
8. Generative adversarial networks¶
Slides: pdf
8.1. Generative adversarial networks¶
8.1.1. Generative models¶
An autoencoder learns to first encode inputs in a latent space and then use a generative model to model the data distribution.
Couldn’t we learn a decoder using random noise as input but still learning the distribution of the data?
After all, this is how random numbers are generated: a uniform distribution of pseudo-random numbers is transformed into samples of another distribution using a mathematical formula.

Fig. 8.1 Random numbers are generated using a standard distribution as source of randomness. Source: https://towardsdatascience.com/understanding-generative-adversarial-networks-gans-cd6e4651a29¶
The problem is how to estimate the discrepancy between the true distribution and the generated distribution when we only have samples. The Maximum Mean Discrepancy (MMD) approach allows to do that, but does not work very well in highly-dimensional spaces.
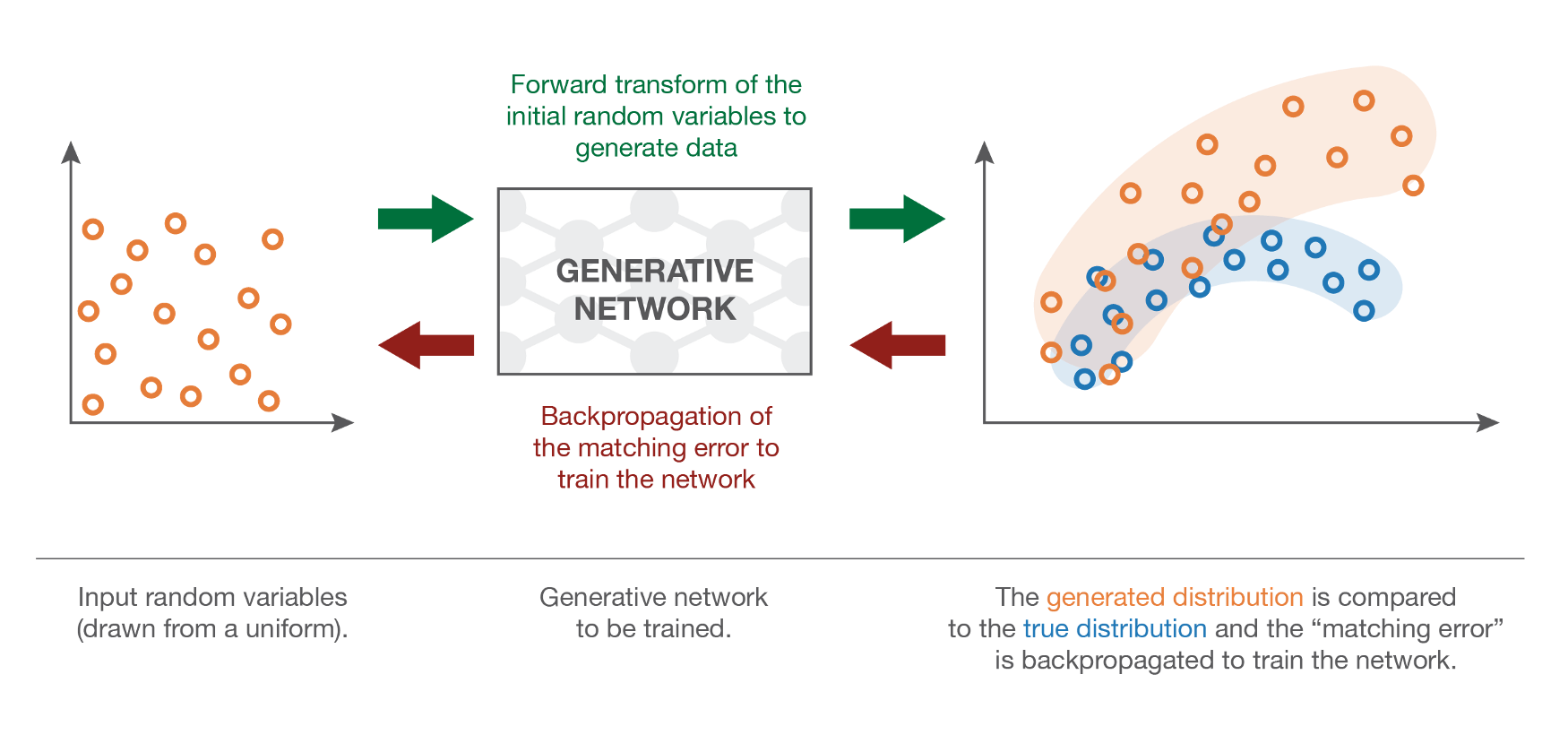
Fig. 8.2 The generative sample should learn to minimize the statistical distance between the true distribution and the parameterized distribution using samples. Source: https://towardsdatascience.com/understanding-generative-adversarial-networks-gans-cd6e4651a29¶
8.1.2. Architecture of a GAN¶
The Generative Adversarial Network (GAN, [Goodfellow et al., 2014]) is a smart way of providing a loss function to the generative model. It is composed of two parts:
The Generator (or decoder) produces an image based on latent variables sampled from some random distribution (e.g. uniform or normal).
