Deep Deterministic Policy Gradient (DDPG)
So far, the actor produces a stochastic policy \pi_\theta(s) assigning probabilities to each discrete action or necessitating sampling in some distribution for continuous actions. The main advantage is that stochastic policies ensure exploration of the state-action space: as most actions have a non-zero probability of being selected, we should not miss any important reward which should be ignored if the greedy action is always selected (exploration/exploitation dilemma).
There are however two drawbacks:
- The policy gradient theorem only works on-policy: the value of an action estimated by the critic must have been produced recently by the actor, otherwise the bias would increase dramatically (but see Section Off-policy Actor-Critic). This prevents the use of an experience replay memory as in DQN to stabilize learning. Importance sampling can help, but is unstable for long trajectories.
- Because of the stochasticity of the policy, the returns may vary considerably between two episodes generated by the same optimal policy. This induces a lot of variance in the policy gradient, which explains why policy gradient methods have a worse sample complexity than value-based methods: they need more samples to get rid of this variance.
Successful value-based methods such as DQN produce a deterministic policy, where the action to be executed after learning is simply the greedy action a^*_t = \text{argmax}_a Q_\theta(s_t, a). Exploration is enforced by forcing the behavior policy (the one used to generate the samples) to be stochastic (\epsilon-greedy), but the learned policy is itself deterministic. This is off-policy learning, allowing to use a different policy than the learned one to explore. When using an experience replay memory, the behavior policy is simply an older version of the learning policy (as samples stored in the ERM were generated by an older version of the actor).
In this section, we will see the now state-of-the-art method DDPG (Deep Deterministic Policy Gradient), which tries to combine the advantages of policy gradient methods (actor-critic, continuous or highly dimensional outputs, stability) with those of value-based methods (sample efficiency, off-policy).
Deterministic policy gradient theorem
We now assume that we want to learn a parameterized deterministic policy \mu_\theta(s). As for the stochastic policy gradient theorem, the goal is to maximize the expectation over all states reachable by the policy of the reward to-go (return) after each action:
J(\theta) = \mathbb{E}_{s \sim \rho_\mu}[R(s, \mu_\theta(s))]
As in the stochastic case, the distribution of states reachable by the policy \rho_\mu is impossible to estimate, so we will have to perform approximations. Building on Hafner and Riedmiller (2011), Silver et al. (2014) showed how to obtain a usable gradient for the objective function when the policy is deterministic.
Considering that the Q-value of an action is the expectation of the reward to-go after that action Q^\pi(s, a) = \mathbb{E}_\pi[R(s, a)], maximizing the returns or maximizing the true Q-value of all actions leads to the same optimal policy. This is the basic idea behind dynamic programming, where policy evaluation first finds the true Q-value of all state-action pairs and policy improvement changes the policy by selecting the action with the maximal Q-value a^*_t = \text{argmax}_a Q_\theta(s_t, a).
In the continuous case, we will simply state that the gradient of the objective function is the same as the gradient of the Q-value. Supposing we have an unbiased estimate Q^\mu(s, a) of the value of any action in s, changing the policy \mu_\theta(s) in the direction of \nabla_\theta Q^\mu(s, a) leads to an action with a higher Q-value, therefore with a higher associated return:
\nabla_\theta J(\theta) = \mathbb{E}_{s \sim \rho_\mu}[\nabla_\theta Q^\mu(s, a) |_{a = \mu_\theta(s)}]
This notation means that the gradient w.r.t a of the Q-value is taken at a = \mu_\theta(s). We now use the chain rule to expand the gradient of the Q-value:
\nabla_\theta J(\theta) = \mathbb{E}_{s \sim \rho_\mu}[\nabla_\theta \mu_\theta(s) \times \nabla_a Q^\mu(s, a) |_{a = \mu_\theta(s)}]
It is perhaps clearer using partial derivatives and simplifying the notations:
\frac{\partial Q(s,a)}{\partial \theta} = \frac{\partial Q(s,a)}{\partial a} \times \frac{\partial a}{\partial \theta}
The first term defines of the Q-value of an action changes when one varies slightly the action (if I move my joint a bit more to the right, do I get a higher Q-value, hence more reward?), the second term defines how the action changes when the parameters \theta of the actor change (which weights should be changed in order to produce that action with a slightly higher Q-value?).
