6 Off-policy Actor-Critic
Actor-critic architectures are generally on-policy algorithms: the actions used to explore the environment must have been generated by the actor, otherwise the feedback provided by the critic (the advantage) will introduce a huge bias (i.e. an error) in the policy gradient. This comes from the definition of the policy gradient theorem:
\[ \nabla_\theta J(\theta) = \mathbb{E}_{s \sim \rho^\pi, a \sim \pi_\theta}[\nabla_\theta \log \pi_\theta(s, a) \, Q^{\pi_\theta}(s, a)] \]
The state distribution \(\rho^\pi\) defines the ensemble of states that can be visited using the actor policy \(\pi_\theta\). If, during Monte-Carlo sampling of the policy gradient, the states \(s\) do not come from this state distribution, the approximated policy gradient will be wrong (high bias) and the resulting policy will be suboptimal.
The major drawback of on-policy methods is their sample complexity: it is difficult to ensure that the “interesting” regions of the policy are actually discovered by the actor (see Figure 6.1). If the actor is initialized in a flat region of the reward space (where there is not a lot of rewards), policy gradient updates will only change slightly the policy and it may take a lot of iterations until interesting policies are discovered and fine-tuned.
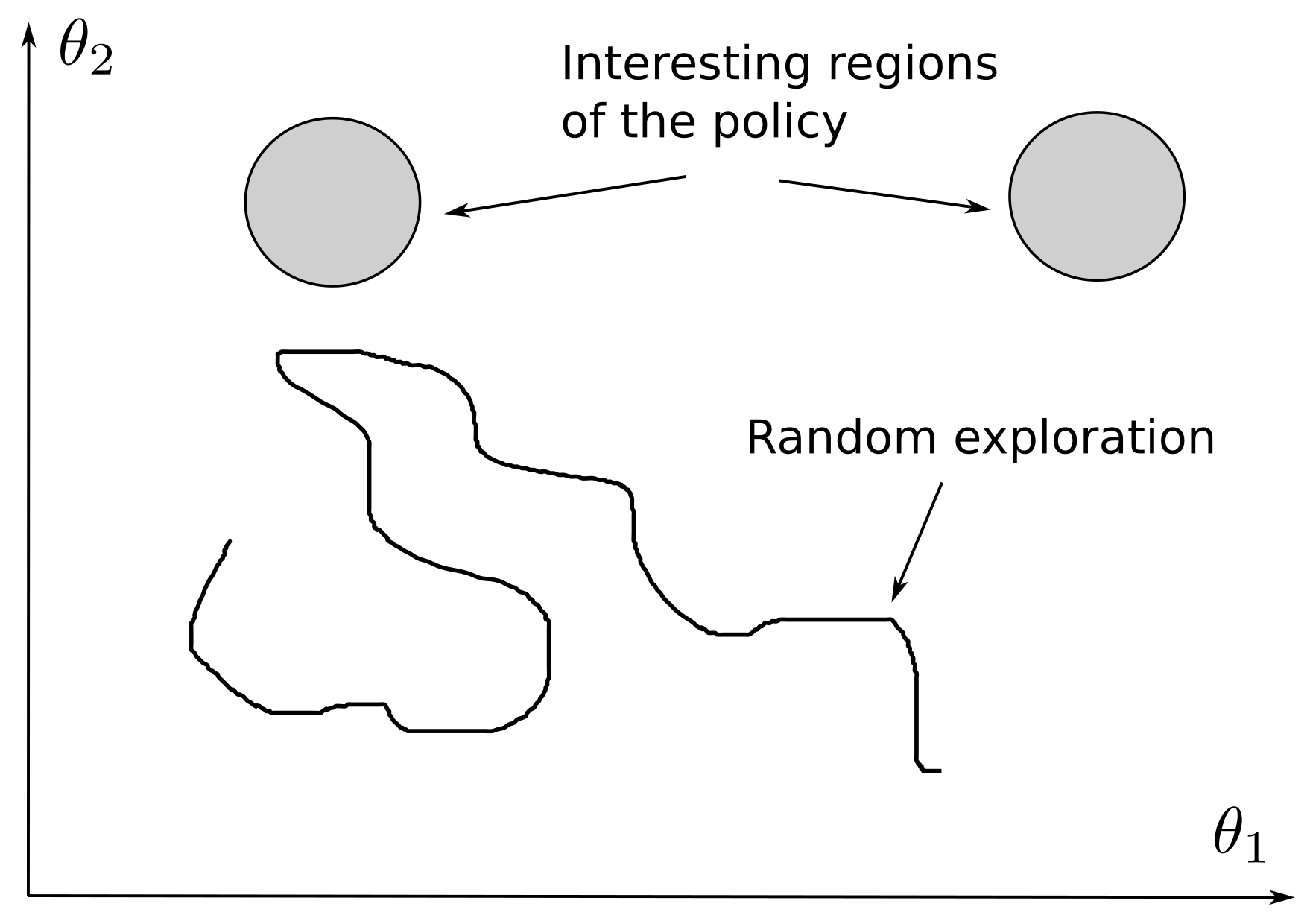
The problem becomes even worse when the state or action spaces are highly dimensional, or when rewards are sparse. Imagine the scenario where you are searching for your lost keys at home (a sparse reward is delivered only once you find them): you could spend hours trying randomly each action at your disposal (looking in your jackets, on your counter, but also jumping around, cooking something, watching TV…) until finally you explore the action “look behind the curtains” and find them. (Note: with deep RL, you would even have to do that one million times in order to allow gradient descent to train your brain…). If you had somebody telling you “if I were you, I would first search in your jackets, then on your counter and finally behind the curtains, but forget about watching TV, you will never find anything by doing that”, this would certainly reduce your exploration time.