The Discriminator has to recognize real images from generated ones.
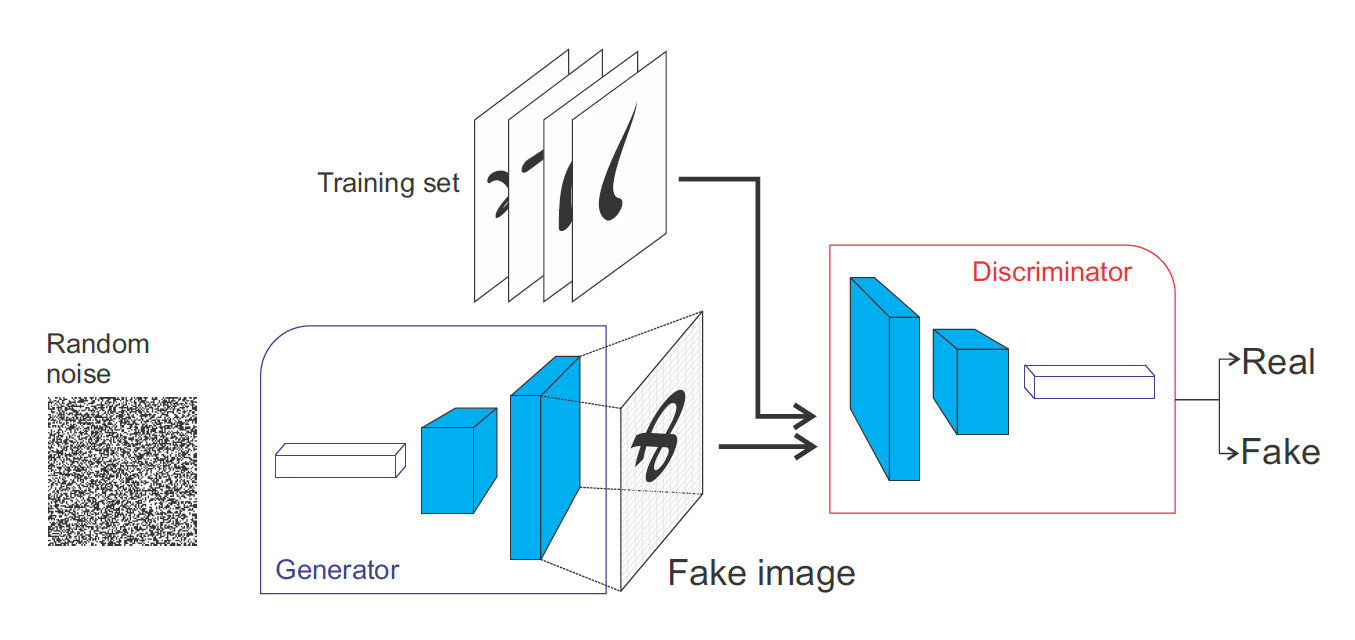
Fig. 8.3 Architecture of a GAN. The generator only sees noisy latent representations and outputs a reconstruction. The discriminator gets alternatively real or generated inputs and predicts whether it is real or fake. Source: https://www.oreilly.com/library/view/java-deep-learning/9781788997454/60579068-af4b-4bbf-83f1-e988fbe3b226.xhtml¶
The generator and the discriminator are in competition with each other. The discriminator uses pure supervised learning: we know if the input is real or generated (binary classification) and train the discriminator accordingly. The generator tries to fool the discriminator, without ever seeing the data!