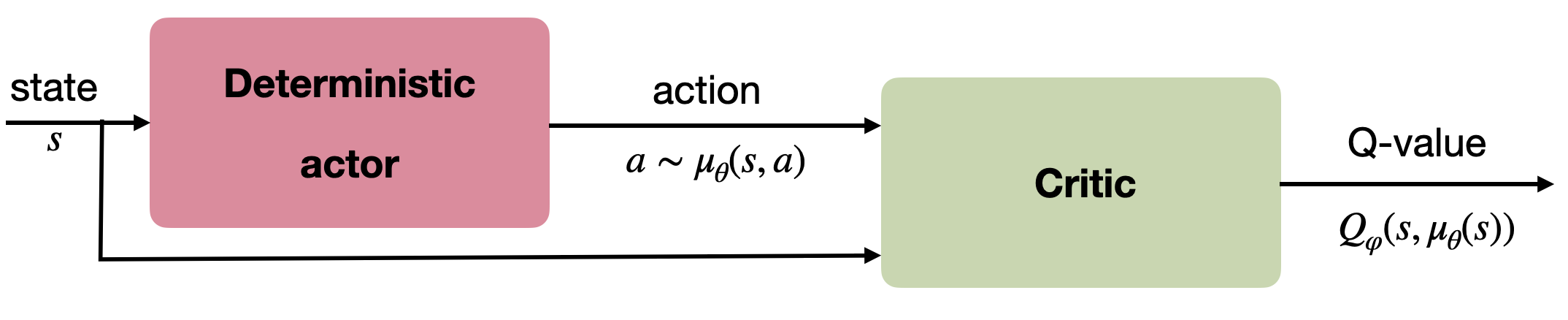
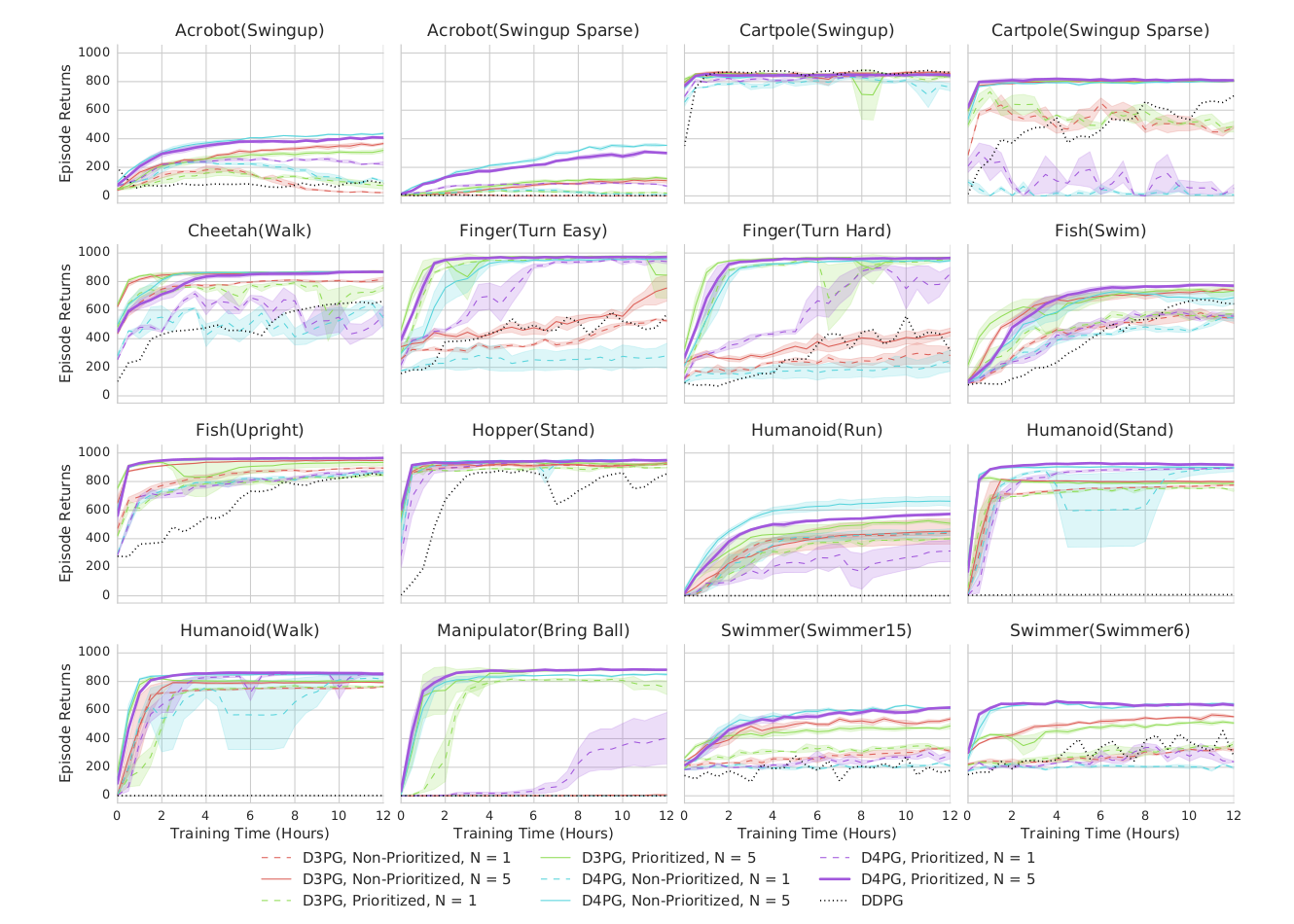
We already see an actor-critic architecture emerging from this equation: \nabla_\theta \mu_\theta(s) only depends on the parameterized actor, while \nabla_a Q^\mu(s, a) is a sort of critic, telling the actor in which direction to change its policy: towards actions associated with more reward.
