
4. Linear classification¶
Slides: pdf
4.1. Hard linear classification¶
The training data \(\mathcal{D}\) is composed of \(N\) examples \((\mathbf{x}_i, t_i)_{i=1..N}\) , with a d-dimensional input vector \(\mathbf{x}_i \in \Re^d\) and a binary output \(t_i \in \{-1, +1\}\). The data points where \(t = + 1\) are called the positive class, the other the negative class.
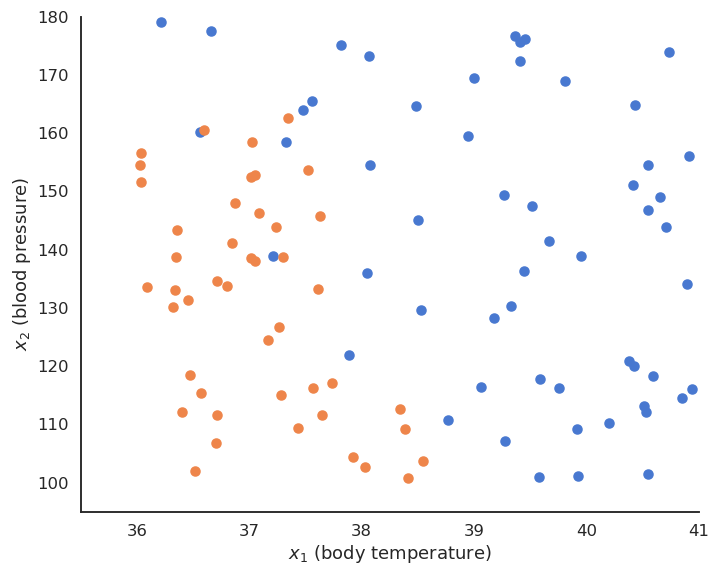
Fig. 4.1 Binary linear classification of 2D data.¶
For example, the inputs \(\mathbf{x}_i\) can be images (one dimension per pixel) and the positive class corresponds to cats (\(t_i = +1\)), the negative class to dogs (\(t_i = -1\)).

Fig. 4.2 Binary linear classification of cats vs. dogs images. Source: http://adilmoujahid.com/posts/2016/06/introduction-deep-learning-python-caffe¶
We want to find the hyperplane \((\mathbf{w}, b)\) of \(\Re^d\) that correctly separates the two classes.
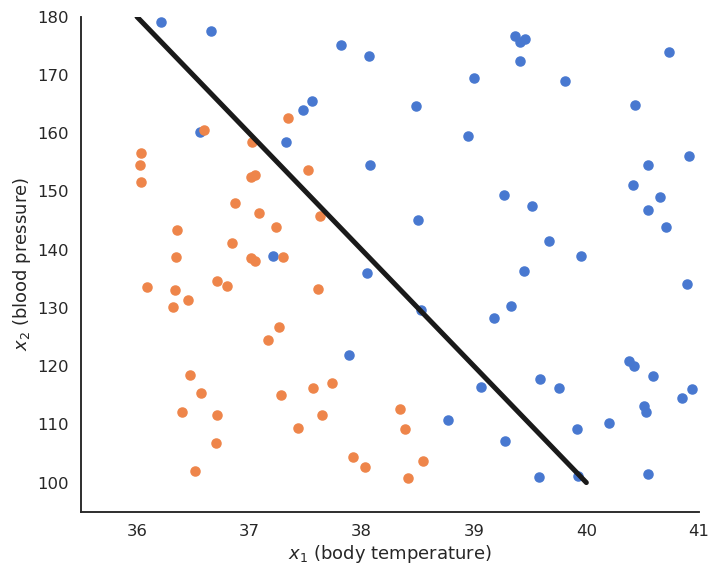
Fig. 4.3 The hyperplane separates the input space into two regions.¶
For a point \(\mathbf{x} \in \mathcal{D}\), \(\langle \mathbf{w} \cdot \mathbf{x} \rangle +b\) is the projection of \(\mathbf{x}\) onto the hyperplane \((\mathbf{w}, b)\).
If \(\langle \mathbf{w} \cdot \mathbf{x} \rangle +b > 0\), the point is above the hyperplane.
If \(\langle \mathbf{w} \cdot \mathbf{x} \rangle +b < 0\), the point is below the hyperplane.
If \(\langle \mathbf{w} \cdot \mathbf{x} \rangle +b = 0\), the point is on the hyperplane.