This is somehow the idea behind off-policy algorithms: they use a behavior policy \(b(s, a)\) to explore the environment and train the target policy \(\pi(s, a)\) to reproduce the best ones by estimating how good they are. This does not come without caveats: if the behavior policy does not explore the optimal actions, the target policy will likely not be able to find it by itself, except by chance. But if the behavior policy is good enough, this can drastically reduce the amount of exploration needed to obtain a satisfying policy. Sutton and Barto (2017) noted that:
“On-policy methods are generally simpler and are considered first. Off-policy methods require additional concepts and notation, and because the data is due to a different policy, off-policy methods are often of greater variance and are slower to converge.”
The most famous off-policy method is Q-learning. The reason why it is off-policy is that it does not use the next executed action (\(a_{t+1}\)) to update the value of an action, but the greedy action in the next state, which is independent from exploration:
\[ \delta = r(s, a, s') + \gamma \, \max_{a'} Q^\pi(s', a') - Q^\pi(s, a) \]
The only condition for Q-learning to work (in the tabular case) is that the behavior policy \(b(s,a)\) must be able to explore actions which are selected by the target policy:
\[ \pi(s, a) > 0 \rightarrow b(s, a) > 0 \tag{6.1}\]
Actions which would be selected by the target policy should be selected at least from time to time by the behavior policy in order to allow their update: if the target policy thinks this action should be executed, the behavior policy should try it to confirm or infirm this assumption. In mathematical terms, there is an assumption of coverage of \(\pi\) by \(b\) (the support of \(b\) includes the one of \(\pi\)).
There are mostly two ways to create the behavior policy:
Use expert knowledge / human demonstrations. Not all available actions should be explored: the programmer already knows they do not belong to the optimal policy. When an agent learns to play chess, for example, the behavior policy could consist of the moves typically played by human experts: if chess masters play this move, it is likely to be a good action, so it should be tried out, valued and possibly incorporated into the target policy (if it is indeed a good action, experts might be wrong). A similar idea was used to bootstrap early versions of AlphaGo (Silver et al., 2016). In robotics, one could for example use “classical” engineering methods to control the exploration of the robot, while learning (hopefully) a better policy. It is also possible to perform imitation learning, where the agent learns from human demonstrations (e.g. Levine and Koltun (2013)).
Derive it from the target policy. In Q-learning, the target policy can be deterministic, i.e. always select the greedy action (with the maximum Q-value). The behavior policy can be derived from the target policy by making it \(\epsilon\)-soft, for example using a \(\epsilon\)-greedy or softmax action selection scheme on the Q-values learned by the target policy.
The second option allows to control the level of exploration during learning (by controlling \(\epsilon\) or the softmax temperature) while making sure that the target policy (the one used in production) is deterministic and optimal. It furthermore makes sure that Equation 6.1 is respected: the greedy action of the target policy always has a non-zero probability of being selected by an \(\epsilon\)-greedy or softmax action selection. This is harder to ensure using expert knowledge.
Q-learning methods such as DQN use this second option. The target policy in DQN is actually a greedy policy with respect to the Q-values (i.e. the action with the maximum Q-value will be deterministically chosen), but an \(\epsilon\)-soft behavior policy is derived from it to ensure exploration. This explains now the following comment in the description of the DQN algorithm:
- Select the action \(a_t\) based on the behavior policy derived from \(Q_\theta(s_t, a)\) (e.g. softmax).