As in the stochastic policy gradient theorem, the question is now how to obtain an unbiased estimate of the Q-value of any action and compute its gradient. Silver et al. (2014) showed that it is possible to use a function approximator Q_\varphi(s, a) as long as it is compatible and minimize the quadratic error with the true Q-values:
\nabla_\theta J(\theta) = \mathbb{E}_{s \sim \rho_\mu}[\nabla_\theta \mu_\theta(s) \times \nabla_a Q_\varphi(s, a) |_{a = \mu_\theta(s)}] J(\varphi) = \mathbb{E}_{s \sim \rho_\mu}[(Q^\mu(s, \mu_\theta(s)) - Q_\varphi(s, \mu_\theta(s)))^2]
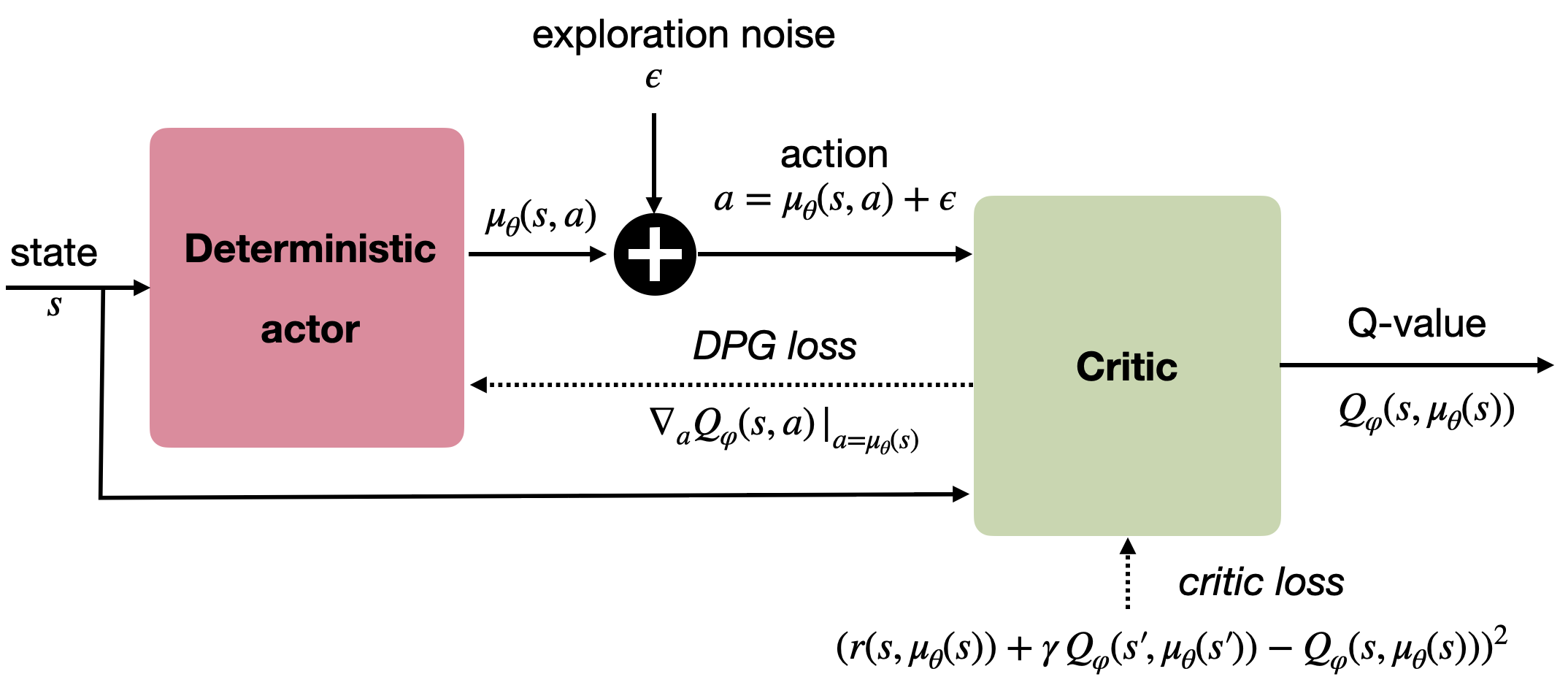
Figure 14.2 outlines the actor-critic architecture of the DPG (deterministic policy gradient) method, to compare with the actor-critic architecture of the stochastic policy gradient.