Fig. 4.4 Projection on an hyperplane.¶
By looking at the sign of \(\langle \mathbf{w} \cdot \mathbf{x} \rangle +b\), we can predict the class.
Binary linear classification can therefore be made by a single artificial neuron using the sign transfer function.
\(\mathbf{w}\) is the weight vector and \(b\) is the bias.
Linear classification is the process of finding an hyperplane \((\mathbf{w}, b)\) that correctly separates the two classes. If such an hyperplane can be found, the training set is said linearly separable. Otherwise, the problem is non-linearly separable and other methods have to be applied (MLP, SVM…).

Fig. 4.5 Linearly and non-linearly spearable datasets.¶
4.1.1. Perceptron algorithm¶
The Perceptron algorithm tries to find the weights and biases minimizing the mean square error (mse) or quadratic loss:
When the prediction \(y_i\) is the same as the data \(t_i\) for all examples in the training set (perfect classification), the mse is minimal and equal to 0. We can apply gradient descent to find this minimum.
Let’s search for the partial derivative of the quadratic error function with respect to the weight vector:
Everything is similar to linear regression until we get:
In order to continue with the chain rule, we would need to differentiate \(\text{sign}(x)\).
But the sign function is not differentiable… We will simply pretend that the sign() function is linear, with a derivative of 1:
The update rule for the weight vector \(\mathbf{w}\) and the bias \(b\) is therefore the same as in linear regression:
By applying gradient descent on the quadratic error function, one obtains the following algorithm:
