by learning) which state vectors it needs to generate each word at each step.
- The attentional context vector of the decoder A^\text{decoder}_t at time t is a weighted average of all state vectors C^\text{encoder}_i of the encoder.
A^\text{decoder}_t = \sum_{i=0}^T a_i \, C^\text{encoder}_i
- The coefficients a_i are called the attention scores : how much attention is the decoder paying to each of the encoder’s state vectors?
![]()
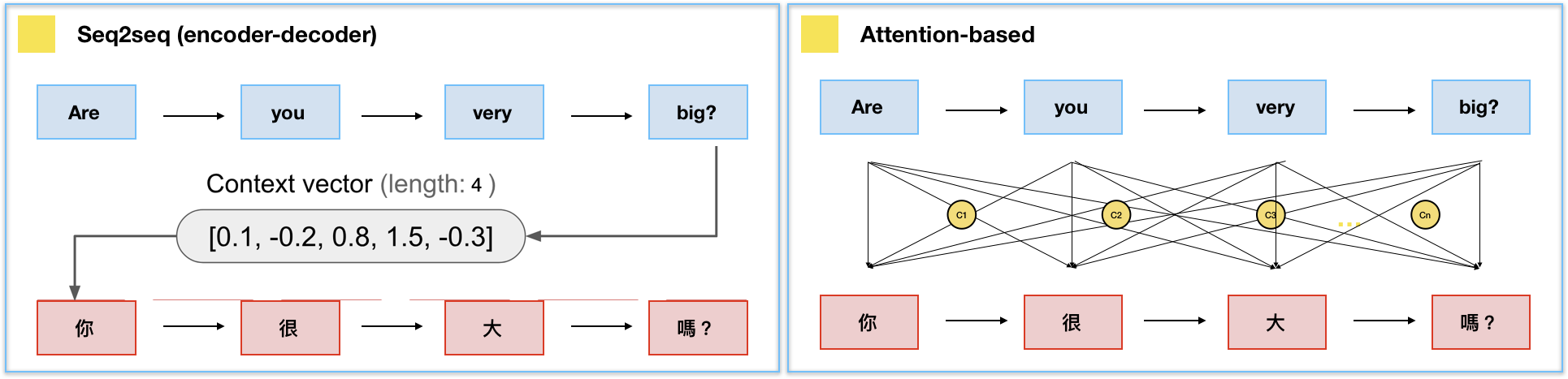
Attentional recurrent networks
The attention scores or alignment scores a_i are useful to interpret what happened.
They show which words in the original sentence are the most important to generate the next word.

Attentional recurrent networks
- Attentional mechanisms are now central to NLP.
The whole history of encoder states is passed to the decoder, which learns to decide which part is the most important using attention.
This solves the bottleneck of seq2seq architectures, at the cost of much more operations.
They require to use fixed-length sequences (generally 50 words).
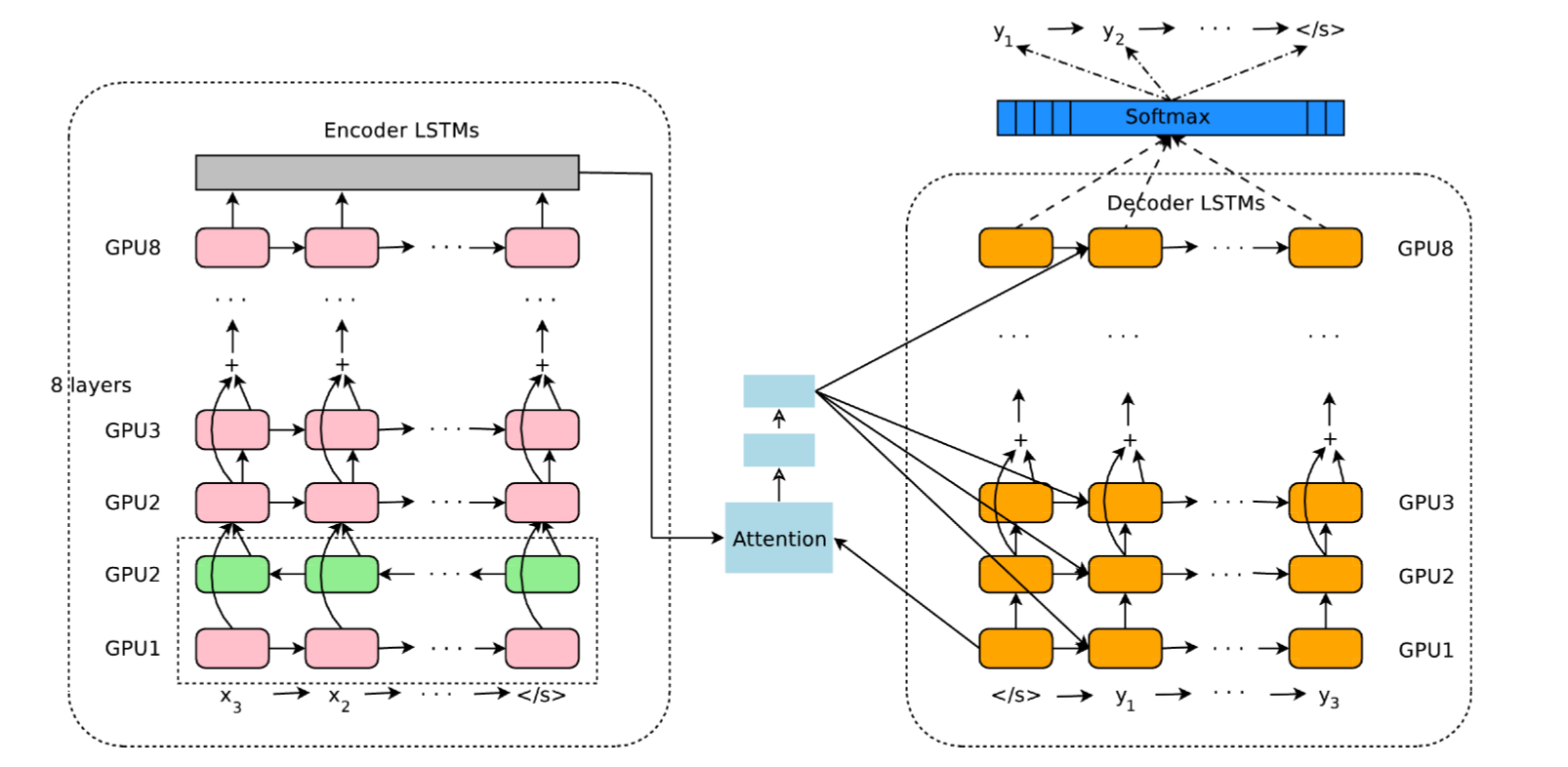
Google Neural Machine Translation (GNMT)
- Google Neural Machine Translation (GNMT) uses an attentional recurrent NN, with bidirectional GRUs, 8 recurrent layers on 8 GPUs for both the encoder and decoder.
2 - Transformers
![]()
Transformer networks
Attentional mechanisms are so powerful that recurrent networks are not even needed anymore.
Transformer networks use self-attention in a purely feedforward architecture and outperform recurrent architectures.
Used in Google BERT and OpenAI GPT-3 for text understanding (e.g. search engine queries) and generation.
Transformer networks
- Transformer networks use an encoder-decoder architecture, each with 6 stacked layers.
Encoder layer
Each layer of the encoder processes the n words of the input sentence in parallel.
Word embeddings (as in word2vec) of dimension 512 are used as inputs (but learned end-to-end).
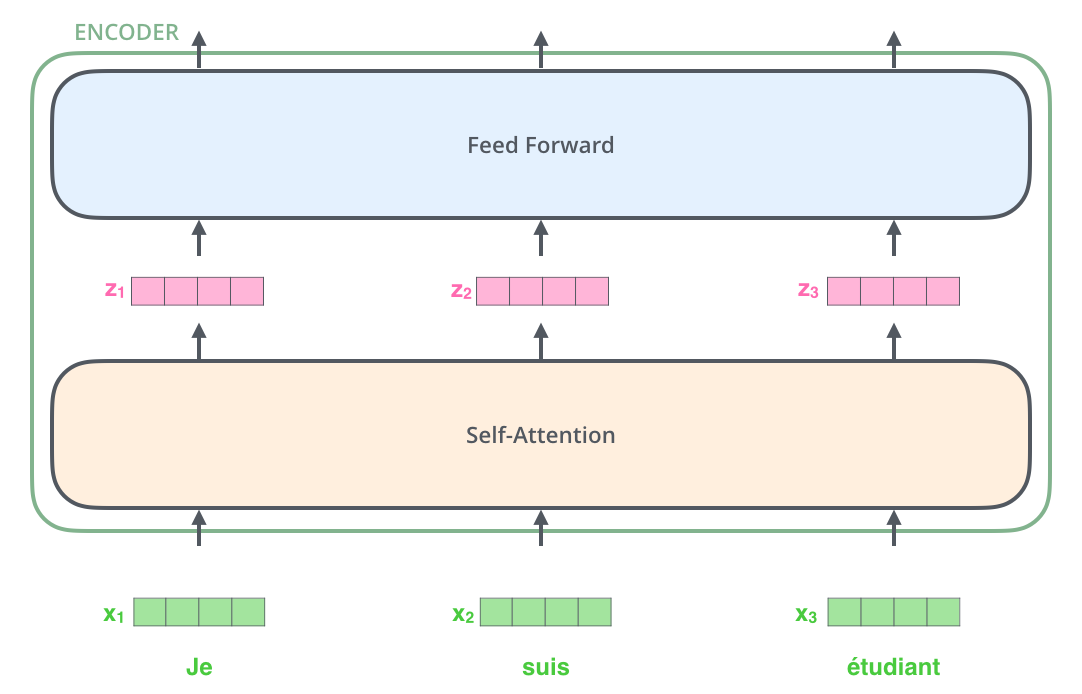
Encoder layer
Two operations are performed on each word embedding \mathbf{x}_i:
self-attention vector \mathbf{z}_i depending on the other words.
a regular feedforward layer to obtain a new representation \mathbf{r}_i (shared among all words).