Silver et al. (2014) investigated the performance of DPG using linear function approximators and showed that it compared positively to stochastic algorithms in high-dimensional or continuous action spaces. However, non-linear function approximators such as deep NN would not work yet.
Deep Deterministic Policy Gradient (DDPG)
Lillicrap et al. (2015) extended the DPG approach to work with non-linear function approximators. In fact, they combined ideas from DQN and DPG to create a very successful algorithm able to solve continuous problems off-policy, the deep deterministic policy gradient (DDPG) algorithm..
The key ideas borrowed from DQN are:
- Using an experience replay memory to store past transitions and learn off-policy.
- Using target networks to stabilize learning.
They modified the update frequency of the target networks originally used in DQN. In DQN, the target networks are updated with the parameters of the trained networks every couple of thousands of steps. The target networks therefore change a lot between two updates, but not very often. Lillicrap et al. (2015) found that it is actually better to make the target networks slowly track the trained networks, by updating their parameters after each update of the trained network using a sliding average for both the actor and the critic:
\theta' = \tau \, \theta + (1-\tau) \, \theta'
with \tau <<1. Using this update rule, the target networks are always “late” with respect to the trained networks, providing more stability to the learning of Q-values.
The key idea borrowed from DPG is the policy gradient for the actor. The critic is learned using regular Q-learning and target networks:
J(\varphi) = \mathbb{E}_{s \sim \rho_\mu}[(r(s, a, s') + \gamma \, Q_{\varphi'}(s', \mu_{\theta'}(s')) - Q_\varphi(s, a))^2]
One remaining issue is exploration: as the policy is deterministic, it can very quickly produce always the same actions, missing perhaps more rewarding options. Some environments are naturally noisy, enforcing exploration by itself, but this cannot be assumed in the general case. The solution retained in DDPG is an additive noise added to the deterministic action to explore the environment:
a_t = \mu_\theta(s_t) + \xi
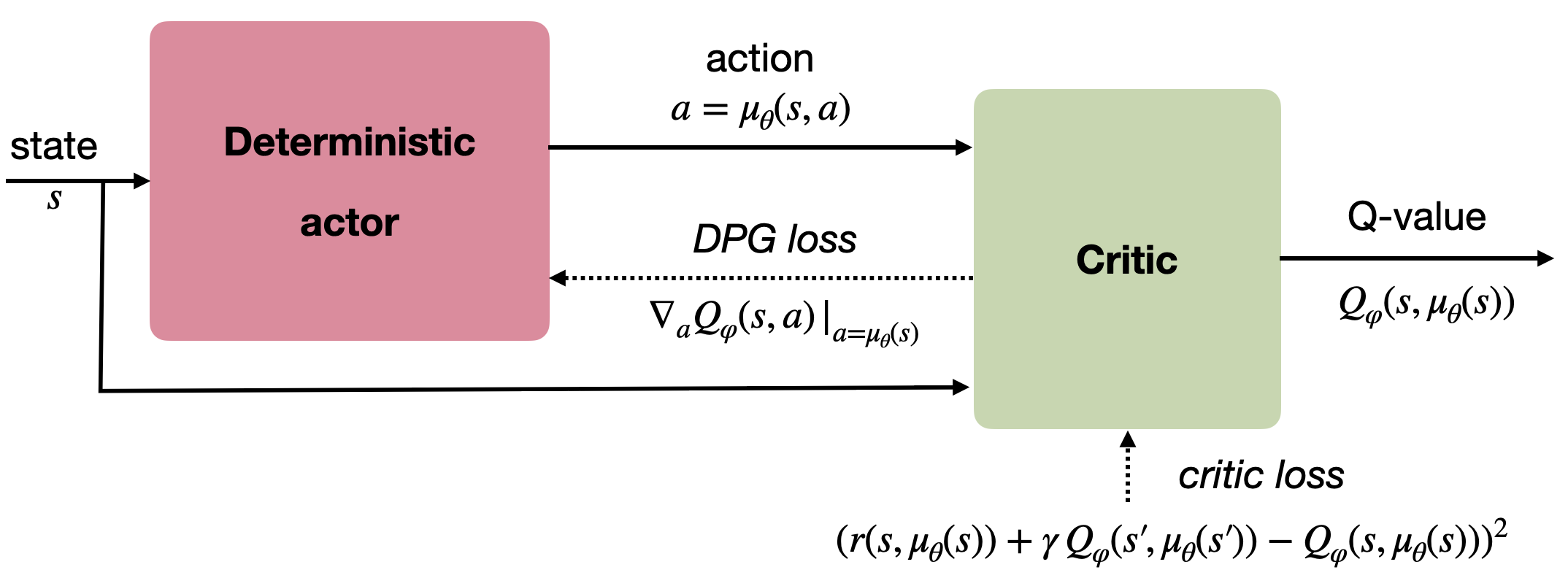
This additive noise could be anything, but the most practical choice is to use an Ornstein-Uhlenbeck process (Uhlenbeck and Ornstein, 1930) to generate temporally correlated noise with zero mean. Ornstein-Uhlenbeck processes are used in physics to model the velocity of Brownian particles with friction. It updates a variable x_t using a stochastic differential equation (SDE):