Batch perceptron
for \(M\) epochs:
\(\mathbf{dw} = 0 \qquad db = 0\)
for each sample \((\mathbf{x}_i, t_i)\):
\(y_i = \text{sign}( \langle \mathbf{w} \cdot \mathbf{x}_i \rangle + b)\)
\(\mathbf{dw} = \mathbf{dw} + (t_i - y_i) \, \mathbf{x}_i\)
\(db = db + (t_i - y_i)\)
\(\Delta \mathbf{w} = \eta \, \frac{1}{N} \, \mathbf{dw}\)
\(\Delta b = \eta \, \frac{1}{N} \, db\)
This is called the batch version of the Perceptron algorithm. If the data is linearly separable and \(\eta\) is well chosen, it converges to the minimum of the mean square error.
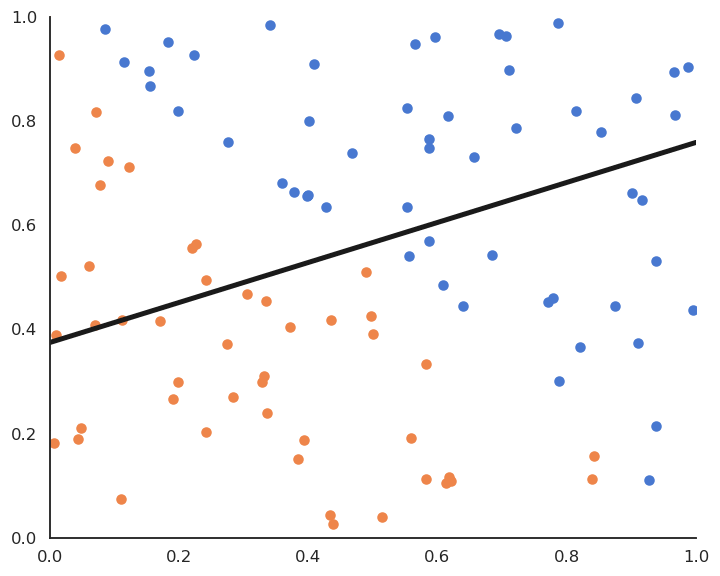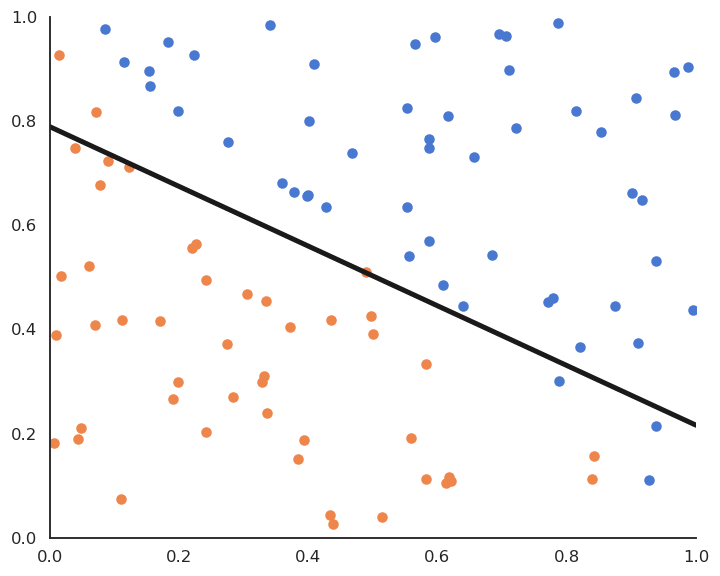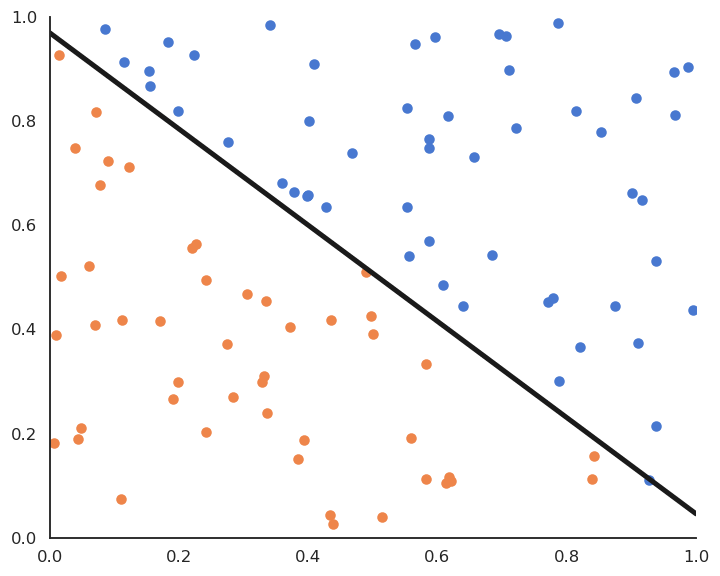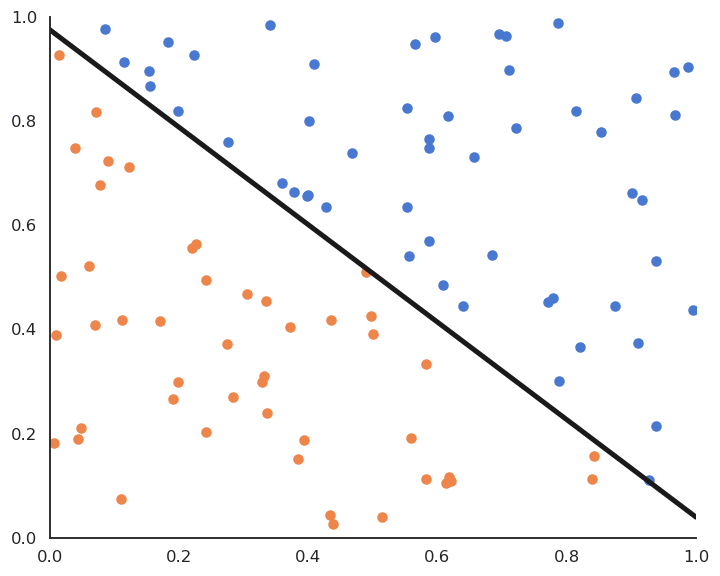
Fig. 4.6 Batch perceptron algorithm.¶
The Perceptron algorithm was invented by the psychologist Frank Rosenblatt in 1958. It was the first algorithmic neural network able to learn linear classification.
Online perceptron algorithm
for \(M\) epochs:
for each sample \((\mathbf{x}_i, t_i)\):
\(y_i = \text{sign}( \langle \mathbf{w} \cdot \mathbf{x}_i \rangle + b)\)
\(\Delta \mathbf{w} = \eta \, (t_i - y_i) \, \mathbf{x}_i\)
\(\Delta b = \eta \, (t_i - y_i)\)
This algorithm iterates over all examples of the training set and applies the delta learning rule to each of them immediately, not at the end on the whole training set. One could check whether there are still classification errors on the training set at the end of each epoch and stop the algorithm. The delta learning rule depends as always on the learning rate \(\eta\), the error made by the prediction (\(t_i - y_i\)) and the input \(\mathbf{x}_i\).