Off-policy learning furthermore allows the use of an experience replay memory: in this case, the transitions used for training the target policy were generated by an older version of it (sometimes much older). Only off-policy methods can work with replay buffers. A3C is for example on-policy: it relies on multiple parallel learners to fight against the correlation of inputs and outputs.
6.0.1 Importance sampling
Off-policy methods learn a target policy \(\pi(s,a)\) while exploring with a behavior policy \(b(s,a)\). The environment is sampled using the behavior policy to form estimates of the state or action values (for value-based methods) or of the policy gradient (for policy gradient methods). But is it mathematically correct?
In policy gradient methods, we want to maximize the expected return of trajectories:
\[ J(\theta) = \mathbb{E}_{\tau \sim \rho_\theta}[R(\tau)] = \int_\tau \rho_\theta(\tau) \, R(\tau) \, d\tau \approx \frac{1}{N} \sum_{i=1}^N R(\tau_i) \]
where \(\rho_\theta\) is the distribution of trajectories \(\tau\) generated by the target policy \(\pi_\theta\). Mathematical expectations can be approximating by an average of enough samples of the estimator (Monte-Carlo). In policy gradient, we estimate the gradient, but let’s consider we sample the objective function for now. If we use a behavior policy to generate the trajectories, what we are actually estimating is:
\[ \hat{J}(\theta) = \mathbb{E}_{\tau \sim \rho_b}[R(\tau)] = \int_\tau \rho_b(\tau) \, R(\tau) \, d\tau \]
where \(\rho_b\) is the distribution of trajectories generated by the behavior policy. In the general case, there is no reason why \(\hat{J}(\theta)\) should be close from \(J(\theta)\), even when taking their gradient.
Importance sampling is a classical statistical method used to estimate properties of a distribution (here the expected return of the trajectories of the target policy) while only having samples generated from a different distribution (here the trajectories of the behavior policy). See for example https://statweb.stanford.edu/~owen/mc/Ch-var-is.pdf and http://timvieira.github.io/blog/post/2014/12/21/importance-sampling for more generic explanations.
The trick is simply to rewrite the objective function as:
\[ \begin{aligned} J(\theta) & = \mathbb{E}_{\tau \sim \rho_\theta}[R(\tau)] \\ & = \int_\tau \rho_\theta(\tau) \, R(\tau) \, d\tau \\ & = \int_\tau \frac{\rho_b(\tau)}{\rho_b(\tau)} \, \rho_\theta(\tau) \, R(\tau) \, d\tau \\ & = \int_\tau \rho_b(\tau) \frac{\rho_\theta(\tau)}{\rho_b(\tau)} \, R(\tau) \, d\tau \\ & = \mathbb{E}_{\tau \sim \rho_b}[\frac{\rho_\theta(\tau)}{\rho_b(\tau)} \, R(\tau)] \\ \end{aligned} \]
The ratio \(\frac{\rho_\theta(\tau)}{\rho_b(\tau)}\) is called the importance sampling weight for the trajectory. If a trajectory generated by \(b\) is associated with a lot of rewards \(R(\tau)\) (with \(\rho_b(\tau)\) significantly high), the actor should learn to reproduce that trajectory with a high probability \(\rho_\theta(\tau)\), as its goal is to maximize \(J(\theta)\). Conversely, if the associated reward is low (\(R(\tau)\approx 0\)), the target policy can forget about it (by setting \(\rho_\theta(\tau) = 0\)), even though the behavior policy still generates it!
The problem is now to estimate the importance sampling weight. Using the definition of the likelihood of a trajectory, the importance sampling weight only depends on the policies, not the dynamics of the environment (they cancel out):
\[ \frac{\rho_\theta(\tau)}{\rho_b(\tau)} = \frac{p_0 (s_0) \, \prod_{t=0}^T \pi_\theta(s_t, a_t) p(s_{t+1} | s_t, a_t)}{p_0 (s_0) \, \prod_{t=0}^T b(s_t, a_t) p(s_{t+1} | s_t, a_t)} = \frac{\prod_{t=0}^T \pi_\theta(s_t, a_t)}{\prod_{t=0}^T b(s_t, a_t)} = \prod_{t=0}^T \frac{\pi_\theta(s_t, a_t)}{b(s_t, a_t)} \]
This allows to estimate the objective function \(J(\theta)\) using Monte Carlo sampling (Meuleau et al., 2000; Peshkin and Shelton, 2002):
\[ J(\theta) \approx \frac{1}{m} \, \sum_{i=1}^m \frac{\rho_\theta(\tau_i)}{\rho_b(\tau_i)} \, R(\tau_i) \]
All one needs to do is to repeatedly apply the following algorithm:
Generate \(m\) trajectories \(\tau_i\) using the behavior policy:
For each transition \((s_t, a_t, s_{t+1})\) of each trajectory, store:
The received reward \(r_{t+1}\).
