Neurocomputing
Vision Transformers
Vision transformer (ViT)
The transformer architecture can also be applied to computer vision, by splitting images into a sequence of small patches (16x16).
The sequence of patches can then be classified using the first output of the Transformer encoder (BERT) using supervised learning on Imagenet.
Vision transformer (ViT)
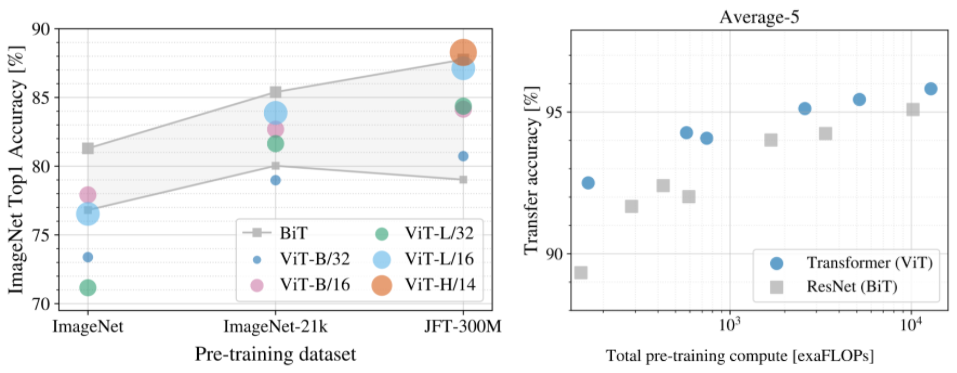
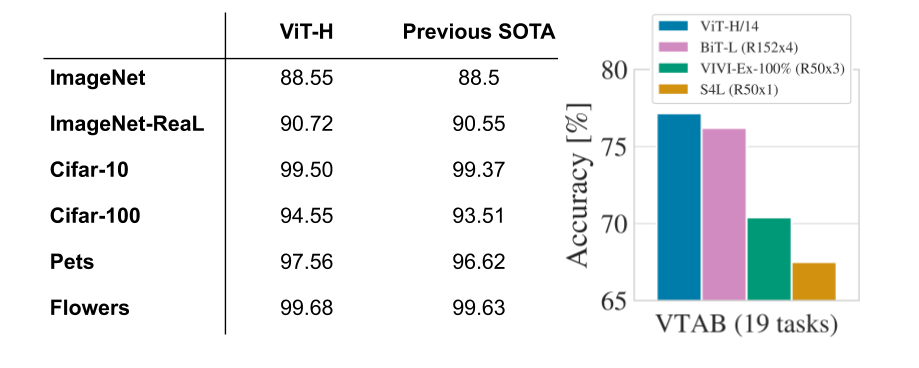
The Vision Transformer (ViT) outperforms state-of-the-art CNNs on Imagenet while requiring less computations (Flops), but only when pretrained on bigger datasets.
The performance is acceptable when trained on ImageNet (1M images), great when pre-trained on ImageNet-21k (14M images), and state-of-the-art when pre-trained on Google’s internal JFT-300M dataset (300M images).
Transfer learning on smaller datasets is also SotA.
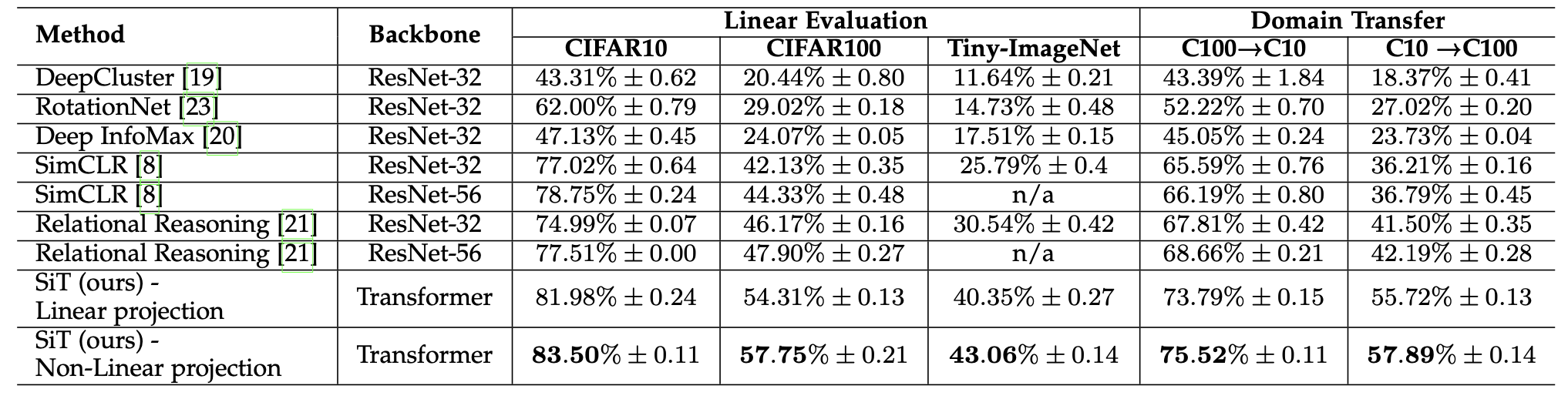
Self-supervised Vision Transformer (SiT)
ViT only works on big supervised datasets (ImageNet). Can we benefit from self-supervised learning as in BERT or GPT?