Self-attention
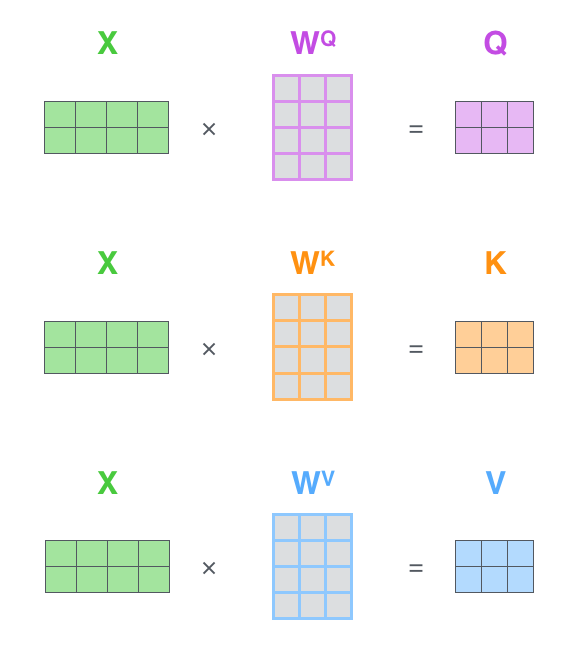
The first step of self-attention is to compute for each word three vectors of length d_k = 64 from the embeddings \mathbf{x}_i or previous representations \mathbf{r}_i (d = 512).
The query \mathbf{q}_i using W^Q.
The key \mathbf{k}_i using W^K.
The value \mathbf{v}_i using W^V.
- This operation can be done in parallel over all words:
Self-attention
![]()
In attentional RNNs, the attention scores were used by each word generated by the decoder to decide which input word is relevant.
If we apply the same idea to the same sentence (self-attention), the attention score tells how much words of the same sentence are related to each other (context).
The animal didn’t cross the street because it was too tired.
The goal is to learn a representation for the word
itthat contains information aboutthe animal, notthe street.
![]()
Self-attention
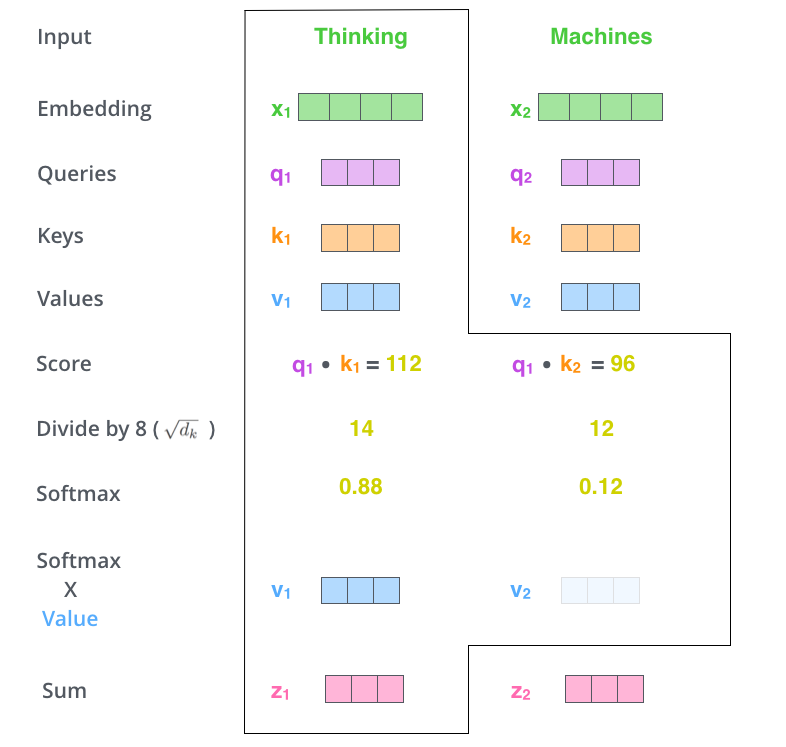
- Each word \mathbf{x}_i of the sentence generates its query \mathbf{q}_i, key \mathbf{k}_i and value \mathbf{v}_i.
- For all other words \mathbf{x}_j, we compute the match between the query \mathbf{q}_i and the keys \mathbf{k}_j with a dot product:
e_{i, j} = \mathbf{q}_i^T \, \mathbf{k}_j
- We normalize the scores by dividing by \sqrt{d_k} = 8 and apply a softmax:
a_{i, j} = \text{softmax}(\dfrac{\mathbf{q}_i^T \, \mathbf{k}_j}{\sqrt{d_k}})
- The new representation \mathbf{z}_i of the word \mathbf{x}_i is a weighted sum of the values of all other words, weighted by the attention score:
\mathbf{z}_i = \sum_{j} a_{i, j} \, \mathbf{v}_j
Self-attention
- If we concatenate the word embeddings into a n\times d matrix X, self-attention only implies matrix multiplications and a row-based softmax:
\begin{cases} Q = X \times W^Q \\ K = X \times W^K \\ V = X \times W^V \\ Z = \text{softmax}(\dfrac{Q \times K^T}{\sqrt{d_k}}) \times V \\ \end{cases}
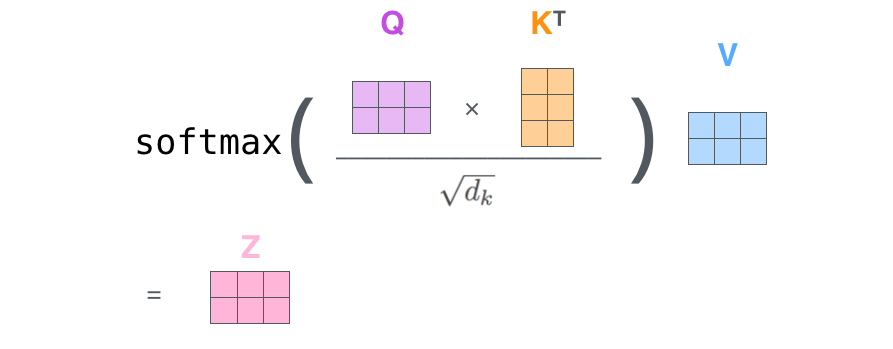
Note 1: everything is differentiable, backpropagation will work.
Note 2: the weight matrices do not depend on the length n of the sentence.
Multi-headed self-attention
In the sentence The animal didn’t cross the street because it was too tired., the new representation for the word
itwill hopefully contain features of the wordanimalafter training.But what if the sentence was The animal didn’t cross the street because it was too wide.? The representation of
itshould be linked tostreetin that context.This is not possible with a single set of matrices W^Q, W^K and W^V, as they would average every possible context and end up being useless.
Multi-headed self-attention
- The solution is to use multiple attention heads (h=8) with their own matrices W^Q_k, W^K_k and W^V_k.
Multi-headed self-attention
Each attention head will output a vector \mathbf{z}_i of size d_k=64 for each word.
How do we combine them?
Multi-headed self-attention
The proposed solution is based on ensemble learning (stacking):
let another matrix W^O decide which attention head to trust…
8 \times 64 rows, 512 columns.
Multi-headed self-attention
Multi-headed self-attention
Each attention head learns a different context:
itrefers toanimal.itrefers tostreet.etc.
The original transformer paper in 2017 used 8 attention heads.