The probability \(b(s_t, a_t)\) that the behavior policy generates this transition.
The probability \(\pi_\theta(s_t, a_t)\) that the target policy generates this transition.
Estimate the objective function with:
\[ \hat{J}(\theta) = \frac{1}{m} \, \sum_{i=1}^m \left(\prod_{t=0}^T \frac{\pi_\theta(s_t, a_t)}{b(s_t, a_t)} \right) \, \left(\sum_{t=0}^T \gamma^t \, r_{t+1} \right) \]
- Update the target policy to maximize \(\hat{J}(\theta)\).
Tang and Abbeel (2010) showed that the same idea can be applied to the policy gradient, under assumptions often met in practice:
\[ \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \rho_b}[ \nabla_\theta \log \rho_\theta(\tau) \, \frac{\rho_\theta(\tau)}{\rho_b(\tau)} \, R(\tau)] \]
When decomposing the policy gradient for each state encountered, one can also use the causality principle to simplify the terms:
The return after being in a state \(s_t\) only depends on future states.
The importance sampling weight (relative probability of arriving in \(s_t\) using the behavior and target policies) only depends on the past weights.
This gives the following approximation of the policy gradient, used for example in Guided policy search (Levine and Koltun, 2013):
\[ \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \rho_b}[ \sum_{t=0}^T \nabla_\theta \log \pi_\theta(s_t, a_t) \, \left(\prod_{t'=0}^t \frac{\pi_\theta(s_{t'}, a_{t'})}{b(s_{t'}, a_{t'})} \right) \, \left(\sum_{t'=t}^T \gamma^{t'-t} \, r(s_{t'}, a_{t'}) \right)] \]
6.0.2 Linear Off-Policy Actor-Critic (Off-PAC)
The first off-policy actor-critic method was proposed by Degris et al. (2012) for linear approximators. Another way to express the objective function in policy search is by using the Bellman equation (here in the off-policy setting):
\[ J(\theta) = \mathbb{E}_{s \sim \rho_b} [V^{\pi_\theta}(s)] = \mathbb{E}_{s \sim \rho_b} [\sum_{a\in\mathcal{A}} \pi(s, a) \, Q^{\pi_\theta}(s, a)] \]
Maximizing the value of all states reachable by the policy is the same as finding the optimal policy: the encoutered states bring the maximum return. The policy gradient becomes:
\[ \nabla_\theta J(\theta) = \mathbb{E}_{s \sim \rho_b} [\sum_{a\in\mathcal{A}} \nabla_\theta (\pi_\theta(s, a) \, Q^{\pi_\theta}(s, a))] \]
Because both \(\pi(s, a)\) and \(Q^\pi(s, a)\) depend on the target policy \(\pi_\theta\) (hence its parameters \(\theta\)), one should normally write:
\[ \nabla_\theta (\pi_\theta(s, a) \, Q^{\pi_\theta}(s, a)) = Q^{\pi_\theta}(s, a) \, \nabla_\theta \pi_\theta(s, a) + \pi_\theta(s, a) \, \nabla_\theta Q^{\pi_\theta}(s, a) \]
The second term depends on \(\nabla_\theta Q^{\pi_\theta}(s, a)\), which is very difficult to estimate. Degris et al. (2012) showed that when the Q-values are estimated by an unbiased critic \(Q_\varphi(s, a)\), this second term can be omitted. Using the log-trick and importance sampling, the policy gradient can be expressed as:
\[ \begin{aligned} \nabla_\theta J(\theta) & = \mathbb{E}_{s \sim \rho_b} [\sum_{a\in\mathcal{A}} Q_\varphi(s, a) \, \nabla_\theta \pi_\theta(s, a)] \\ & = \mathbb{E}_{s \sim \rho_b} [\sum_{a\in\mathcal{A}} b(s, a) \, \frac{\pi_\theta(s, a)}{b(s, a)} \, Q_\varphi(s, a) \, \frac{\nabla_\theta \pi_\theta(s, a)}{\pi_\theta(s, a)}] \\ & = \mathbb{E}_{s,a \sim \rho_b} [\frac{\pi_\theta(s, a)}{b(s, a)} \, Q_\varphi(s, a) \, \nabla_\theta \log \pi_\theta(s, a)] \\ \end{aligned} \]
We now have an actor-critic architecture (actor \(\pi_\theta(s, a)\), critic \(Q_\varphi(s, a)\)) able to learn from single transitions \((s,a)\) (online update instead of complete trajectories) generated off-policy (behavior policy \(b(s,a)\) and importance sampling weight \(\frac{\pi_\theta(s, a)}{b(s, a)}\)). The off-policy actor-critic (Off-PAC) algorithm of Degris et al. (2012) furthermore uses eligibility traces to stabilize learning. However, it was limited to linear function approximators because its variance is too high to train deep neural networks.