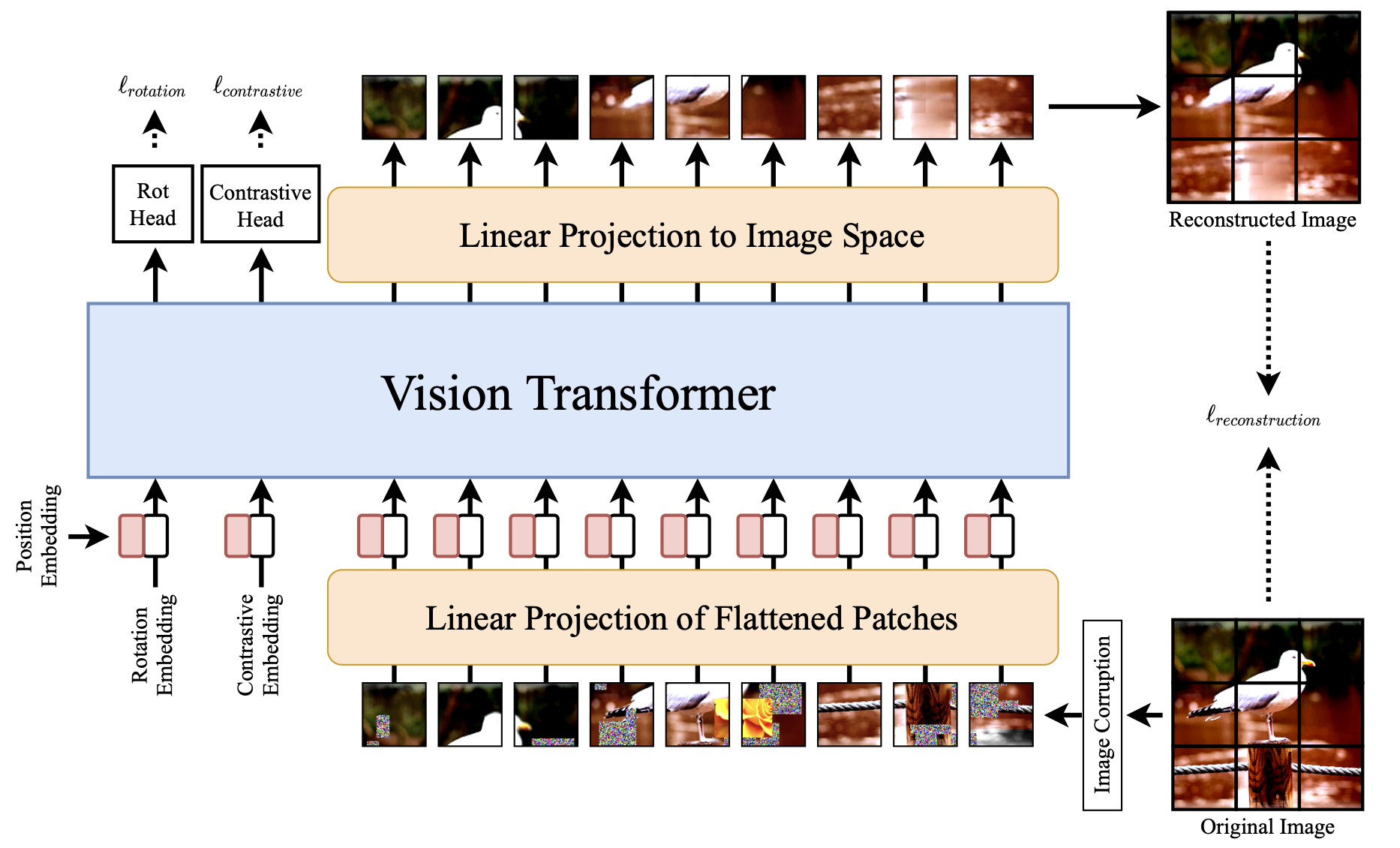
The Self-supervised Vision Transformer (SiT) has an denoising autoencoder-like structure, reconstructing corrupted patches autoregressively.
Self-supervised Vision Transformer (SiT)
- Self-supervised learning is possible through from data augmentation, where various corruptions (masking, replacing, color distortion, blurring) are applied to the input image, but SiT must reconstruct the original image (denoising autoencoder, reconstruction loss).

An auxiliary rotation loss forces SiT to predict the orientation of the image (e.g. 30°).
An auxiliary contrastive loss ensures that high-level representations are different for different images.
Self-distillation with no labels (DINO)
Another approach for self-supervised learning has been proposed by Facebook AI using self-distillation.
The images are split into global and local patches at different scales.
Global patches contain label-related information (whole objects) while local patches contain finer details.

Self-distillation with no labels (DINO)
The idea of self-distillation in DINO is to use two similar ViT networks to classify the patches.