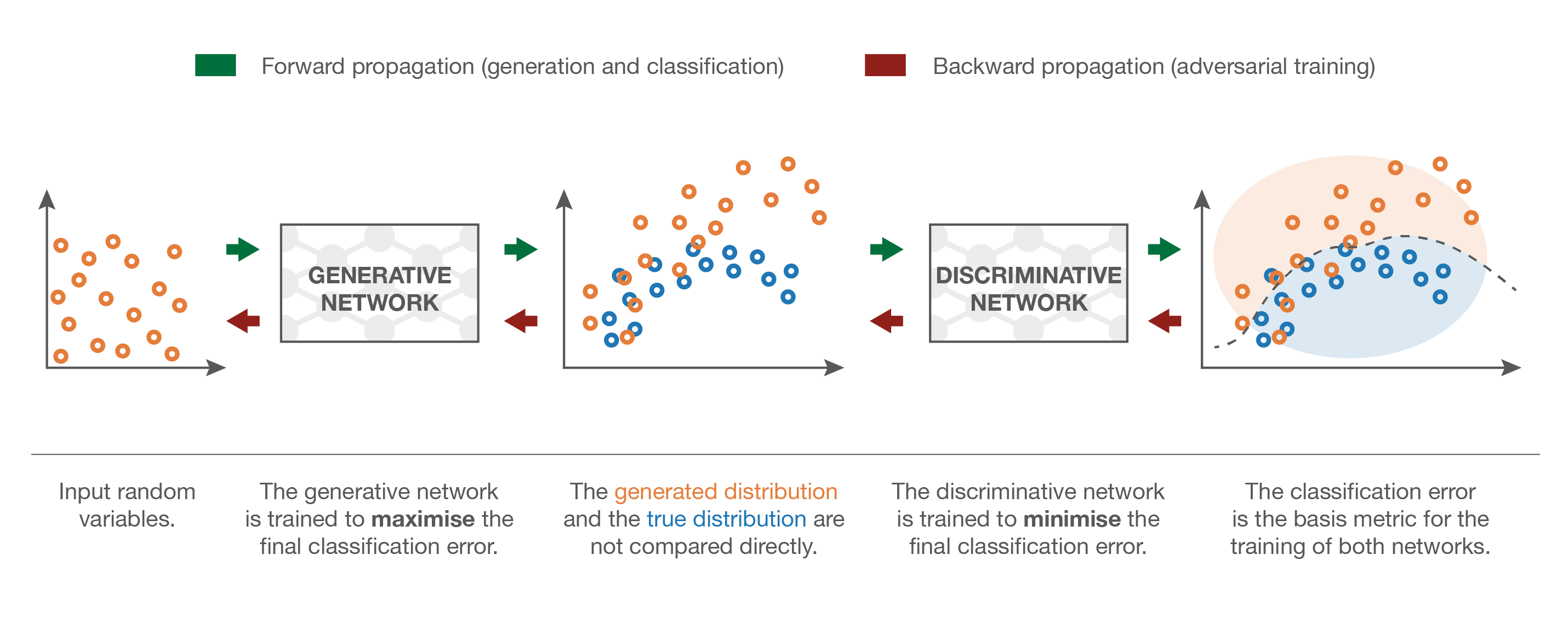
Fig. 8.4 Principle of a GAN. Source: https://towardsdatascience.com/understanding-generative-adversarial-networks-gans-cd6e4651a29¶
8.1.3. GAN loss¶
Let’s define \(x \sim P_\text{data}(x)\) as a real image from the dataset and \(G(z)\) as an image generated by the generator, where \(z \sim P_z(z)\) is a random input. The output of the discriminator is a single sigmoid neuron:
\(D(x) = 1\) for real images.
\(D(G(z)) = 0\) for generated images
The discriminator wants both \(D(x)\) and \(1-D(G(z))\) to be close from 1, so the goal of the discriminator is to minimize the negative log-likelihood (cross-entropy) of classifying correctly the data:
It is similar to logistic regression: \(x\) belongs to the positive class, \(G(z)\) to the negative class.
The goal of the generator is to maximize the negative log-likelihood of the discriminator being correct on the generated images, i.e. fool it:
The generator tries to maximize what the discriminator tries to minimize.
Putting both objectives together, we obtain the following minimax problem:
\(D\) and \(G\) compete on the same objective function: one tries to maximize it, the other to minimize it. Note that the generator \(G\) never sees the data \(x\): all it gets is a backpropagated gradient through the discriminator:
It informs the generator which pixels are the most responsible for an eventual bad decision of the discriminator.
This objective function can be optimized when the generator uses gradient descent and the discriminator gradient ascent: just apply a minus sign on the weight updates!