OpenAI’s GPT-3 uses 96 attention heads…
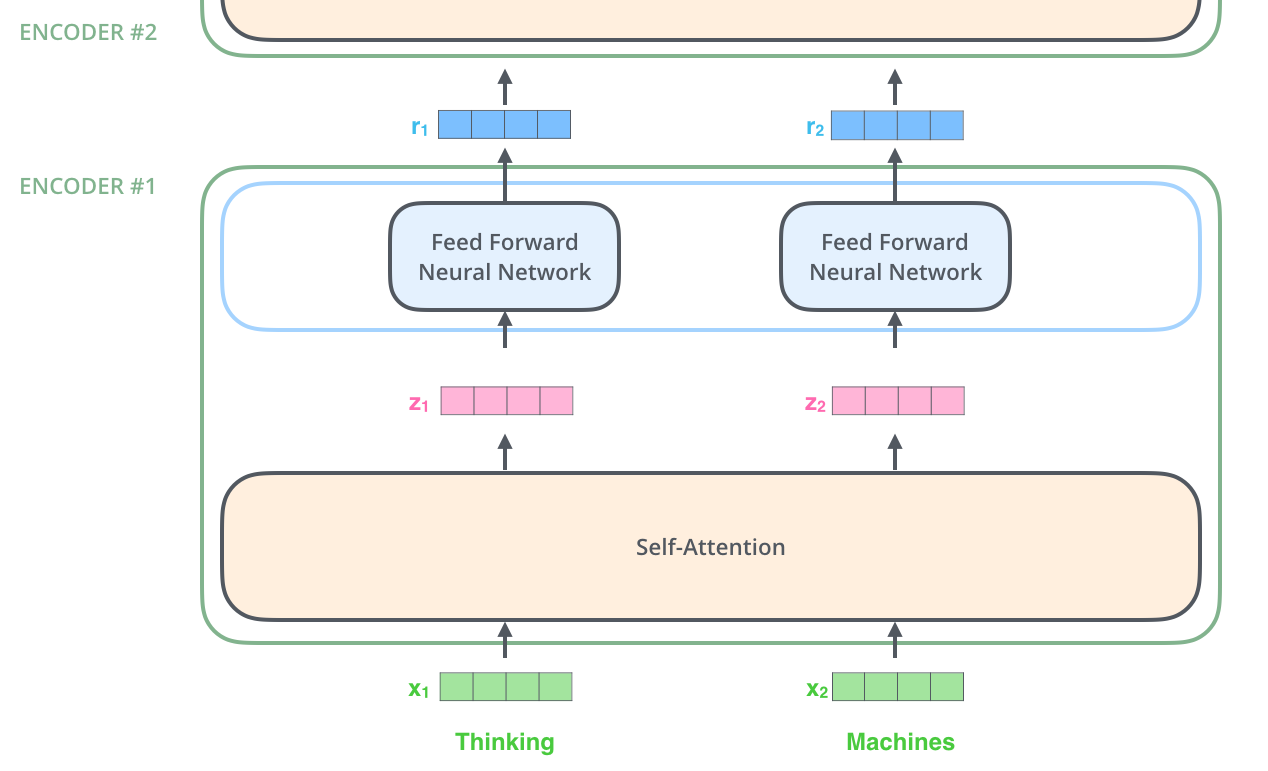
Encoder layer
Multi-headed self-attention produces a vector \mathbf{z}_i for each word of the sentence.
A regular feedforward MLP transforms it into a new representation \mathbf{r}_i.
one input layer with 512 neurons.
one hidden layer with 2048 neurons and a ReLU activation function.
one output layer with 512 neurons.
The same NN is applied on all words, it does not depend on the length n of the sentence.
Positional encoding
- As each word is processed in parallel, the order of the words in the sentence is lost.
street was animal tired the the because it cross too didn’t
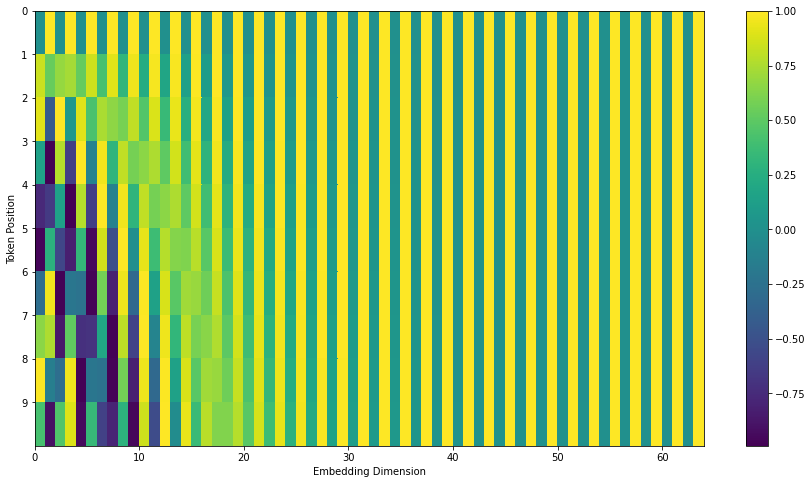
We need to explicitly provide that information in the input using positional encoding.
A simple method would be to append an index i = 1, 2, \ldots, n to the word embeddings, but it is not very robust.
Positional encoding
If the elements of the 512-d embeddings are numbers between 0 and 1, concatenating an integer between 1 and n will unbalance the dimensions.
Normalizing that integer between 0 and 1 requires to know n in advance, this introduces a maximal sentence length…
How about we append the binary code of that integer?
Sounds good, we have numbers between 0 and 1, and we just need to use enough bits to encode very long sentences.
However, representing a binary value (0 or 1) with a 64 bits floating number is a waste of computational resources.
Positional encoding
We can notice that the bits of the integers oscillate at various frequencies:
the lower bit oscillates every number.
the bit before oscillates every two numbers.
etc.

We could also represent the position of a word using sine and cosine functions at different frequencies (Fourier basis).
We create a vector, where each element oscillates at increasing frequencies.
The “code” for each position in the sentence is unique.
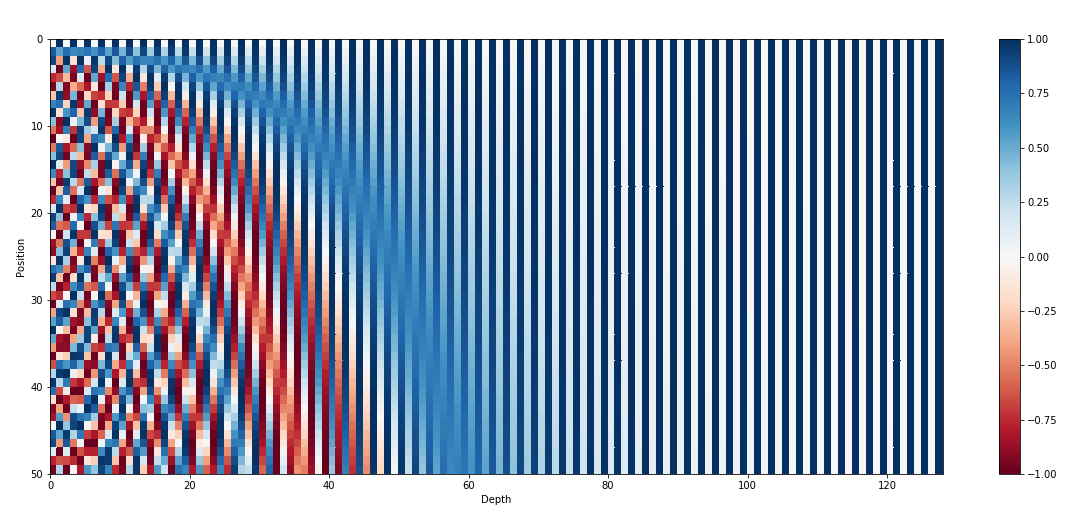
Positional encoding
- In practice, a 512-d vector is created using sine and cosine functions.
\begin{cases} t(\text{pos}, 2i) = \sin(\dfrac{\text{pos}}{10000^{2 i / 512}})\\ t(\text{pos}, 2i + 1) = \cos(\dfrac{\text{pos}}{10000^{2 i / 512}})\\ \end{cases}
Positional encoding
- The positional encoding vector is added element-wise to the embedding, not concatenated!
\mathbf{x}_{i} = \mathbf{x}^\text{embed}_{i} + \mathbf{t}_i
Encoder layer
Last tricks of the encoder layers:
skip connections (residual layer)
layer normalization
The input X is added to the output of the multi-headed self-attention and normalized (zero mean, unit variance).
Layer normalization (Ba et al., 2016) is an alternative to batch normalization, where the mean and variance are computed over single vectors, not over a minibatch:
\mathbf{z} \leftarrow \dfrac{\mathbf{z} - \mu}{\sigma}
with \mu = \dfrac{1}{d} \displaystyle\sum_{i=1}^d z_i and \sigma = \dfrac{1}{d} \displaystyle\sum_{i=1}^d (z_i - \mu)^2.
- The feedforward network also uses a skip connection and layer normalization.
Encoder
- We can now stack 6 (or more, 96 in GPT-3) of these encoder layers and use the final representation of each word as an input to the decoder.
Decoder
In the first step of decoding, the final representations of the encoder are used as query and value vectors of the decoder to produce the first word.
The input to the decoder is a “start of sentence” symbol.
Decoder
- The decoder is autoregressive: it outputs words one at a time, using the previously generated words as an input.
Decoder layer
Each decoder layer has two multi-head attention sub-layers:
A self-attention sub-layer with query/key/values coming from the generated sentence.
An encoder-decoder attention sub-layer, with the query coming from the generated sentence and the key/value from the encoder.
The encoder-decoder attention is the regular attentional mechanism used in seq2seq architectures.
Apart from this additional sub-layer, the same residual connection and layer normalization mechanisms are used.