6.0.3 Retrace
For a good deep RL algorithm, we need the two following properties:
Off-policy learning: it allows to learn from transitions stored in a replay buffer (i.e. generated with an older policy). As NN need many iterations to converge, it is important to be able to re-use old transitions for its training, instead of constantly sampling new ones (sample complexity). Multiple parallel actors as in A3C allow to mitigate this problem, but it is still too complex.
Multi-step returns: the two extremes of RL are TD (using a single “real” reward for the update, the rest is estimated) and Monte-Carlo (use only “real” rewards, no estimation). TD has a smaller variance, but a high bias (errors in estimates propagate to all other values), while MC has a small bias but a high variance (learns from many real rewards, but the returns may vary a lot between two almost identical episodes). Eligibility traces and n-step returns (used in A3C) are the most common trade-off between TD and MC.
The Retrace algorithm (Munos et al., 2016) is designed to exhibit both properties when learning Q-values. It can therefore be used to train the critic (instead of classical Q-learning) and provide the actor with safe, efficient and low-variance values.
In the generic form, Q-learning updates the Q-value of a transition \((s_t, a_t)\) using the TD error:
\[ \Delta Q^\pi(s_t, a_t) = \alpha \, \delta_t = \alpha \, (r_{t+1} + \gamma \, \max_a Q^\pi(s_{t+1}, a_{t+1}) - Q^\pi(s_t, a_t)) \]
When using eligibility traces in the forward view, the change in Q-value depends also on the TD error of future transitions at times \(t' > t\). A parameter \(\lambda\) ensures the stability of the update:
\[ \Delta Q^\pi(s_t, a_t) = \alpha \, \sum_{t'=t}^T (\gamma \lambda)^{t'-t} \delta_{t'} \]
The Retrace algorithm proposes to generalize this formula using a parameter \(c_s\) for each time step between \(t\) and \(t'\):
\[ \Delta Q^\pi(s_t, a_t) = \alpha \, \sum_{t'=t}^T (\gamma)^{t'-t} \left(\prod_{s=t+1}^{t'} c_s \right) \, \delta_{t'} \]
Depending on the choice of \(c_s\), the formula covers different existing methods:
- \(c_s = \lambda\) is the classical eligibility trace mechanism (\(Q(\lambda)\)) in its forward view, which is not safe: the behavior policy \(b\) must be very close from the target policy \(\tau\):
\[ || \pi - b ||_1 \leq \frac{1 - \gamma}{\lambda \gamma} \]
As \(\gamma\) is typically chosen very close from 1 (e.g. 0.99), this does not leave much room for the target policy to differ from the behavior policy (see Harutyunyan et al., 2016 for the proof).
\(c_s = \frac{\pi(s_s, a_s)}{b(s_s, a_s)}\) is the importance sampling weight. Importance sampling is unbiased in off-policy settings, but can have a very large variance: the product of ratios \(\prod_{s=t+1}^{t'} \frac{\pi(s_s, a_s)}{b(s_s, a_s)}\) can quickly vary between two episodes.
\(c_s = \pi(s_s, a_s)\) corresponds to the tree-backup algorithm \(TB(\lambda)\) (Precup et al., 2000). It has the advantage to work for arbitrary policies \(\pi\) and \(b\), but the product of such probabilities decays very fast to zero when the time difference \(t' - t\) increases: TD errors will be efficiently shared over a couple of steps only.