Both can therefore use the usual backpropagation algorithm to adapt their parameters. The discriminator and the generator should reach a Nash equilibrium: they try to beat each other, but both become better over time.
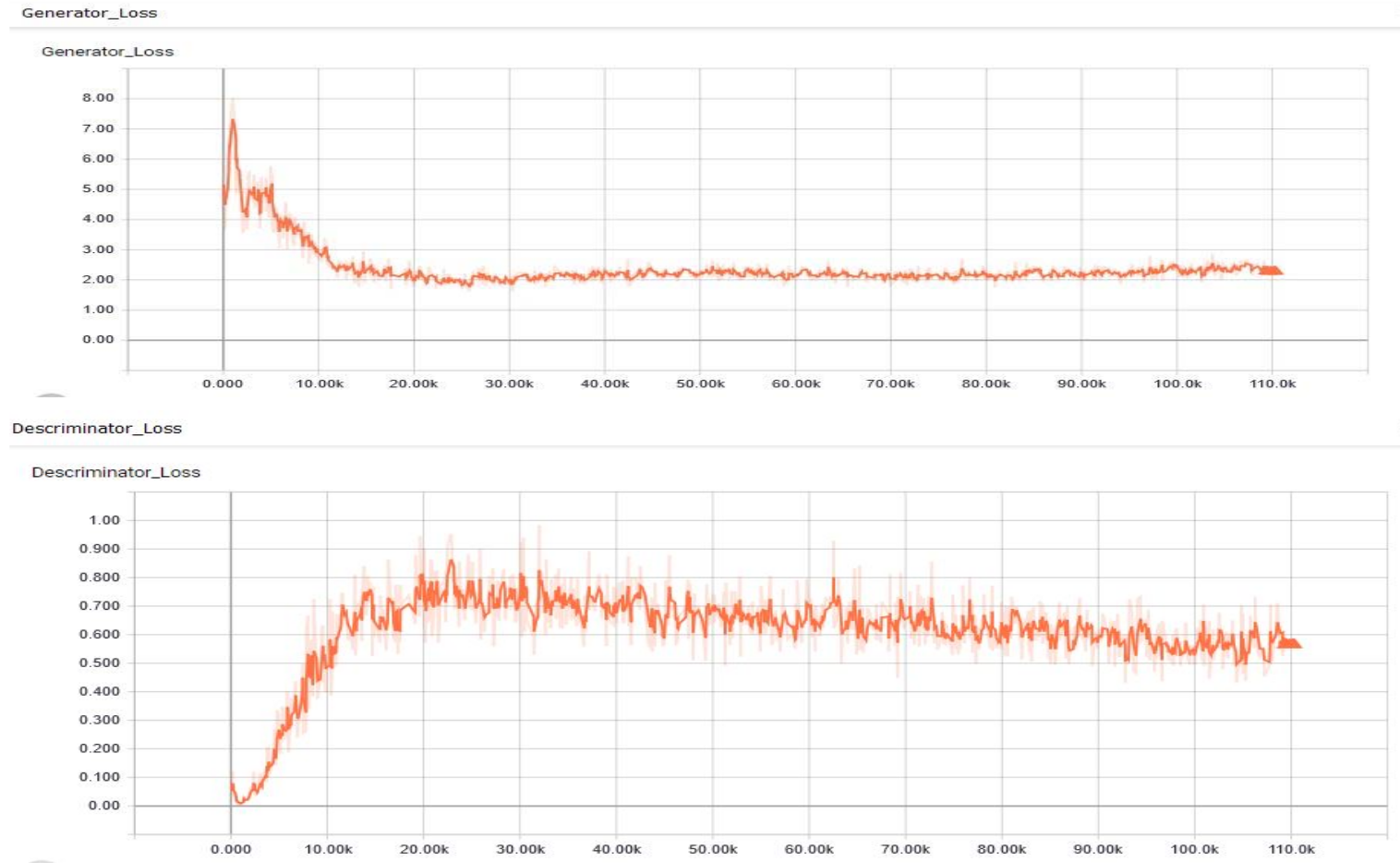
Fig. 8.5 The generator and discriminator loss functions reach an equilibrium, it is quite hard to tell when the network has converged. Source: Research project - Vivek Bakul Maru - TU Chemnitz¶
8.1.4. Variants¶
DCGAN [Radford et al., 2015] is the convolutional version of GAN, using transposed convolutions in the generator and concolutions with stride in the discriminator.