![]()
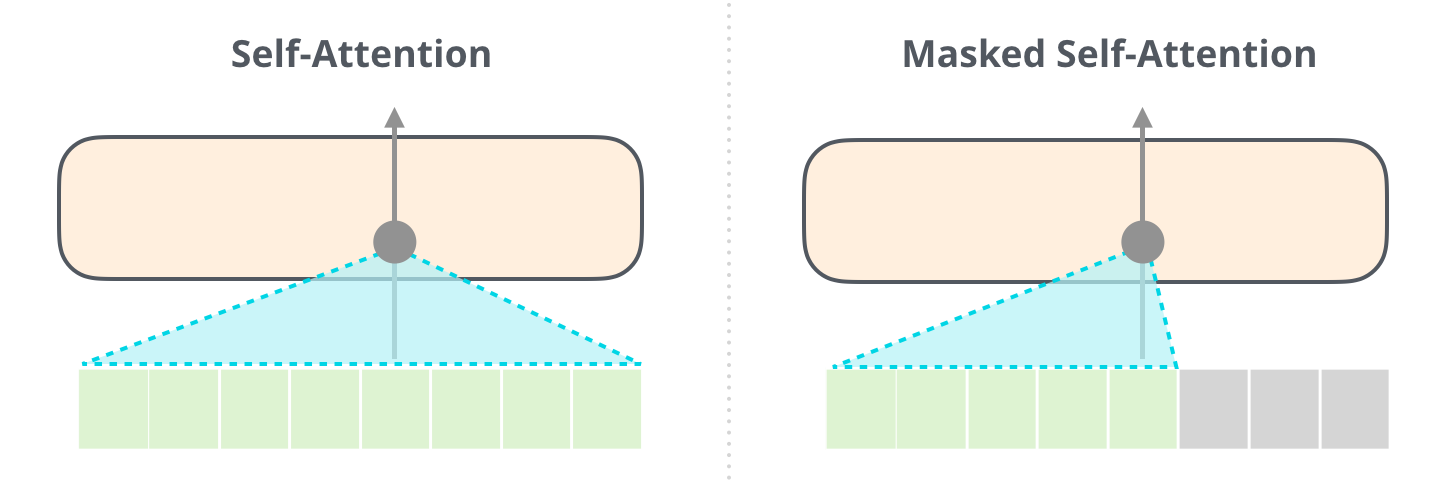
Masked self-attention
When the sentence has been fully generated (up to the
<eos>symbol), masked self-attention has to applied in order for a word in the middle of the sentence to not “see” the solution in the input when learning.As usual, learning occurs on minibatches of sentences, not on single words.
Output
- The output of the decoder is a simple softmax classification layer, predicting the one-hot encoding of the word using a vocabulary (
vocab_size=25000).
Training procedure
The transformer is trained on the WMT datasets:
English-French: 36M sentences, 32000 unique words.
English-German: 4.5M sentences, 37000 unique words.
Cross-entropy loss, Adam optimizer with scheduling, dropout. Training took 3.5 days on 8 P100 GPUs.
The sentences can have different lengths, as the decoder is autoregressive.
The transformer network beat the state-of-the-art performance in translation with less computations and without any RNN.
![]()
Transformer-based language models
The Transformer is considered as the AlexNet moment of natural language processing (NLP).
However, it is limited to supervised learning of sentence-based translation.
Two families of architectures have been developed from that idea to perform all NLP tasks using unsupervised pretraining or self-supervised training:
BERT (Bidirectional Encoder Representations from Transformers) from Google.
GPT (Generative Pre-trained Transformer) from OpenAI https://openai.com/blog/better-language-models/.
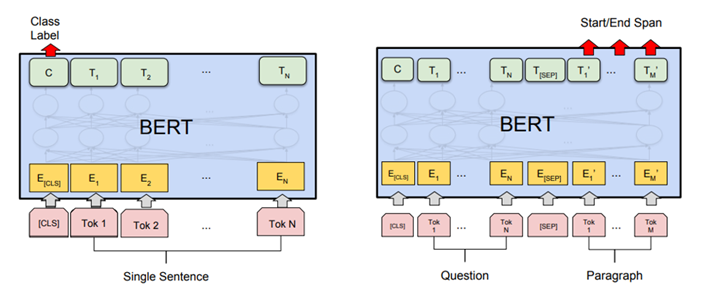
BERT - Bidirectional Encoder Representations from Transformers
BERT only uses the encoder of the transformer (12 layers, 12 attention heads, d = 768).
BERT is pretrained on two different unsupervised tasks before being fine-tuned on supervised tasks.
BERT - Bidirectional Encoder Representations from Transformers
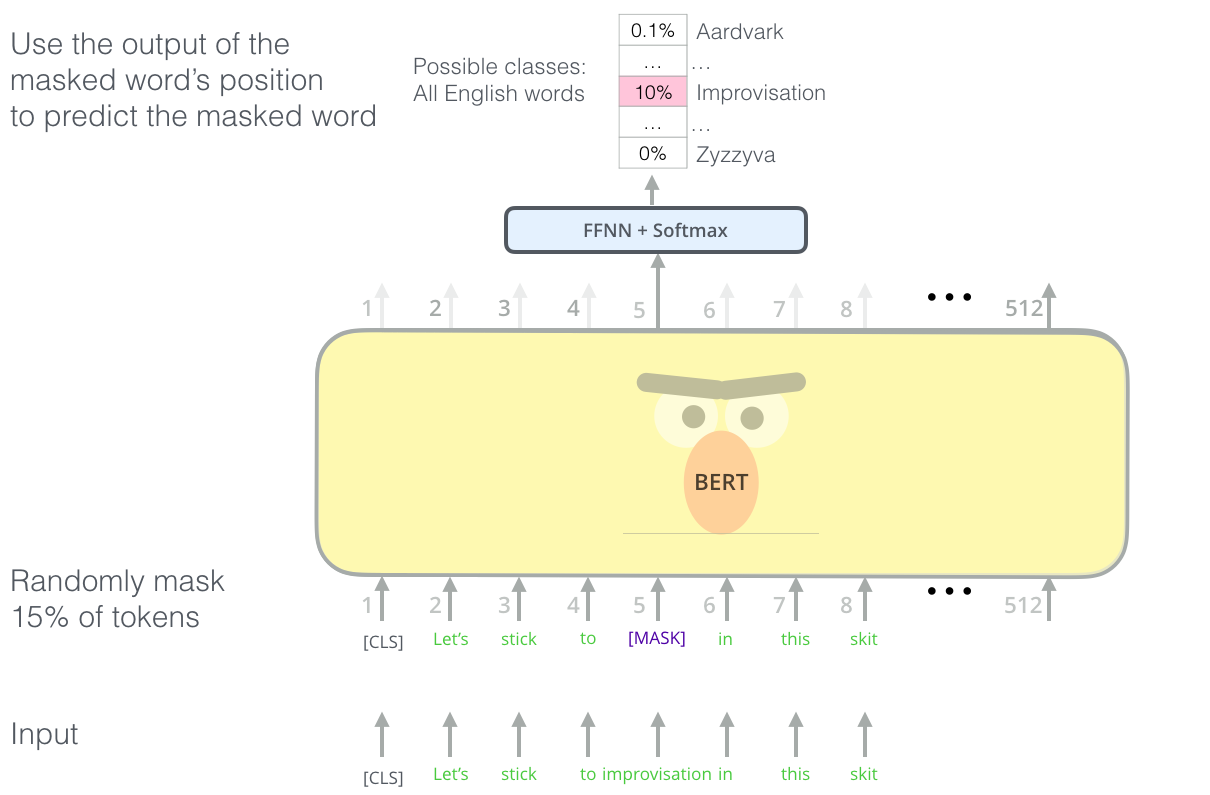
Task 1: Masked language model. Sentences from BooksCorpus and Wikipedia (3.3G words) are presented to BERT during pre-training, with 15% of the words masked.
The goal is to predict the masked words from the final representations using a shallow FNN.
BERT - Bidirectional Encoder Representations from Transformers
Task 2: Next sentence prediction. Two sentences are presented to BERT.
The goal is to predict from the first representation whether the second sentence should follow the first.

BERT - Bidirectional Encoder Representations from Transformers
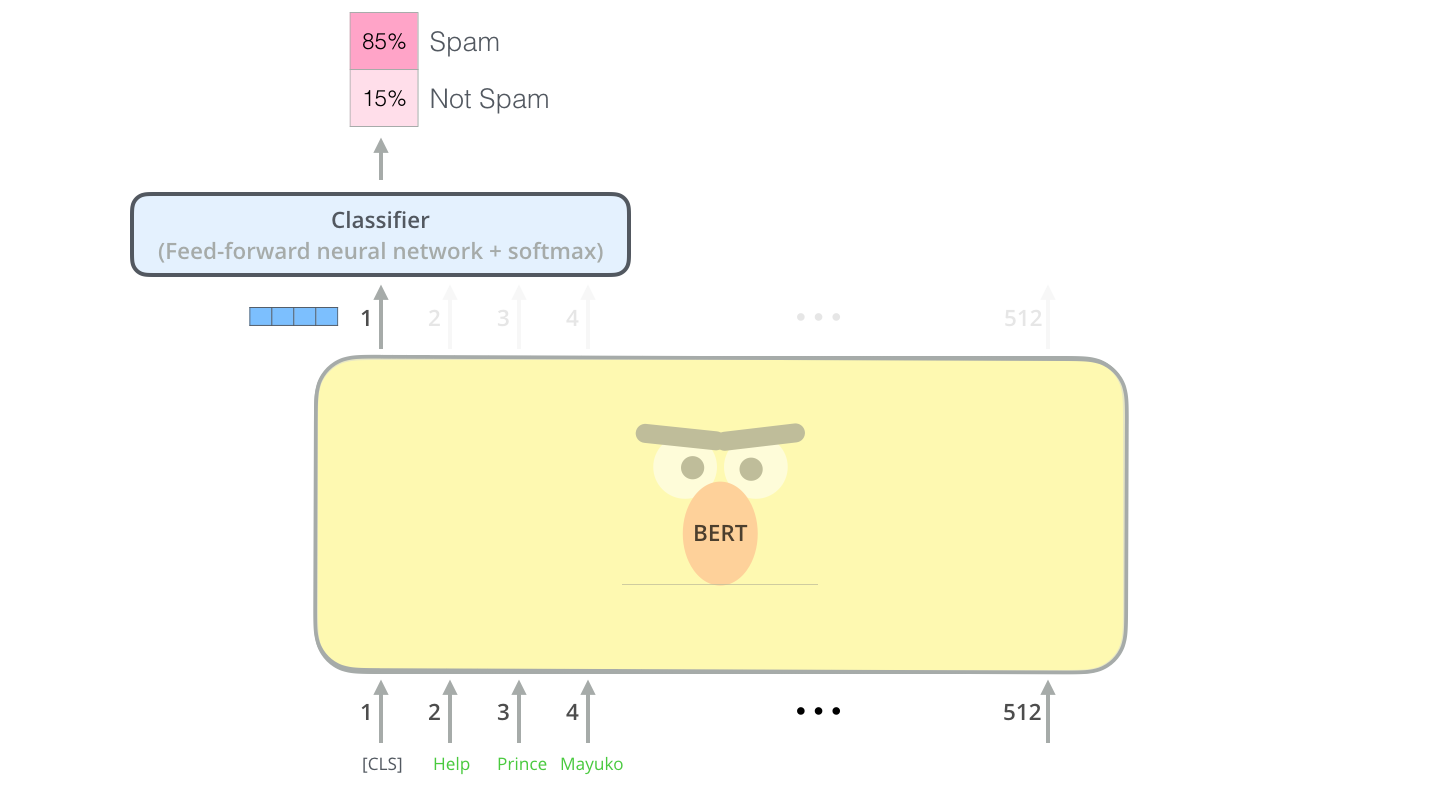
Once BERT is pretrained, one can use transfer learning with or without fine-tuning from the high-level representations to perform:
sentiment analysis / spam detection
question answering
BERT - Bidirectional Encoder Representations from Transformers
GPT - Generative Pre-trained Transformer
- As the Transformer, GPT is an autoregressive language model learning to predict the next word using only the transformer’s decoder.