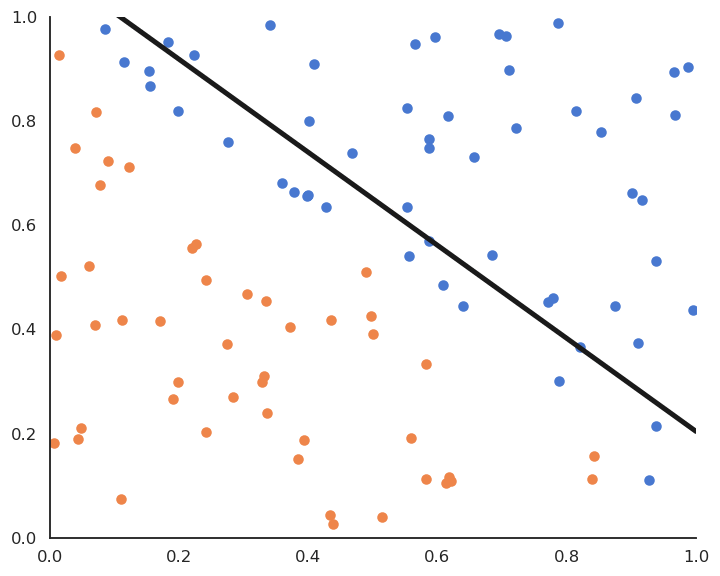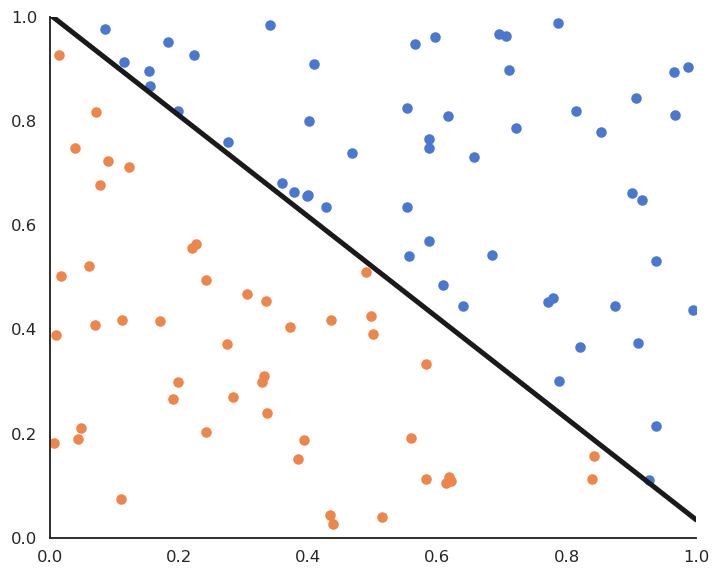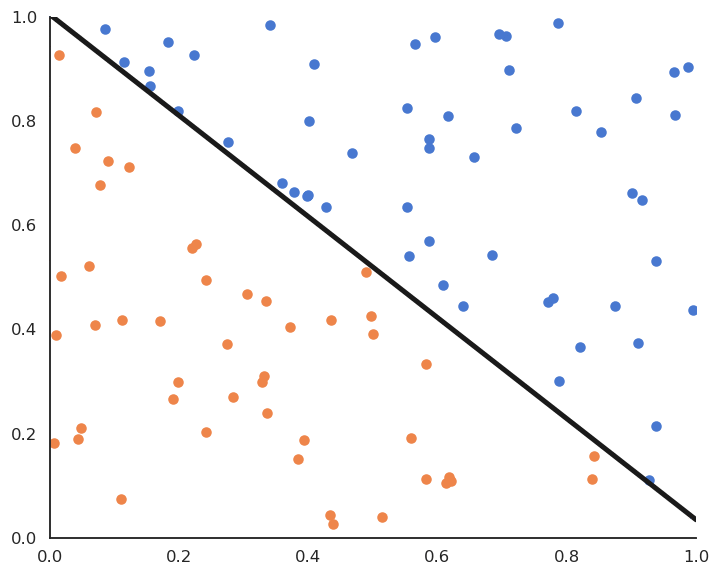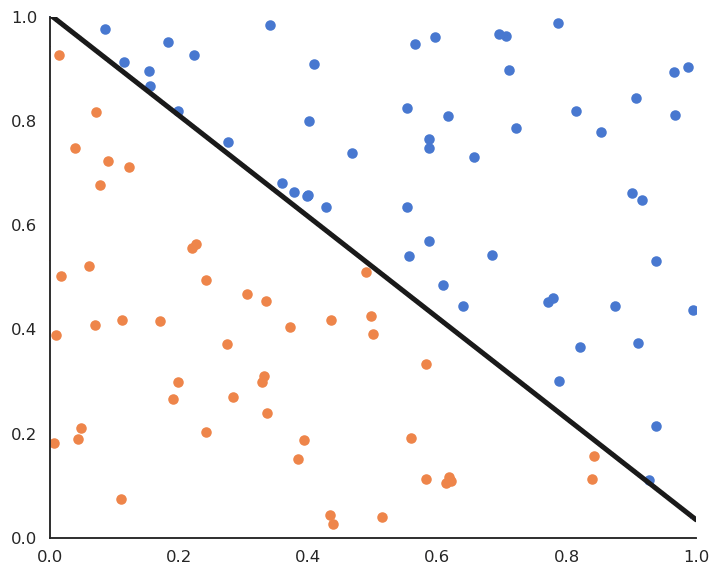
Fig. 4.7 Online perceptron algorithm.¶
4.1.2. Stochastic Gradient descent¶
The mean square error is defined as the expectation over the data:
Batch learning uses the whole training set as samples to estimate the mse:
Online learning uses a single sample to estimate the mse:
Batch learning has less bias (central limit theorem) and is less sensible to noise in the data, but is very slow. Online learning converges faster, but can be instable and overfits (high variance).
In practice, we use a trade-off between batch and online learning called Stochastic Gradient Descent (SGD) or Minibatch Gradient Descent.
The training set is randomly split at each epoch into small chunks of data (a minibatch, usually 32 or 64 examples) and the batch learning rule is applied on each chunk.
If the batch size is well chosen, SGD is as stable as batch learning and as fast as online learning. The minibatches are randomly selected at each epoch (i.i.d).
Note
Online learning is a stochastic gradient descent with a batch size of 1.
4.2. Maximum Likelihood Estimation¶
Let’s consider \(N\) samples \(\{x_i\}_{i=1}^N\) independently taken from a normal distribution \(X\). The probability density function (pdf) of a normal distribution is:
where \(\mu\) is the mean of the distribution and \(\sigma\) its standard deviation.
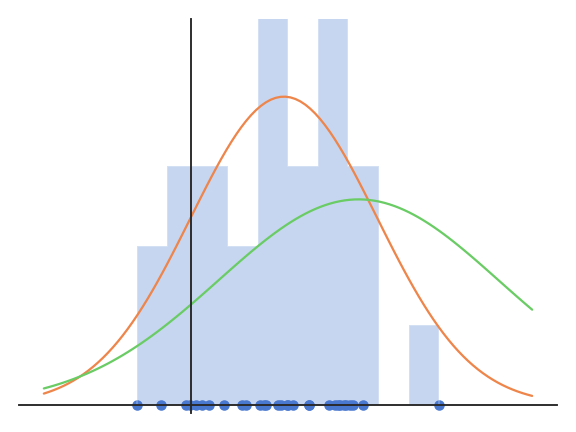
Fig. 4.8 Normal distributions with different parameters \(\mu\) and \(\sigma\) explain the data with different likelihoods.¶
The problem is to find the values of \(\mu\) and \(\sigma\) which explain best the observations \(\{x_i\}_{i=1}^N\).
The idea of MLE is to maximize the joint density function for all observations. This function is expressed by the likelihood function:
When the pdf takes high values for all samples, it is quite likely that the samples come from this particular distribution. The likelihood function reflects the probability that the parameters \(\mu\) and \(\sigma\) explain the observations \(\{x_i\}_{i=1}^N\).
We therefore search for the values \(\mu\) and \(\sigma\) which maximize the likelihood function.
For the normal distribution, the likelihood function is:
To find the maximum of \(L(\mu, \sigma)\), we need to search where the gradient is equal to zero:
The likelihood function is complex to differentiate, so we consider its logarithm \(l(\mu, \sigma) = \log(L(\mu, \sigma))\) which has a maximum for the same value of \((\mu, \sigma)\) as the log function is monotonic.