dx_t = \theta (\mu - x_t) dt + \sigma dW_t \qquad \text{with} \qquad dW_t = \mathcal{N}(0, dt)
\mu is the mean of the process (usually 0), \theta is the friction (how fast it varies with noise) and \sigma controls the amount of noise. Figure 14.3 shows three independent runs of a Ornstein-Uhlenbeck process: successive values of the variable x_t vary randomly but coherently over time.
The architecture of the DDPG algorithm is depicted on Figure 14.4.
The pseudo-algorithm is as follows:
The question that arises is how to obtain the gradient of the Q-value w.r.t the action \nabla_a Q_\varphi(s, a), when the critic only outputs the Q-value Q_\varphi(s, a). Fortunately, deep neural networks are simulated using automatic differentiation libraries such as tensorflow or pytorch, which can automatically output this gradient.
Note that the DDPG algorithm is off-policy: the samples used to train the actor come from the replay buffer, i.e. were generated by an older version of the target policy. DDPG does not rely on importance sampling: as the policy is deterministic (we maximize \mathbb{E}_{s}[Q(s, \mu_\theta(s))]), there is no need to balance the probabilities of the behavior and target policies (with stochastic policies, one should maximize \mathbb{E}_{s}[\sum_{a\in\mathcal{A}} \pi(s, a) Q(s, a)]). In other words, the importance sampling weight can safely be set to 1 for deterministic policies.
DDPG has rapidly become the state-of-the-art model-free method for continuous action spaces (although now PPO is preferred). It is able to learn efficent policies on most contiuous problems, either pixel-based or using individual state variables. In the original DDPG paper, they showed that batch normalization (Ioffe and Szegedy, 2015) is crucial in stabilizing the training of deep networks on such problems. Its main limitation is its high sample complexity. Distributed versions of DDPG have been proposed to speed up learning, similarly to the parallel actor learners of A3C (Barth-Maron et al., 2018; Lötzsch et al., 2017; Popov et al., 2017).
- http://pemami4911.github.io/blog/2016/08/21/ddpg-rl.html for additional explanations and step-by-step tensorflow code.
- https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html for contextual explanations.
Application: learning to drive in a day
The startup Wayve made a very exciting demonstration of the utility of DDPG in autonomous driving in 2018: https://wayve.ai/blog/learning-to-drive-in-a-day-with-reinforcement-learning.
