
5.1. Cross-validation and polynomial regression¶
5.1.1. Polynomial regression¶
Polynomial regression consists of fitting some data \((x, y)\) to a \(n\)-order polynomial of the form:
By rewriting the unidimensional input \(x\) into the following vector:
and the weight vector as:
the problem can be reduced to linear regression:
and we can apply the delta learning rule to find \(\mathbf{w}\) and \(b\):
A first method to perform polynomial regression would be to adapt the code you wrote in the last exercise session for linear regression. However, you saw that properly setting the correct learning rate can be quite tricky.
The solution retained for this exercise is to use the built-in functions of Numpy which can already perform polynomial regression in an optimized and proved-sure manner (Note: NumPy does not use gradient descent, but rather directly minimizes the error-function by inversing the Gram matrix).
w = np.polyfit(X, t, deg)
This function takes the inputs \(X\), the desired outputs \(t\) and the desired degree of the polynomial deg, performs the polynomial regression and returns the adequate set of weights (beware: the higher-order coefficient comes first, the bias is last).
Once the weights are obtained, one can use them to predict the value of an example with the function:
y = np.polyval(w, X)
Note: if you prefer to use scikit-learn, check https://scikit-learn.org/stable/auto_examples/linear_model/plot_polynomial_interpolation.html but see https://towardsdatascience.com/polynomial-regression-with-scikit-learn-what-you-should-know-bed9d3296f2 for why it may be a bad idea.
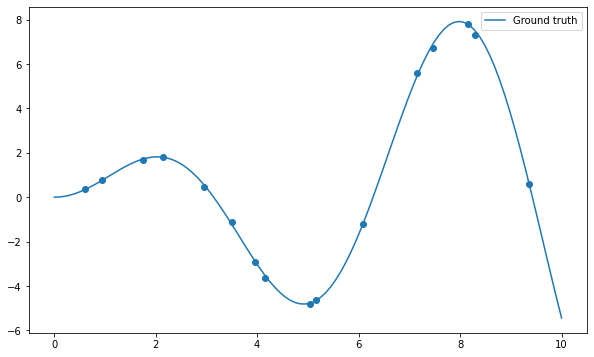
Let’s start by importing the usual stuff and create a dataset of 16 samples generated using the function \(x \, \sin x\) plus some noise:
import numpy as np
import matplotlib.pyplot as plt
# Just to avoid the annoying warnings, please ignore
def warn(*args, **kwargs):
pass
import warnings
warnings.warn = warn
def create_dataset(N, noise):
"Creates a dataset of N points generated from x*sin(x) plus some noise."
x = np.linspace(0, 10, 300)
rng = np.random.default_rng()
rng.shuffle(x)
x = np.sort(x[:N])
t = x * np.sin(x) + noise*rng.uniform(-1.0, 1.0, N)
return x, t
N = 16
X, t = create_dataset(N, noise=0.2)
x = np.linspace(0, 10, 100)
plt.figure(figsize=(10, 6))
plt.plot(x, x*np.sin(x), label="Ground truth")
plt.scatter(X, t)
plt.legend()
plt.show()
Q: Apply the np.polyfit() function on the data and visualize the result for different degrees of the polynomial (from 1 to 20 or even more). What do you observe? Find a polynomial degree which clearly overfits.
Q: Plot the mean square error on the training set for all polynomial regressions from 1 to 20. How does the training error evolve when the degree of the polynomial is increased? What is the risk by taking the hypothesis with the smallest training error?
5.1.2. Simple hold-out cross-validation¶
You will now apply simple hold-out cross-validation to find the optimal degree for the polynomial regression. You will need to separate the data set into a training set \(S_{\text{train}}\) (70% of the data) and a test set \(S_{\text{test}}\) (the remaining 30%).
The data (X, t) could be easily split into two sets of arrays using slices of indices, as the data is already randomized:
N_train = int(0.7*N)
X_train, t_train = X[:N_train], t[:N_train]
X_test, t_test = X[N_train:], t[N_train:]
A much more generic approach is to use the library scikit-learn (https://www.scikit-learn.org), which provides a method able to split any dataset randomly.
You can import the method train_test_split() from its module:
from sklearn.model_selection import train_test_split
The doc of the function is available at: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html.
Q: Use scikit-learn to split the data into the corresponding training and test sets. Train each polynomial from degree 1 to 20 on \(S_{\text{train}}\) and plot the generalization error on \(S_{\text{test}}\). Which degree of the polynomial gives the minimal empirical error? Why? Run the cross-validation split multiple times. Do you always obtain the same optimal degree?
5.1.3. k-fold cross-validation¶
As we only have 16 samples to learn from, it is quite annoying to “lose” 5 of them for the test set. Here we can afford to use k-fold cross-validation, where the cross-validation split is performed \(k\) times:
The dataset is split into \(k\) subsets of equal size (if possible).
Each subset is iteratively used as the test set, while the \(k-1\) other ones are used as a training set.
The final empirical error is the average of the mse on all subsets.
It would be possible to make the splits using indices too, but it is much easier to use scikit-learn once again. You can import the KFold class like this:
from sklearn.model_selection import KFold
k = 4
kf = KFold(n_splits=k, shuffle=True)
n_splits corresponds to \(k\): how many times the dataset is split. We can take \(k=4\) for example (4 subsets of 4 samples).
Q: Check the doc of KFold (https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html). Print the indices of the examples of the training and test sets for each iteration of the algorithm. Change the value of \(k\) to understand how it works.
Q: Apply k-fold cross-validation on the polynomial regression problem. Which polynomial degree is the best? Run the split multiple times: does the best polynomial degree change?
Q: Change \(k\) to \(N\). How stable are the results between two runs?
Q: Regenerate the data with a noise equal to 0.0 and re-run all experiments. What does it change?