\(l(\mu, \sigma)\) is called the log-likelihood function. The maximum of the log-likelihood function respects:
We obtain:
Unsurprisingly, the mean and variance of the normal distribution which best explains the data are the mean and variance of the data…
The same principle can be applied to estimate the parameters of any distribution: normal, exponential, Bernouilli, Poisson, etc… When a machine learning method has an probabilistic interpretation (i.e. it outputs probabilities), MLE can be used to find its parameters. One can use global optimization like here, or gradient descent to estimate the parameters iteratively.
4.3. Soft linear classification : Logistic regression¶
In logistic regression, we want to perform a regression, but where the targets \(t_i\) are bounded betwen 0 and 1. We can use a logistic function instead of a linear function in order to transform the net activation into an output:
Logistic regression can be used in binary classification if we consider \(y = \sigma(w \, x + b )\) as the probability that the example belongs to the positive class (\(t=1\)).
The output \(t\) therefore comes from a Bernouilli distribution \(\mathcal{B}\) of parameter \(p = y = f_{w, b}(x)\). The probability density function (pdf) is:
If we consider our training samples \((x_i, t_i)\) as independently taken from this distribution, our task is to find the parameterized distribution that best explains the data, which means to find the parameters \(w\) and \(b\) maximizing the likelihood that the samples \(t\) come from a Bernouilli distribution when \(x\), \(w\) and \(b\) are given. We only need to apply Maximum Likelihood Estimation (MLE) on this Bernouilli distribution!
The likelihood function for logistic regression is :
The likelihood function is quite hard to differentiate, so we take the log-likelihood function:
or even better: the negative log-likelihood which will be minimized using gradient descent:
We then search for the minimum of the negative log-likelihood function by computing its gradient (here for a single sample):