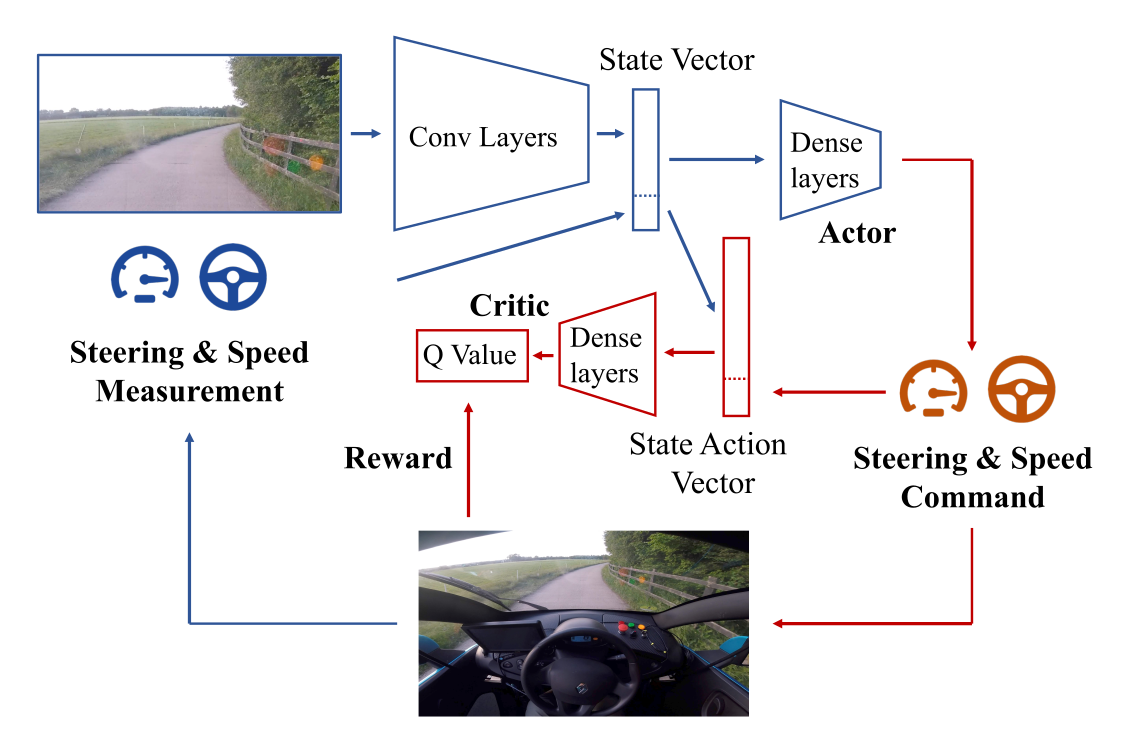
The algorithm is simply DDPG with prioritized experience replay. The actor and critic share the convolutional layers (pretrained in simulation using a variation autoencoder). Training is live in the car, with an on-board NVIDIA Drive PX2 GPU. A simulated environment is first used to find the hyperparameters.
TD3 - Twin Delayed Deep Deterministic policy gradient
Twin critics
As any Q-learning-based method, DDPG overestimates Q-values. The Bellman target t = r + \gamma \, \max_{a'} Q(s', a') uses a maximum over other values, so it is increasingly overestimated during learning. After a while, the overestimated Q-values disrupt training in the actor.
Double Q-learning (see Section Double DQN) solves the problem by using the target network \theta' to estimate Q-values, but the value network \theta to select the greedy action in the next state:
\mathcal{L}(\theta) = \mathbb{E}_\mathcal{D} [(r + \gamma \, Q_{\theta'}(s´, \text{argmax}_{a'} Q_{\theta}(s', a')) - Q_\theta(s, a))^2]
The idea is to use two different independent networks to reduce overestimation. This does not work well with DDPG, as the Bellman target t = r + \gamma \, Q_{\varphi'}(s', \mu_{\theta'}(s')) will use a target actor network that is not very different from the trained deterministic actor, as the greedy action is likely to be the same for both.
To solve this, TD3 (Fujimoto et al., 2018) uses two critics \varphi_1 and \varphi_2 (and target critics): the Q-value used to train the actor will be the lesser of two evils, i.e. the minimum Q-value:
t = r + \gamma \, \min(Q_{\varphi'_1}(s', \mu_{\theta'}(s')), Q_{\varphi'_2}(s', \mu_{\theta'}(s')))
One of the critic will always be less over-estimating than the other. Better than nothing… Using twin critics is called clipped double learning.
Both critics learn in parallel using the same target:
\mathcal{L}(\varphi_1) = \mathbb{E}[(t - Q_{\varphi_1}(s, a))^2] \qquad ; \qquad \mathcal{L}(\varphi_2) = \mathbb{E}[ (t - Q_{\varphi_2}(s, a))^2]
The actor is trained using the first critic only:
\nabla_\theta \mathcal{J}(\theta) = \mathbb{E}[ \nabla_\theta \mu_\theta(s) \times \nabla_a Q_{\varphi_1}(s, a) |_{a = \mu_\theta(s)} ]
Delayed actor updates
Another issue with actor-critic architecture in general is that the critic is always biased during training, what can impact the actor and ultimately collapse the policy:
\nabla_\theta \mathcal{J}(\theta) = \mathbb{E}[ \nabla_\theta \mu_\theta(s) \times \nabla_a Q_{\varphi_1}(s, a) |_{a = \mu_\theta(s)} ]
Q_{\varphi_1}(s, a) \approx Q^{\mu_\theta}(s, a)
The critic should learn much faster than the actor in order to provide unbiased gradients.