For Retrace, Munos et al. (2016) showed that a much better value for \(c_s\) is:
\[ c_s = \lambda \min (1, \frac{\pi(s_s, a_s)}{b(s_s, a_s)}) \]
The importance sampling weight is clipped to 1, and decays exponentially with the parameter \(\lambda\). It can be seen as a trade-off between importance sampling and eligibility traces. The authors showed that Retrace(\(\lambda\)) has a low variance (as it uses multiple returns), is safe (works for all \(\pi\) and \(b\)) and efficient (it can propagate rewards over many time steps). They used retrace to learn Atari games and compared it positively with DQN, both in terms of optimality and speed of learning. These properties make Retrace particularly suited for deep RL and actor-critic architectures: it is for example used in ACER and the Reactor.
Rémi Munos uploaded some slides explaining Retrace in a simpler manner than in the original paper: https://ewrl.files.wordpress.com/2016/12/munos.pdf.
6.0.4 Self-Imitation Learning (SIL)
We have discussed or now only strictly on-policy or off-policy methods. Off-policy methods are much more stable and efficient, but they learn generally a deterministic policy, what can be problematic in stochastic environments (e.g. two players games: being predictable is clearly an issue). Hybrid methods combining on- and off-policy mechanisms have clearly a great potential.
Oh et al. (2018) proposed a Self-Imitation Learning (SIL) method that can extend on-policy actor-critic algorithms (e.g. A2C) with a replay buffer able to feed past good experiences to the NN to speed up learning.
The main idea is to use prioritized experience replay (Schaul et al. (2015)) to select only transitions whose actual return is higher than their current expected value. This defines two additional losses for the actor and the critic:
\[ \mathcal{L}^\text{SIL}_\text{actor}(\theta) = \mathbb{E}_{s, a \in \mathcal{D}}[\log \pi_\theta(s, a) \, (R(s, a) - V_\varphi(s))^+] \] \[ \mathcal{L}^\text{SIL}_\text{critic}(\varphi) = \mathbb{E}_{s, a \in \mathcal{D}}[((R(s, a) - V_\varphi(s))^+)^2] \]
where \((x)^+ = \max(0, x)\) is the positive function. Transitions sampled from the replay buffer will participate to the off-policy learning only if their return is higher that the current value of the state, i.e. if they are good experiences compared to what is currently known (\(V_\varphi(s)\)). The pseudo-algorithm is actually quite simple and simply extends the A2C procedure:
Initialize the actor \(\pi_\theta\) and the critic \(V_\varphi\) with random weights.
Initialize the prioritized experience replay buffer \(\mathcal{D}\).
Observe the initial state \(s_0\).
for \(t \in [0, T_\text{total}]\):
Initialize empty episode minibatch.
for \(k \in [0, n]\): # Sample episode
Select a action \(a_k\) using the actor \(\pi_\theta\).
Perform the action \(a_k\) and observe the next state \(s_{k+1}\) and the reward \(r_{k+1}\).
Store \((s_k, a_k, r_{k+1})\) in the episode minibatch.
if \(s_n\) is not terminal: set \(R_n = V_\varphi(s_n)\) with the critic, else \(R_n=0\).
for \(k \in [n-1, 0]\): # Backwards iteration over the episode
- Update the discounted sum of rewards \(R_k = r_k + \gamma \, R_{k+1}\) and store it in the replay buffer \(\mathcal{D}\).
Update the actor and the critic on-policy with the episode:
\[ \theta \leftarrow \theta + \eta \, \sum_k \nabla_\theta \log \pi_\theta(s_k, a_k) \, (R_k - V_\varphi(s_k)) \]
\[ \varphi \leftarrow \varphi + \eta \, \sum_k \nabla_\varphi (R - V_\varphi(s_k))^2 \]
for \(m \in [0, M]\):
Sample a minibatch of K transitions \((s_k, a_k, R_k)\) from the replay buffer \(\mathcal{D}\) prioritized with high \((R_k - V_\varphi(s_k))\).
Update the actor and the critic off-policy with self-imitation.
\[ \theta \leftarrow \theta + \eta \, \sum_k \nabla_\theta \log \pi_\theta(s_k, a_k) \, (R_k - V_\varphi(s_k))^+ \]
\[ \varphi \leftarrow \varphi + \eta \, \sum_k \nabla_\varphi ((R_k - V_\varphi(s_k))^+)^2 \]
In the paper, they furthermore used entropy regularization as in A3C. They showed that A2C+SIL has a better performance both on Atari games and continuous control problems (Mujoco) than state-of-the art methods (A3C, TRPO, Reactor, PPO). It shows that self-imitation learning can be very useful in problems where exploration is hard: a proper level of exploitation of past experiences actually fosters a deeper exploration of environment.