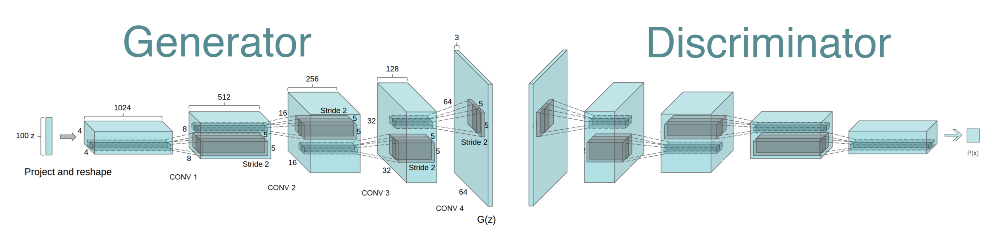
Fig. 8.6 DCGAN [Radford et al., 2015].¶

Fig. 8.7 Results of DCGAN [Radford et al., 2015].¶
GAN are quite sensible to train: the discriminator should not become too good too early, otherwise there is no usable gradient for the generator. In practice, one updates the generator more often than the discriminator. There has been many improvements on GANs to stabilizes training (see [Salimans et al., 2016]):
Wasserstein GAN (relying on the Wasserstein distance instead of the log-likelihood) [Arjovsky et al., 2017].
f-GAN (relying on any f-divergence) [Nowozin et al., 2016].