Increasing the learning rate in the critic creates instability, reducing the learning rate in the actor slows down learning. The solution proposed by TD3 is to delay the update of the actor, i.e. update it only every d minibatches:
This leaves enough time to the critics to improve their prediction and provides less biased gradients to the actor.
Noisy Bellman targets
A last problem with deterministic policies is that they tend to always select the same actions \mu_\theta(s) (overfitting). For exploration, some additive noise is added to the selected action:
a = \mu_\theta(s) + \xi
But this is not true for the Bellman targets, which use the deterministic action:
t = r + \gamma \, Q_{\varphi}(s', \mu_{\theta}(s'))
TD3 proposes to also use additive noise in the Bellman targets:
t = r + \gamma \, Q_{\varphi}(s', \mu_{\theta}(s') + \xi)
If the additive noise is zero on average, the Bellman targets will be correct on average (unbiased) but will prevent overfitting of particular actions. The additive noise does not have to be an Ornstein-Uhlenbeck stochastic process, but could simply be a random variable:
\xi \sim \mathcal{N}(0, 1)
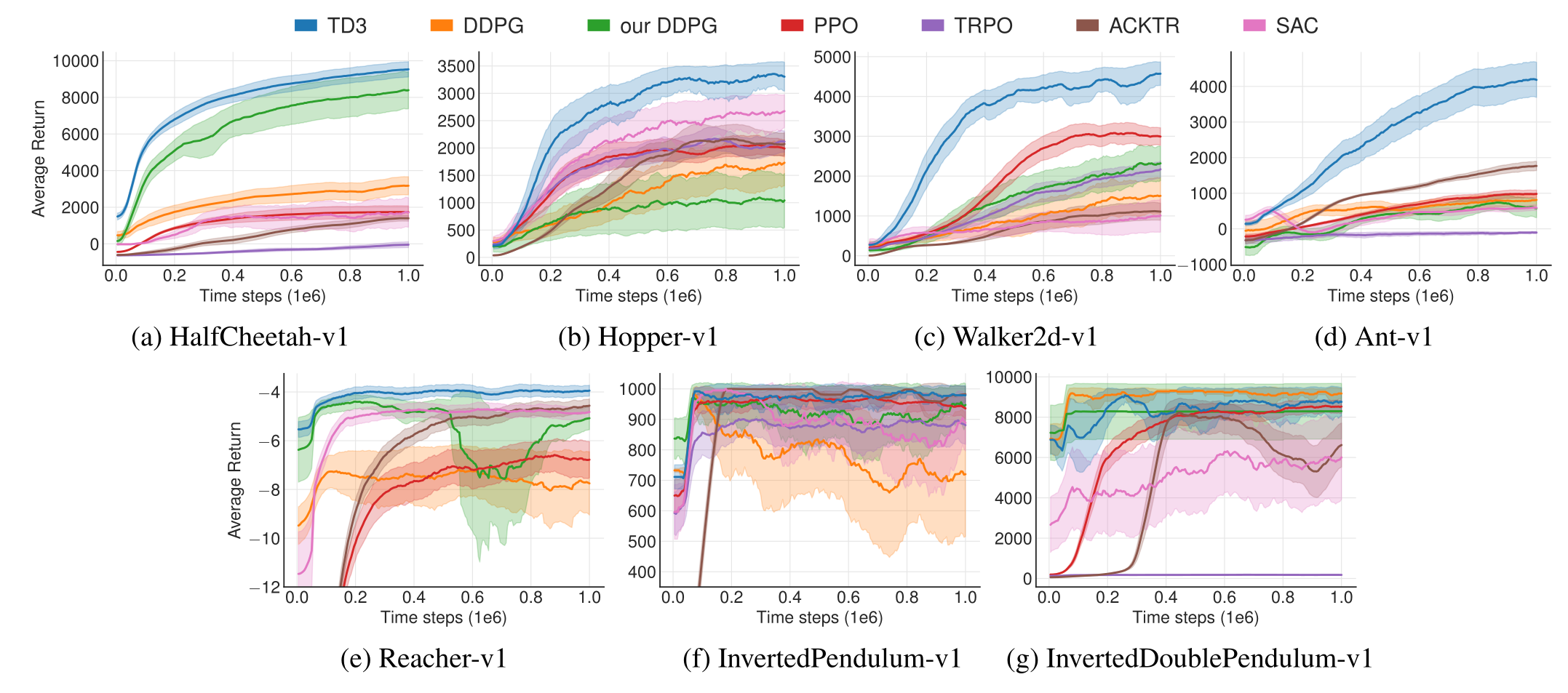
TD3 outperformed DDPG (but also PPO and SAC) on continuous control tasks.