GPT - Generative Pre-trained Transformer
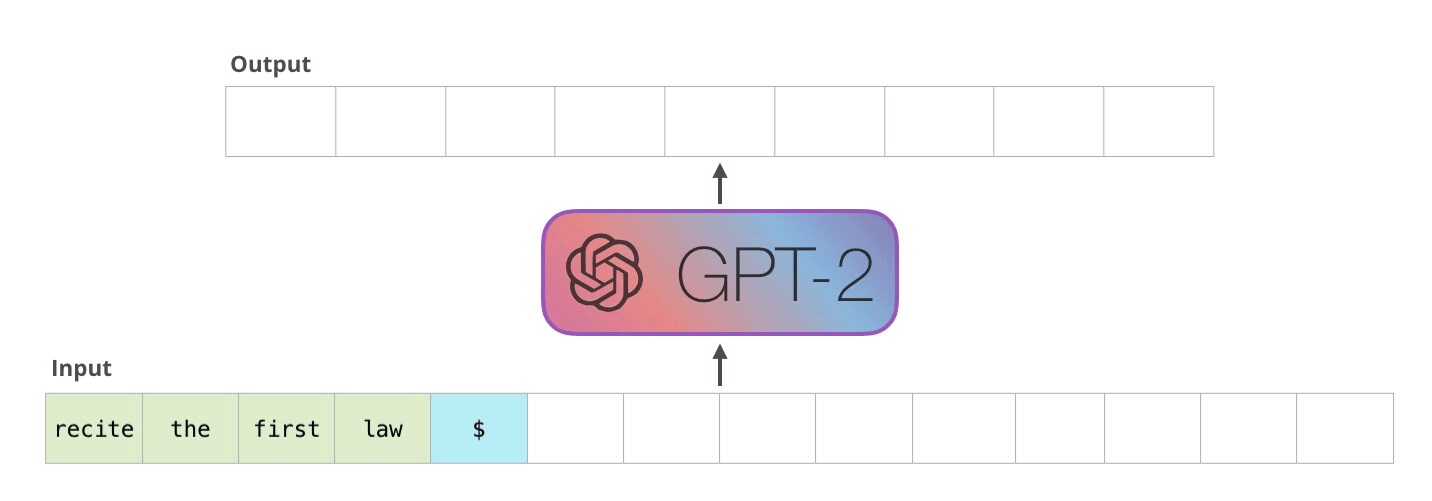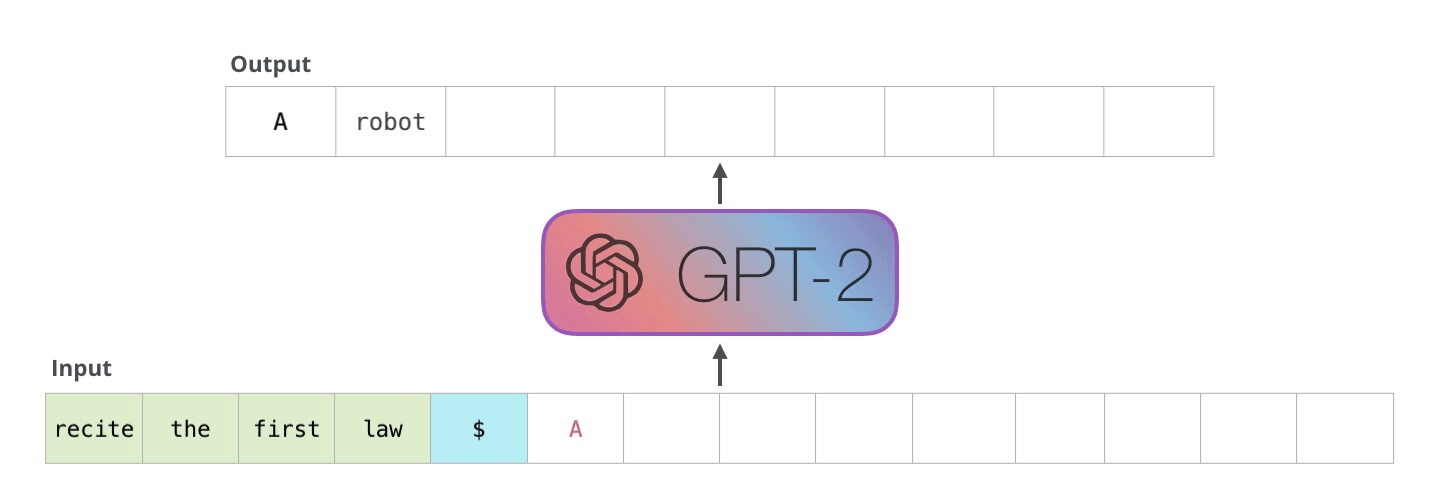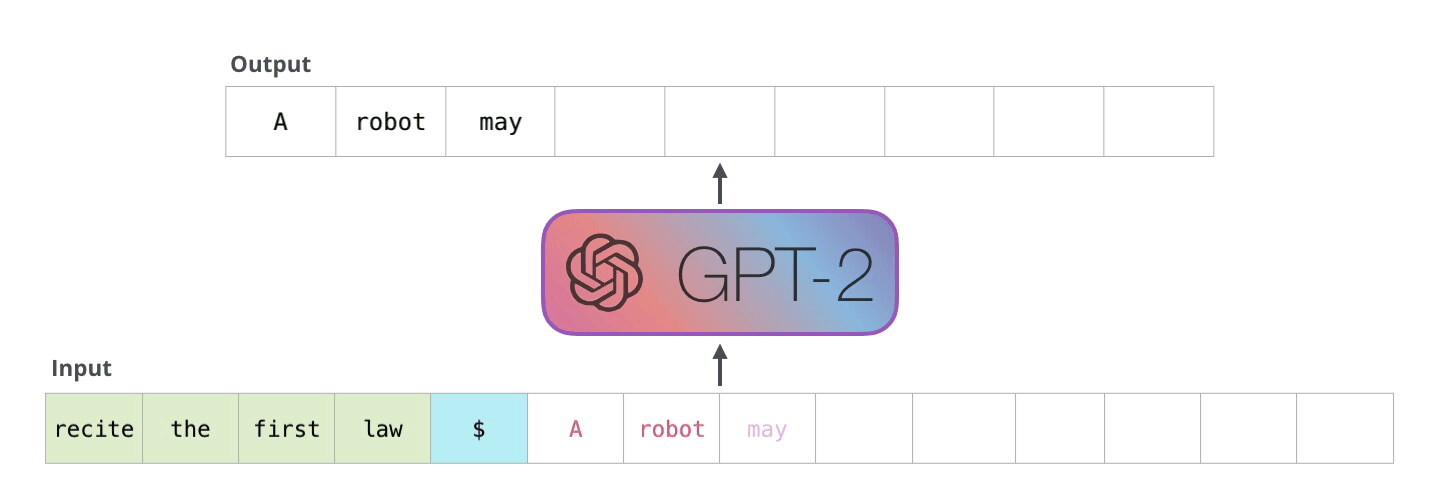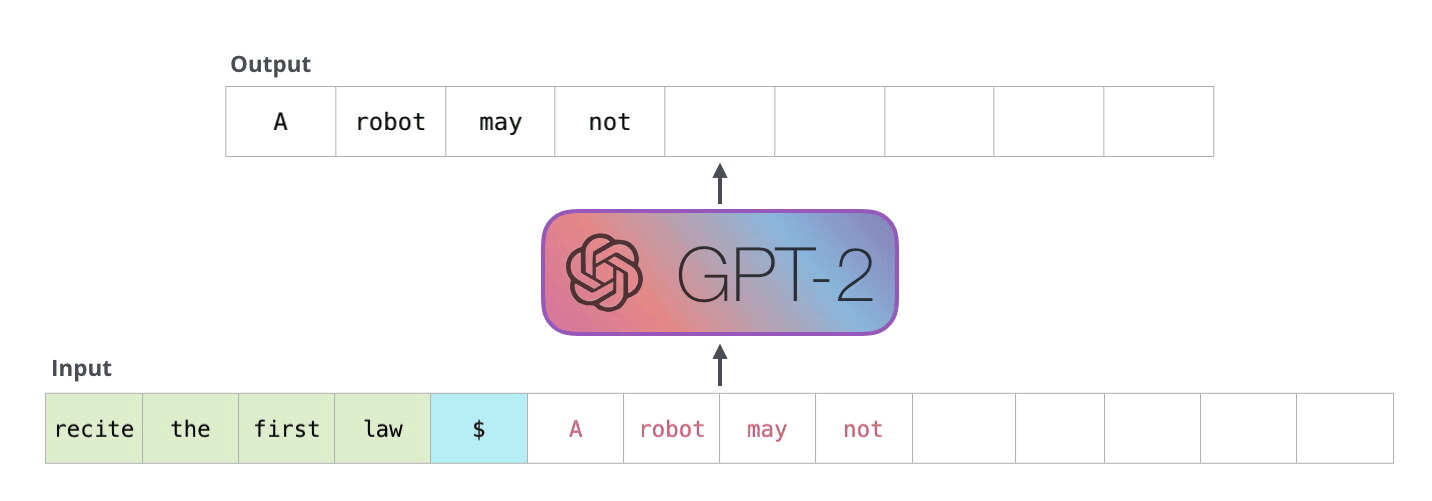
GPT - Generative Pre-trained Transformer
GPT-2 comes in various sizes, with increasing performance.