But the generator often collapses, i.e. outputs non-sense, or always the same image. Hyperparameter tuning is very difficult.
StyleGAN2 from NVIDIA [Karras et al., 2020] is one of the most realistic GAN variant. Check its generated faces at https://thispersondoesnotexist.com/.
8.2. Conditional GANs¶
8.2.1. cGAN¶
The generator can also get additional deterministic information to the latent space, not only the random vector \(z\). One can for example provide the label (class) in the context of supervised learning, allowing to generate many new examples of each class: data augmentation using a conditional GAN [Mirza & Osindero, 2014]. One could also provide the output of a pre-trained CNN (ResNet) to condition on images.
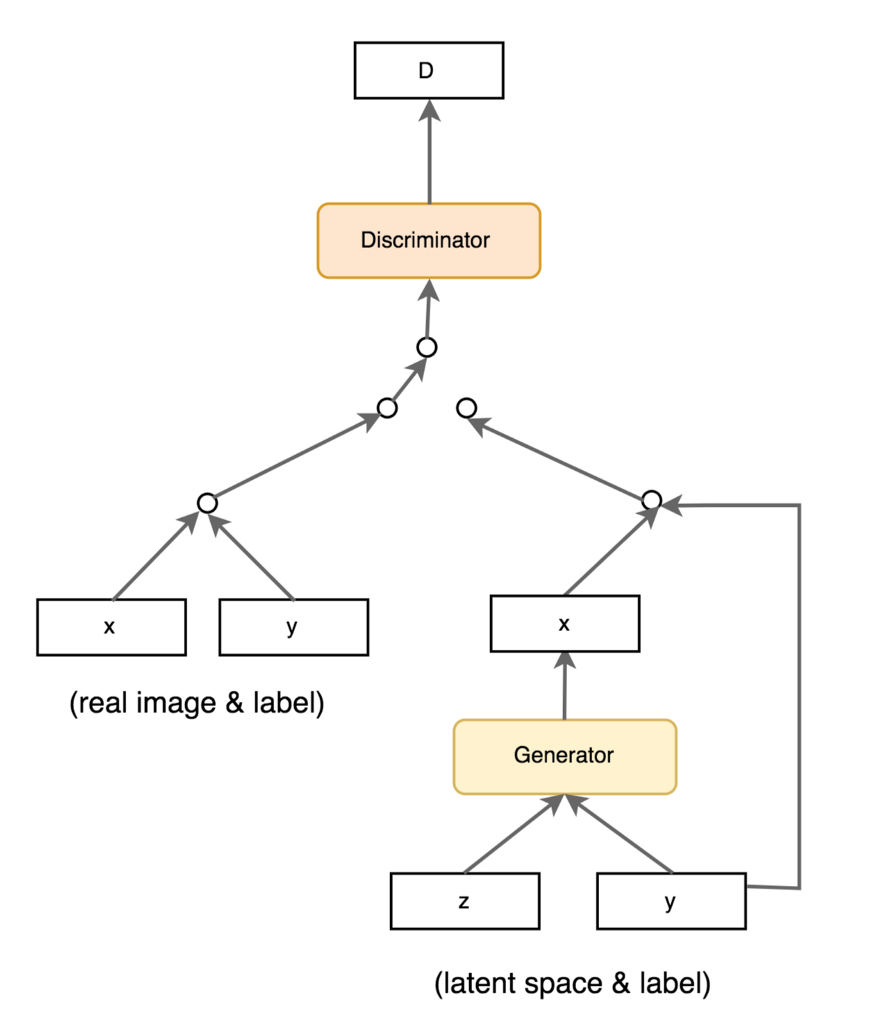
Fig. 8.8 cGAN [Mirza & Osindero, 2014].¶
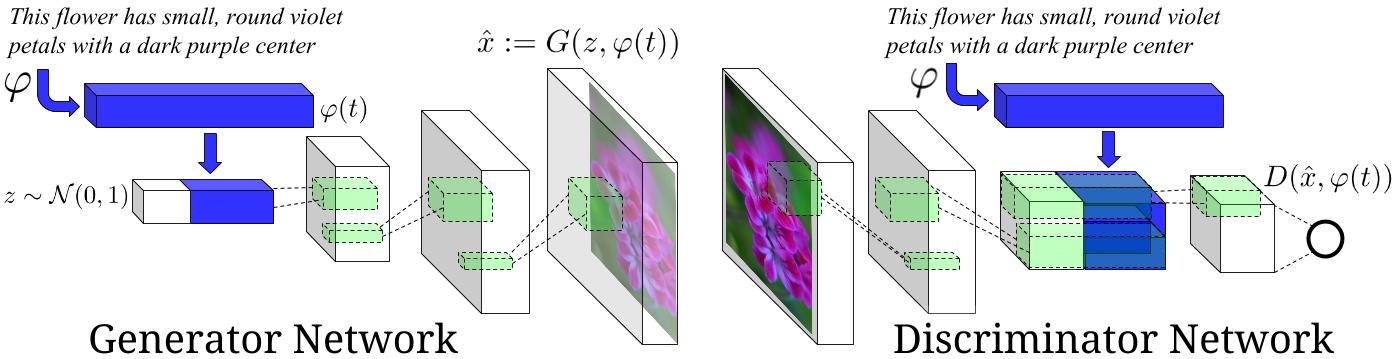
Fig. 8.9 cGAN conditioned on text [Reed et al., 2016].¶

Fig. 8.10 cGAN conditioned on text [Reed et al., 2016].¶
8.2.2. pix2pix¶
cGAN can be extended to have an autoencoder-like architecture, allowing to generate images from images. pix2pix [Isola et al., 2018] is trained on pairs of similar images in different domains. The conversion from one domain to another is easy in one direction, but we want to learn the opposite.