The teacher network gets the global views as an input, while the student network get both the local and global ones.
Both have a MLP head to predict the softmax probabilities, but do not use any labels.
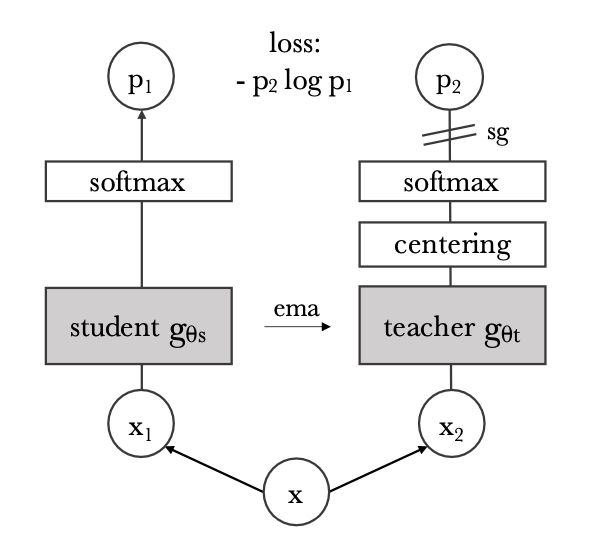
The student tries to imitate the output of the teacher, by minimizing the cross-entropy (or KL divergence) between the two probability distributions.
The teacher slowly integrates the weights of the student (momentum or exponentially moving average ema):
\theta_\text{teacher} \leftarrow \beta \, \theta_\text{teacher} + (1 - \beta) \, \theta_\text{student}
Self-distillation with no labels (DINO)

Self-distillation with no labels (DINO)
The predicted classes do not matter when pre-training, as there is no ground truth.
The only thing that matters is the high-level representation of an image before the softmax output, which can be used for transfer learning.
Self-distillation forces the representations to be meaningful at both the global and local scales, as the teacher gets global views.
ImageNet classes are already separated in the high-level representations: a simple kNN (k-nearest neighbour) classifier achieves 74.5% accuracy (vs. 79.3% for a supervised ResNet50).

Transformer for time series
Transformers can also be used for time-series classification or forecasting instead of RNNs.
Example: weather forecasting, market prices, etc.
![]()
![]()
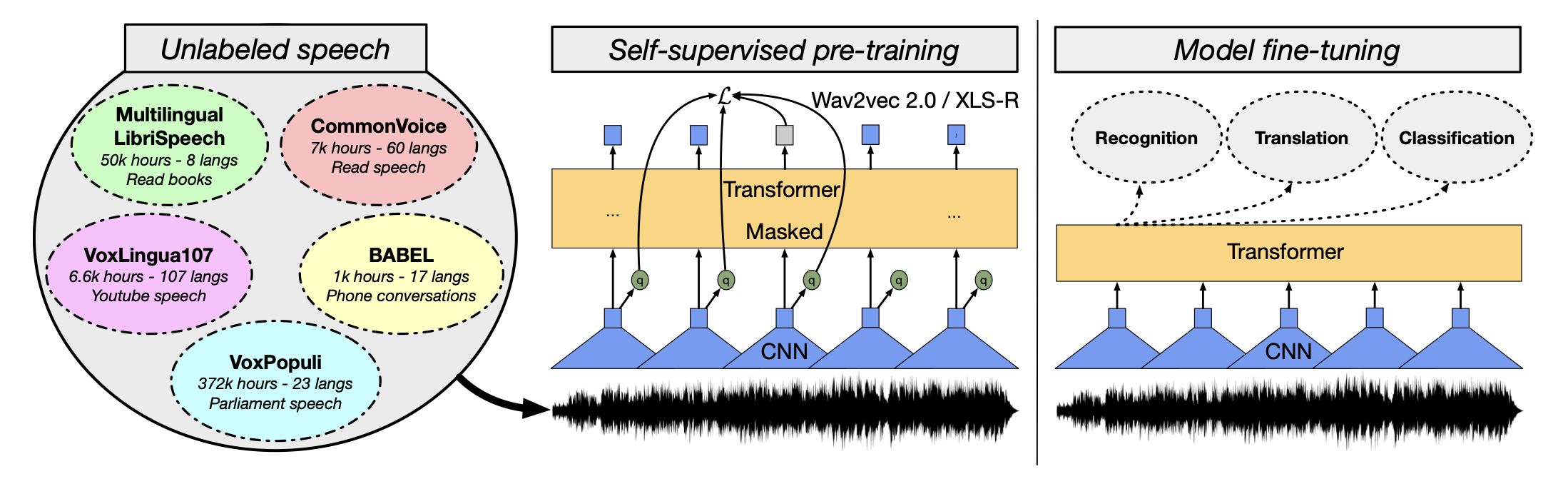
Speech processing
XLS-R from Facebook is a transformer-based architecture trained on 436,000 hours of publicly available speech recordings, from 128 languages.
Self-supervised: contrastive learning and masked language modelling.
Other models: UniSpeech, HuBERT, BigSSL…