GPT-3 is even bigger, with 175 billion parameters and a much larger training corpus.
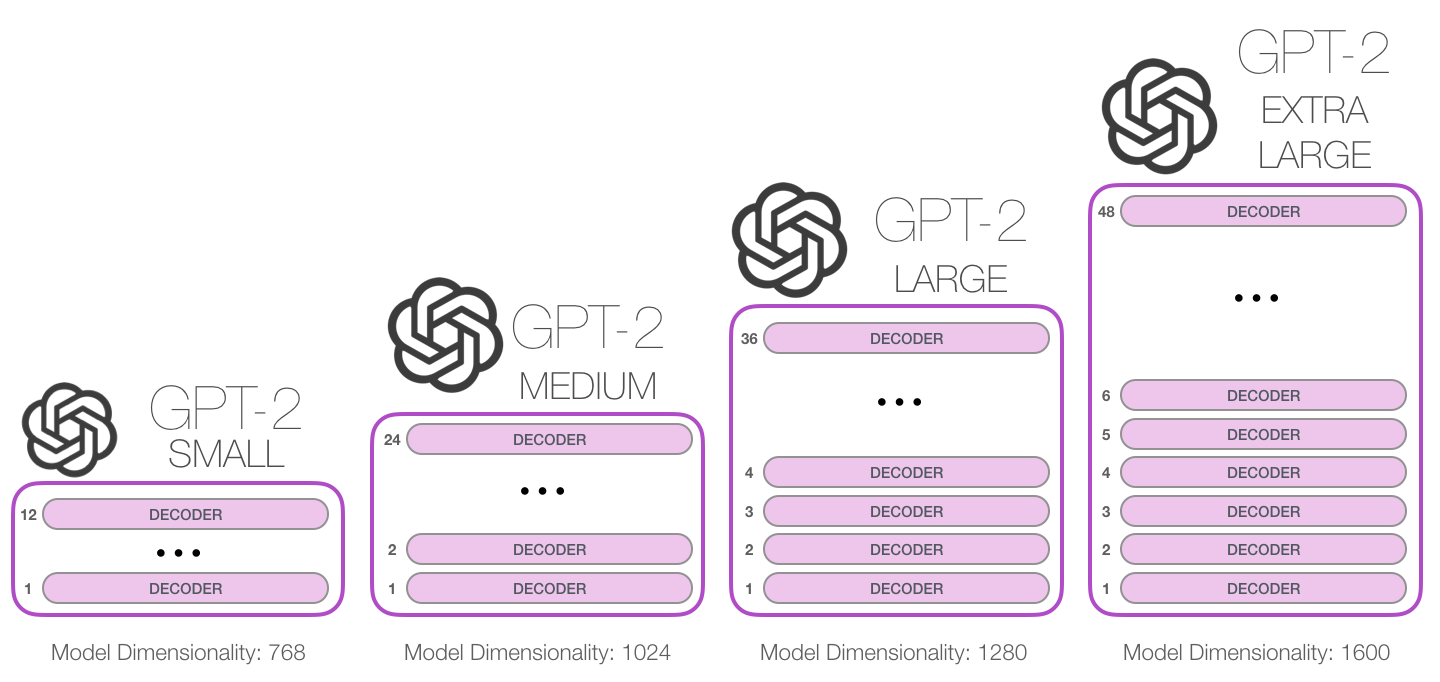
GPT - Generative Pre-trained Transformer
- GPT can be fine-tuned (transfer learning) to perform machine translation.
GPT - Generative Pre-trained Transformer
- GPT can be fine-tuned to summarize Wikipedia articles.
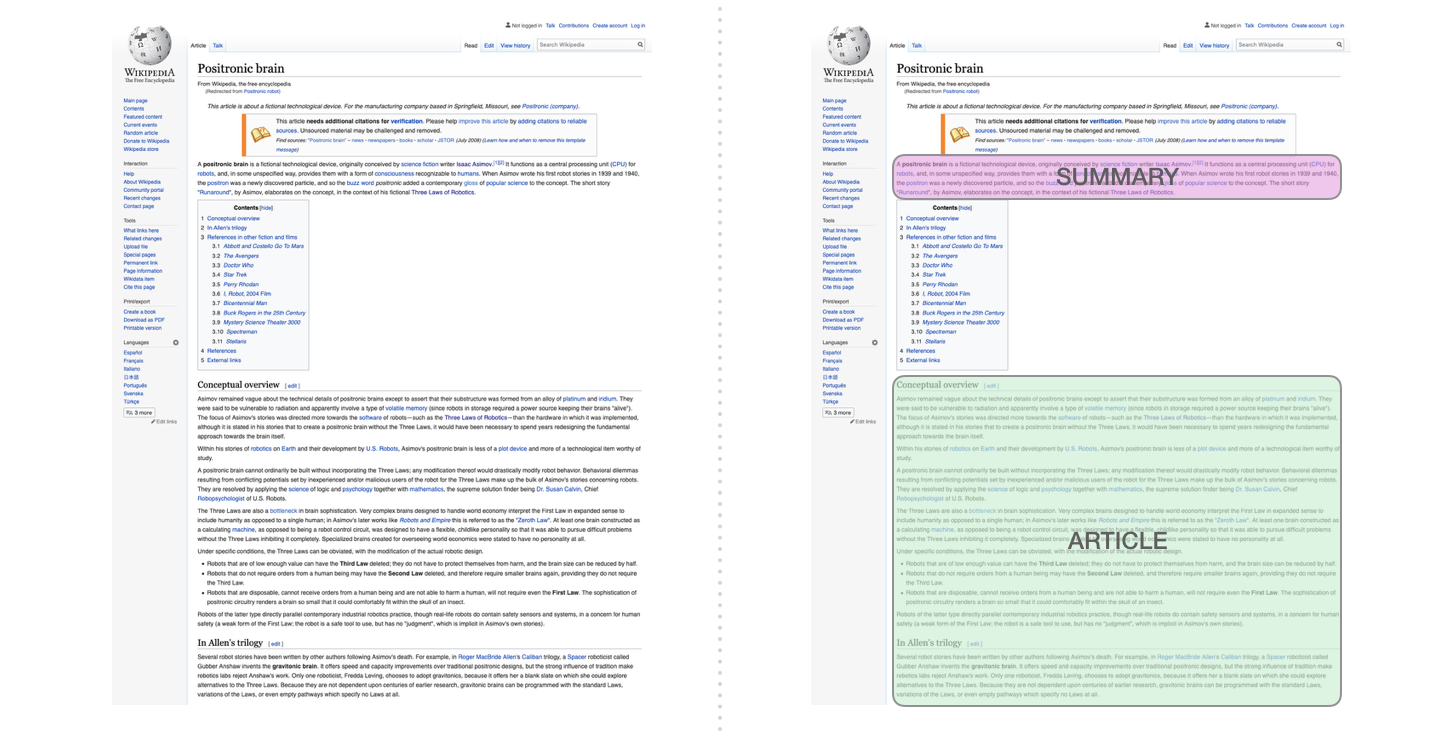
GPT - Generative Pre-trained Transformer
- GPT can be fine-tuned to summarize Wikipedia articles.