We obtain the same gradient as the linear perceptron, but with a non-linear output function! Logistic regression is therefore a regression method used for classification. It uses a non-linear transfer function \(\sigma(x)=\frac{1}{1+\exp(-x)}\) applied on the net activation:
The continuous output \(y\) is interpreted as the probability of belonging to the positive class.
We minimize the negative log-likelihood loss function:
Gradient descent leads to the delta learning rule, using the class as a target and the probability as a prediction:
Logistic regression
\(\mathbf{w} = 0 \qquad b = 0\)
for \(M\) epochs:
for each sample \((\mathbf{x}_i, t_i)\):
\(y_i = \sigma( \langle \mathbf{w} \cdot \mathbf{x}_i \rangle + b)\)
\(\Delta \mathbf{w} = \eta \, (t_i - y_i) \, \mathbf{x}_i\)
\(\Delta b = \eta \, (t_i - y_i)\)
Logistic regression works just like linear classification, except in the way the prediction is done. To know to which class \(\mathbf{x}_i\) belongs, simply draw a random number between 0 and 1:
if it is smaller than \(y_i\) (probability \(y_i\)), it belongs to the positive class.
if it is bigger than \(y_i\) (probability \(1-y_i\)), it belongs to the negative class.
Alternatively, you can put a hard limit at 0.5:
if \(y_i > 0.5\) then the class is positive.
if \(y_i < 0.5\) then the class is negative.
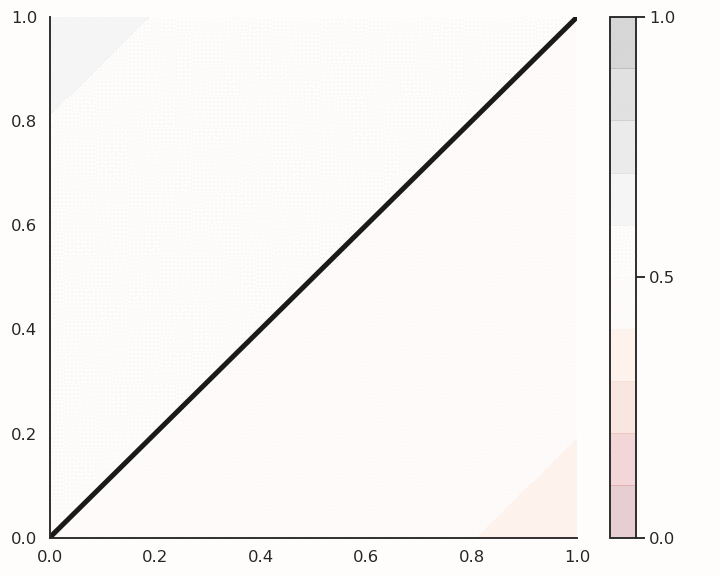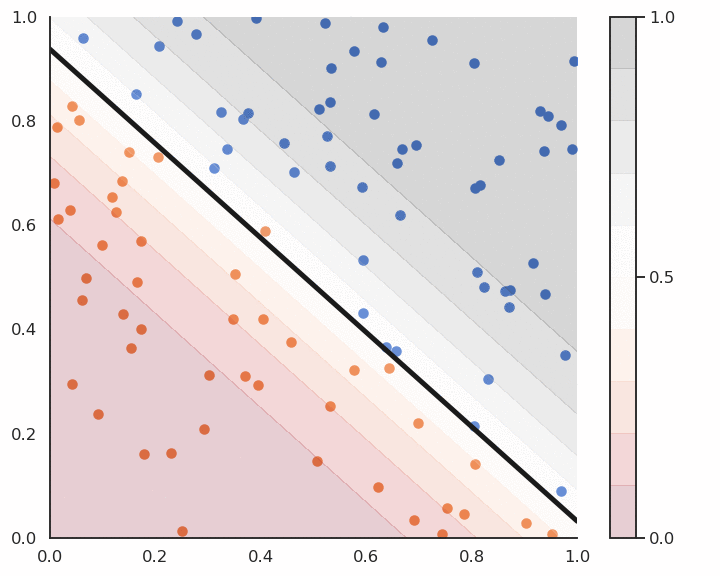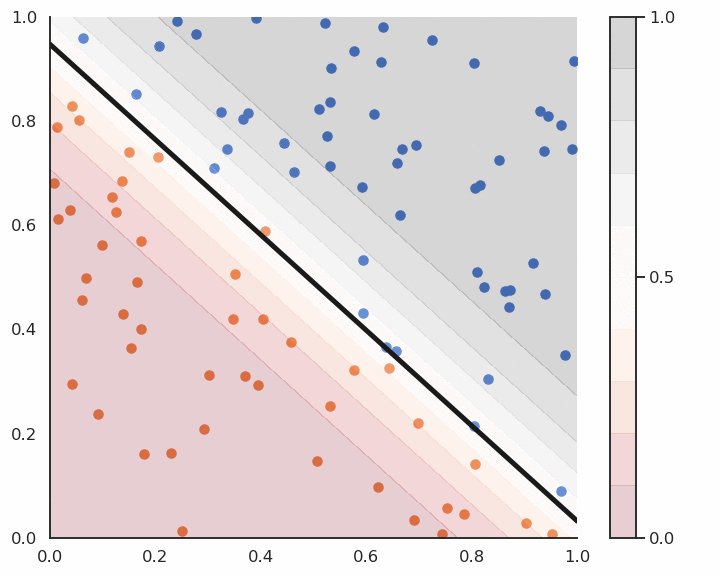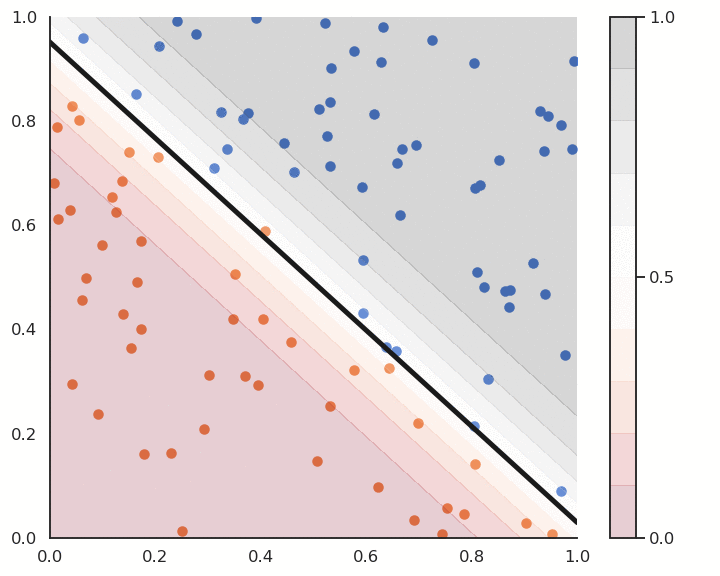
Fig. 4.9 Logistic regression for soft classification. The confidence scores tells how certain the classification is.¶
Logistic regression also provides a confidence score: the closer \(y\) is from 0 or 1, the more confident we can be that the classification is correct. This is particularly important in safety critical applications: if you detect the positive class but with a confidence of 0.51, you should perhaps not trust the prediction. If the confidence score is 0.99, you can probably trust the prediction.