D4PG: Distributed Distributional DDPG
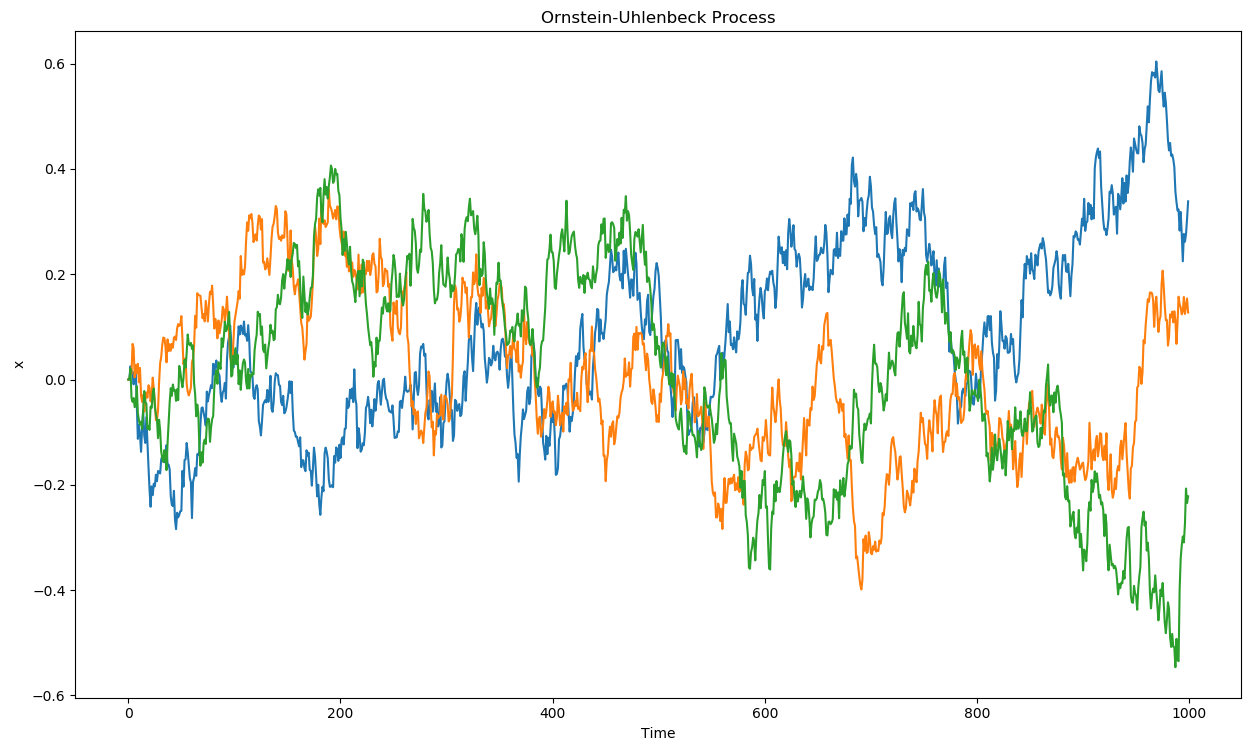
D4PG (Distributed Distributional DDPG; Barth-Maron et al. (2018)) combined several recent improvements:
Deterministic policy gradient as in DDPG: \nabla_\theta \mathcal{J}(\theta) = \mathbb{E}_{s \sim \rho_b}[\nabla_\theta \mu_\theta(s) \times \nabla_a \mathbb{E} [\mathcal{Z}_\varphi(s, a)] |_{a = \mu_\theta(s)}]
Distributional critic: The critic does not predict single Q-values Q_\varphi(s, a), but the distribution of returns \mathcal{Z}_\varphi(s, a) (as in Categorical DQN): \mathcal{L}(\varphi) = \mathbb{E}_{s \in \rho_b} [ \text{KL}(\mathcal{T} \, \mathcal{Z}_\varphi(s, a) || \mathcal{Z}_\varphi(s, a))]
n-step returns (as in A3C): \mathcal{T} \, \mathcal{Z}_\varphi(s_t, a_t)= \sum_{k=0}^{n-1} \gamma^{k} \, r_{t+k+1} + \gamma^n \, \mathcal{Z}_\varphi(s_{t+n}, \mu_\theta(s_{t+n}))
Distributed workers: D4PG uses K=32 or 64 copies of the actor to fill the ERM in parallel.
Prioritized Experience Replay (PER): P(k) = \frac{(|\delta_k| + \epsilon)^\alpha}{\sum_k (|\delta_k| + \epsilon)^\alpha}