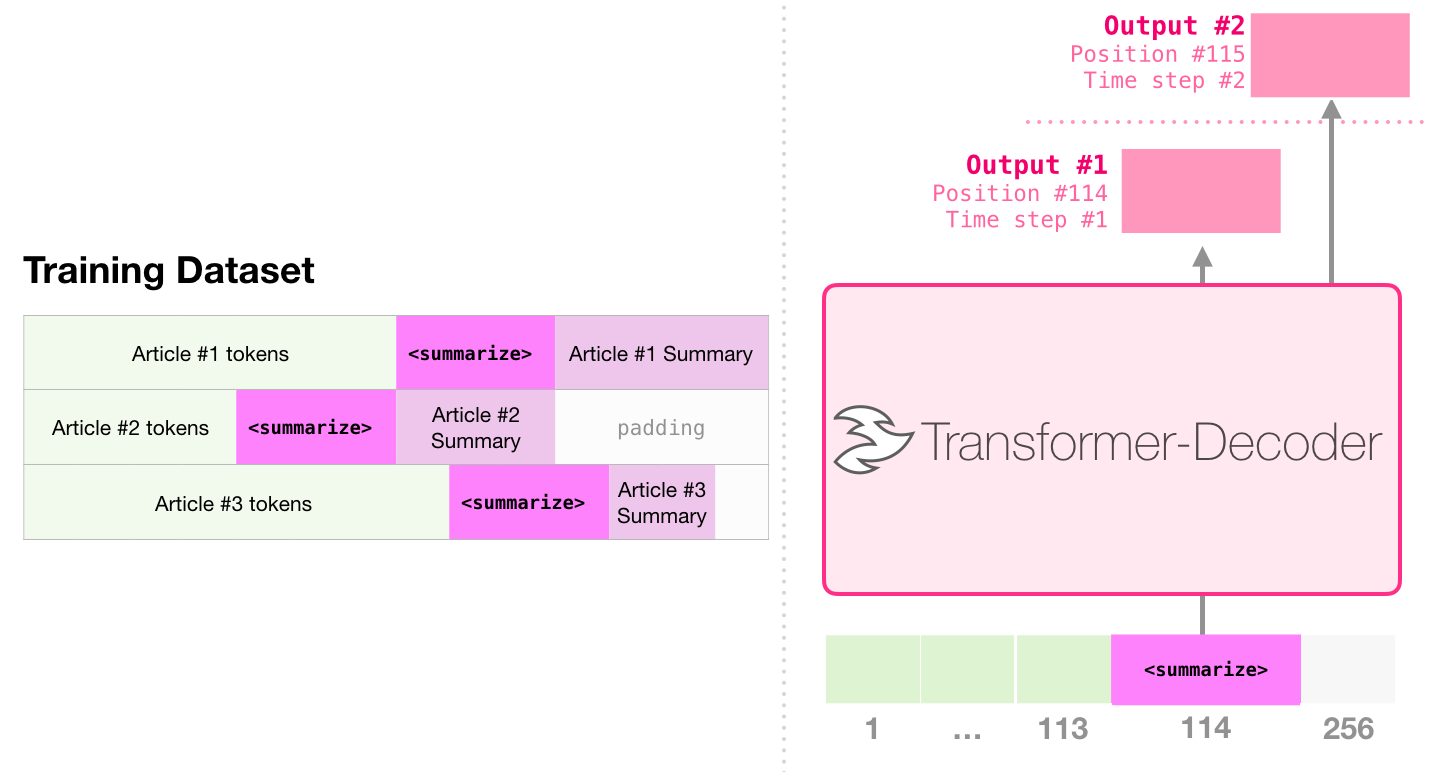
Try transformers at https://huggingface.co/
pip install transformers![]()
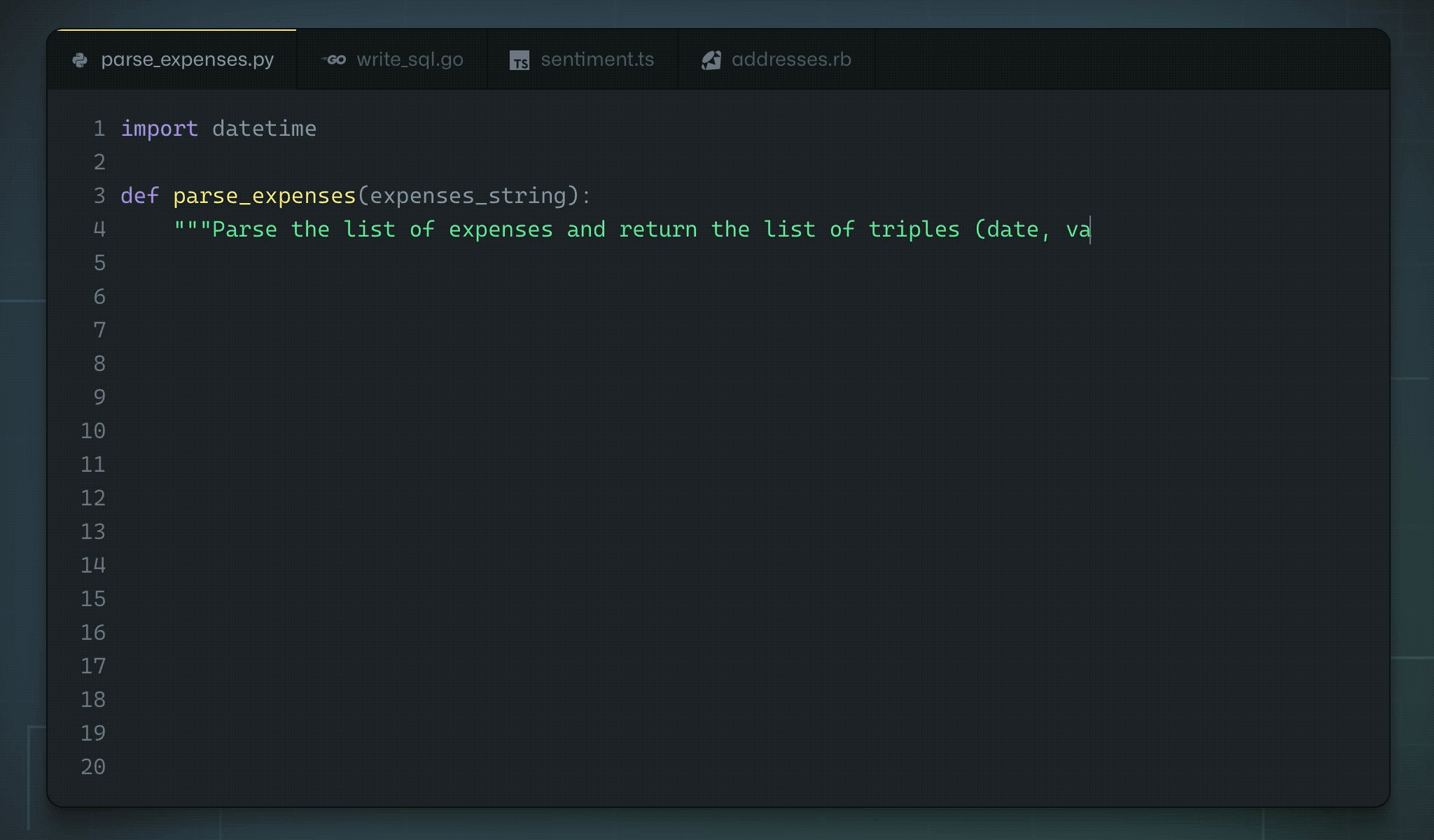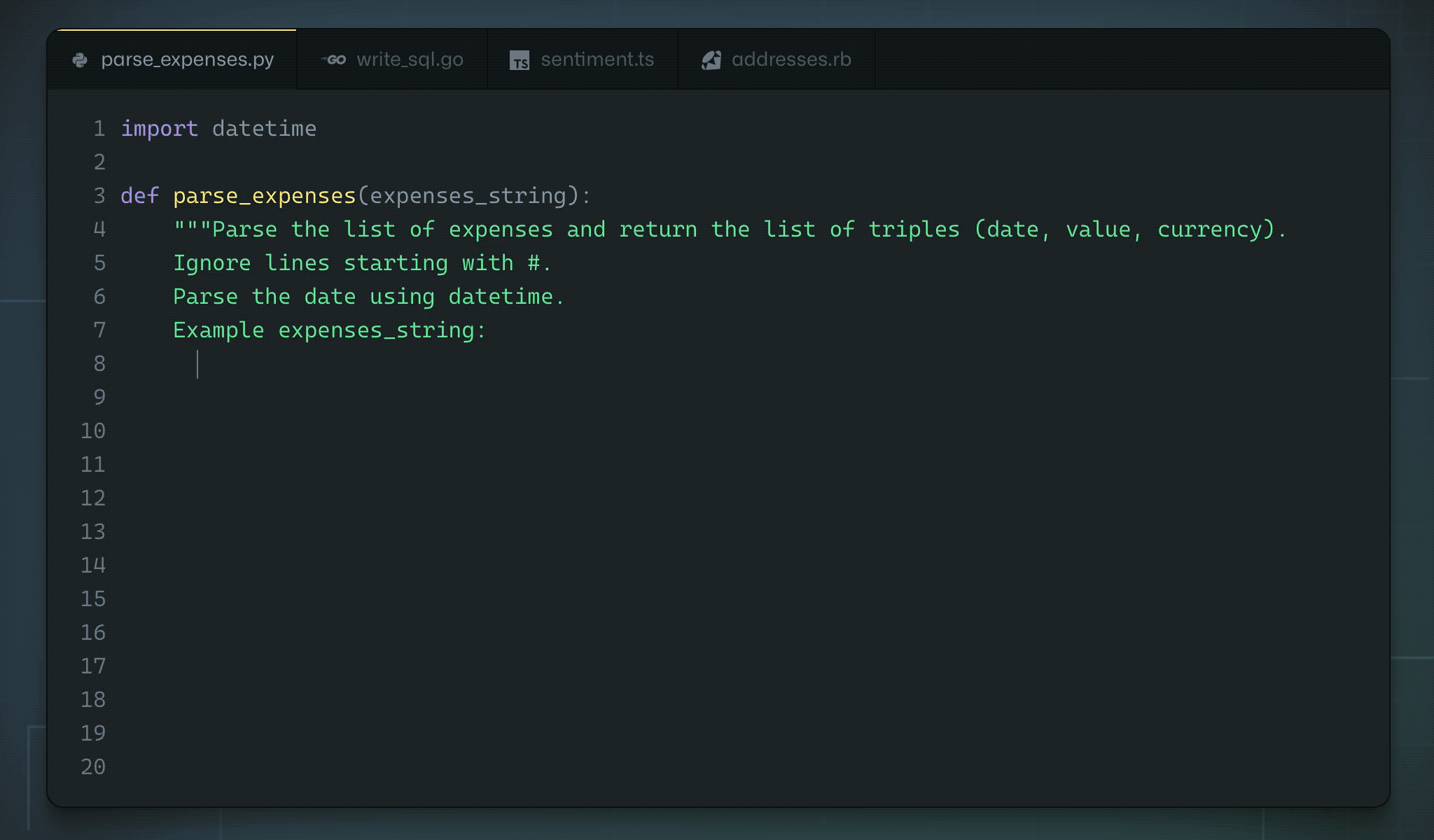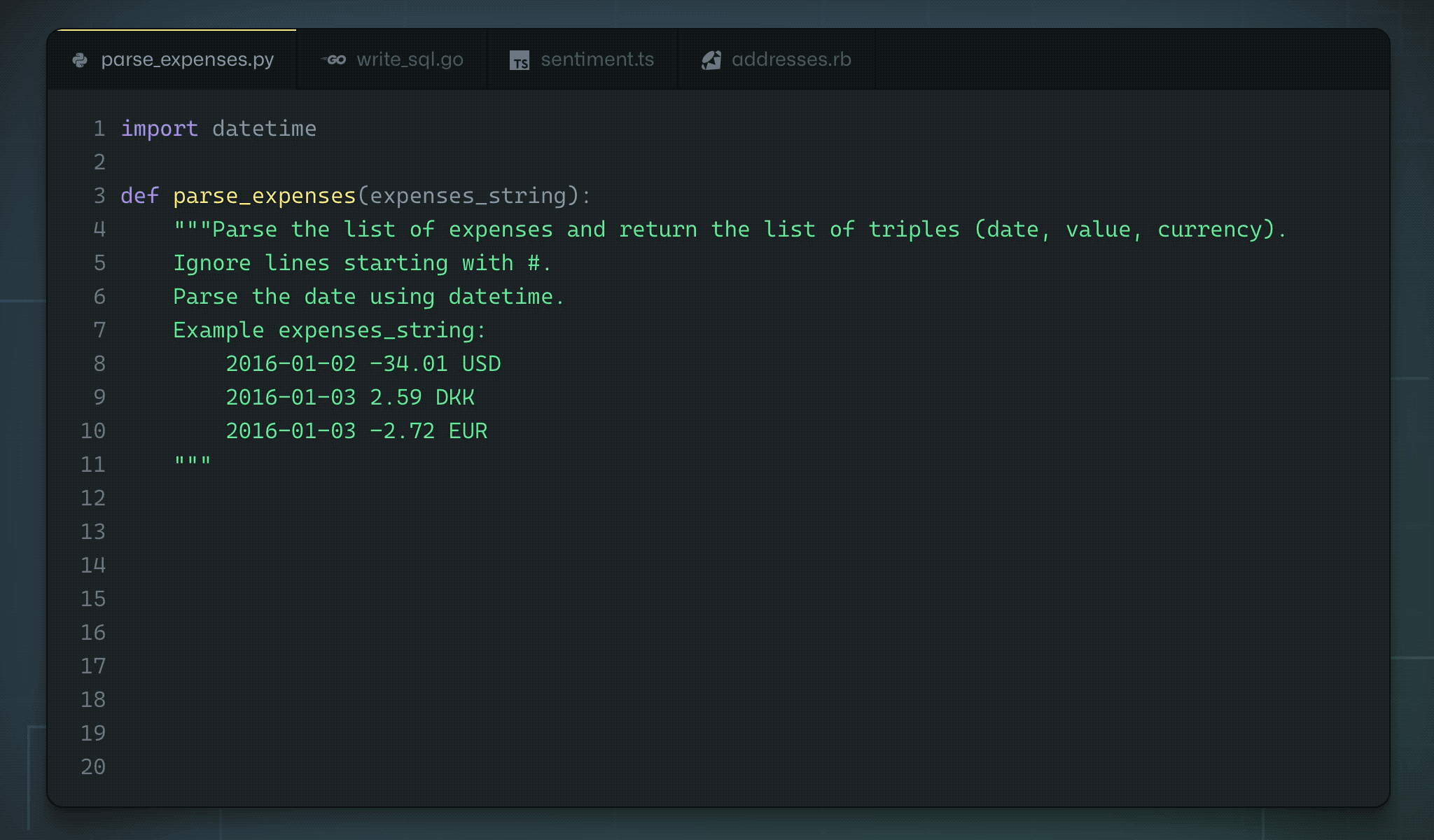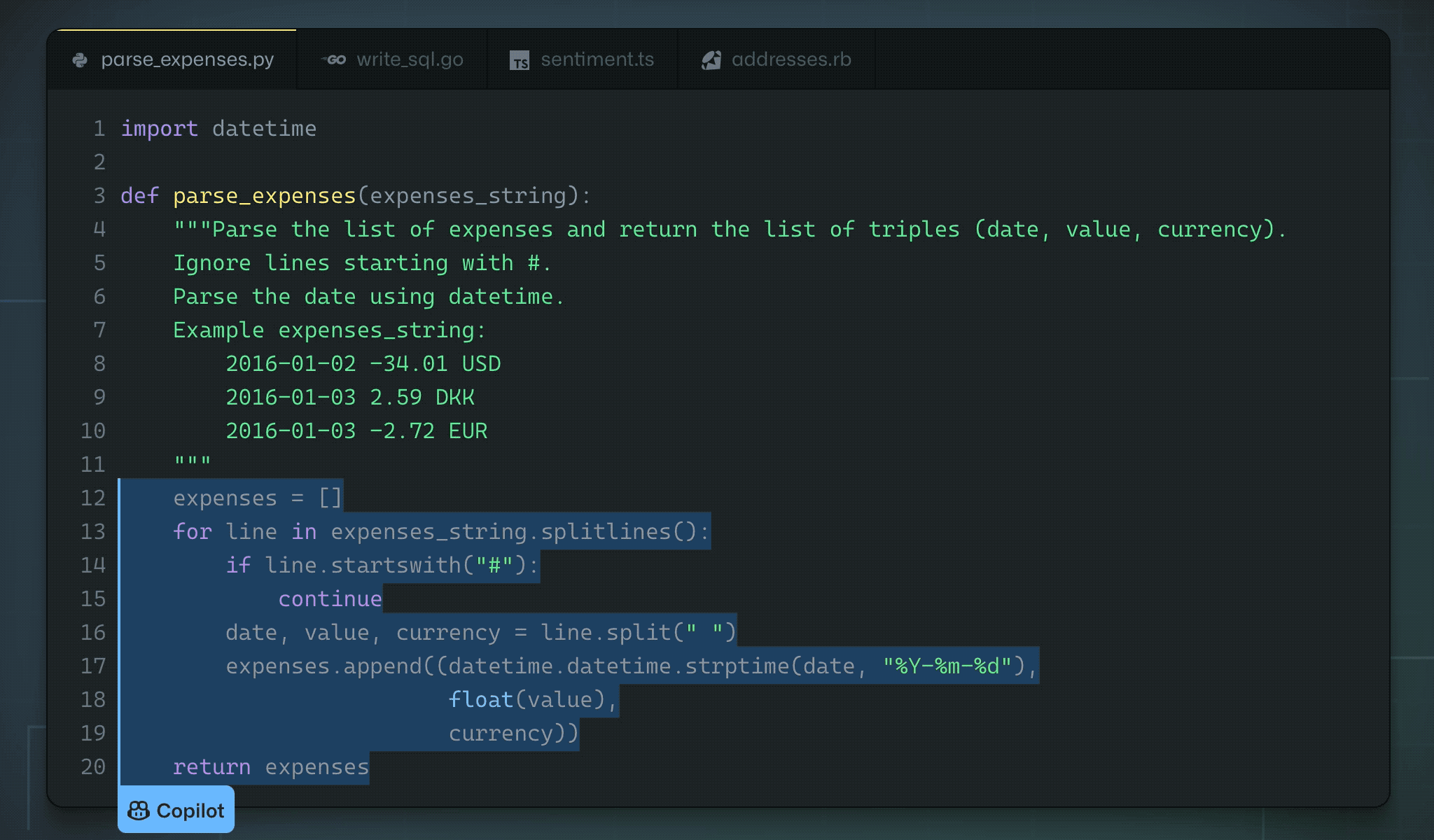
Github copilot
Github and OpenAI trained a GPT-3-like architecture on the available open source code.
Copilot is able to “autocomplete” the code based on a simple comment/docstring.
ChatGPT
Transformers and NLP
All NLP tasks (translation, sentence classification, text generation) are now done using Large Language Models (LLM), self-supervisedly pre-trained on huge corpuses.
BERT can be used for feature extraction, while GPT is more generative.
Transformer architectures seem to scale: more parameters = better performance. Is there a limit?
The price to pay is that these models are very expensive to train (training one instance of GPT-3 costs 12M$) and to use (GPT-3 is only accessible with an API).
Many attempts have been made to reduce the size of these models while keeping a satisfying performance.
- DistilBERT, RoBERTa, BART, T5, XLNet…
See https://medium.com/mlearning-ai/recent-language-models-9fcf1b5f17f5