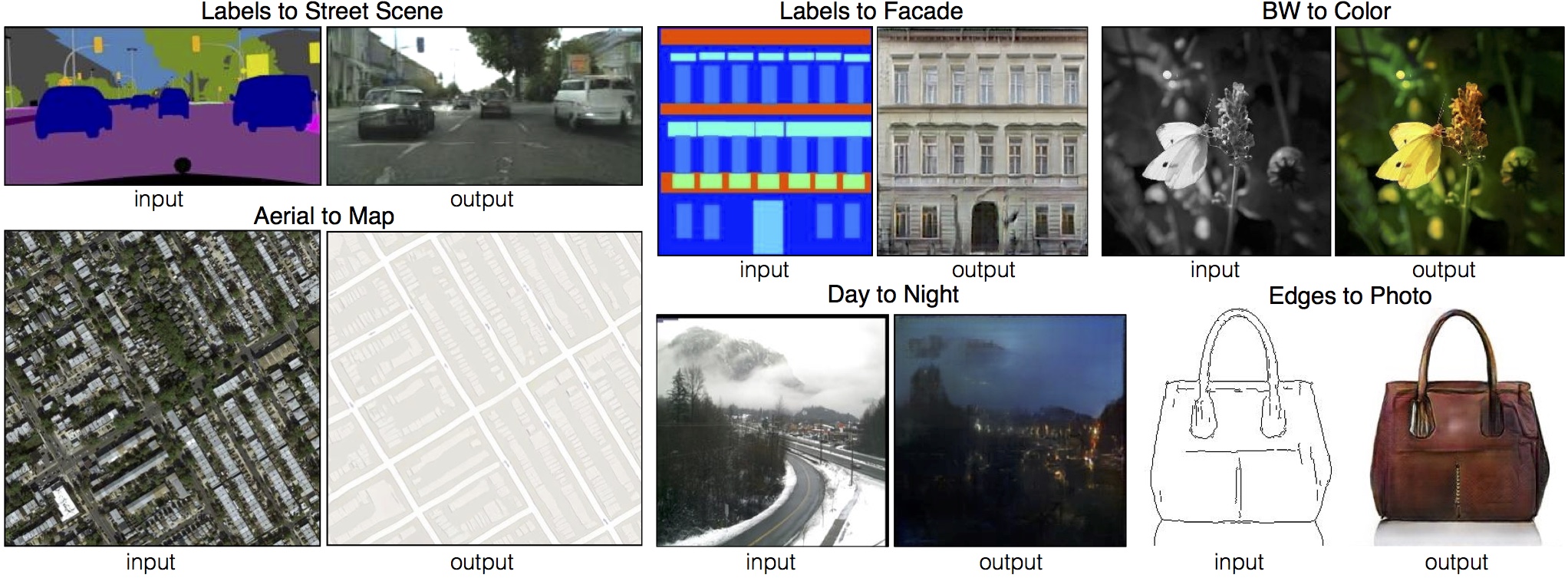
Fig. 8.11 pix2pix [Isola et al., 2018].¶
The goal of the generator is to convert for example a black-and-white image into a colorized one. It is a deep convolutional autoencoder, with convolutions with strides and transposed convolutions (SegNet-like).
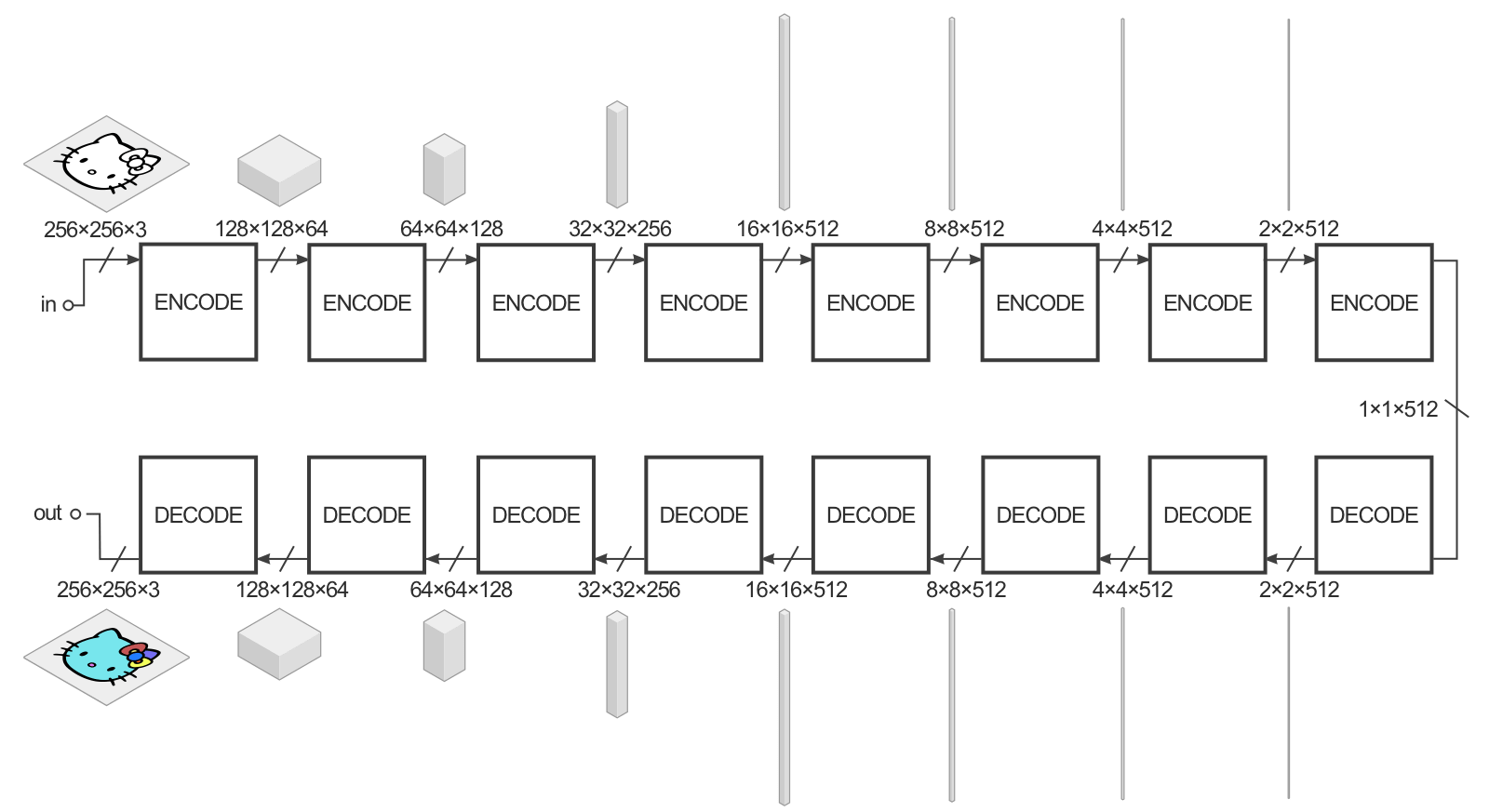
Fig. 8.12 pix2pix generator. Source: https://affinelayer.com/pix2pix/.¶
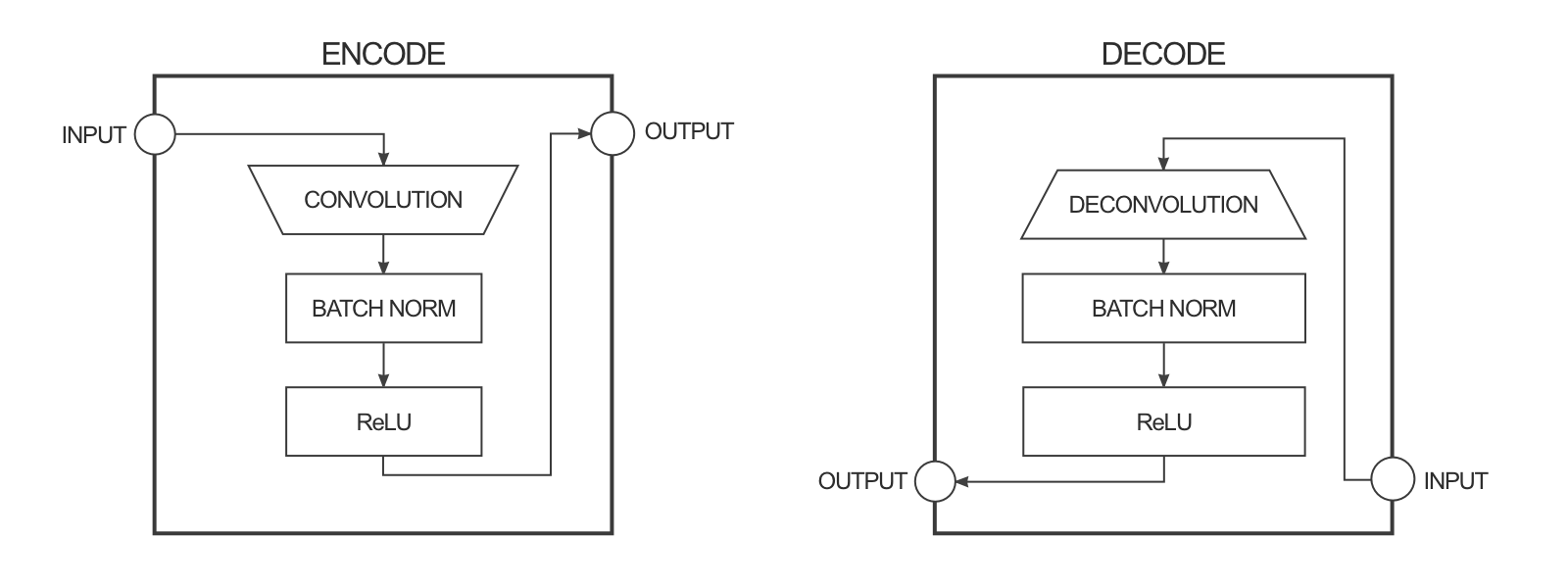
Fig. 8.13 Blocks of the pix2pix generator. Source: https://affinelayer.com/pix2pix/.¶
In practice, it has a U-Net architecture with skip connections to generate fine details.
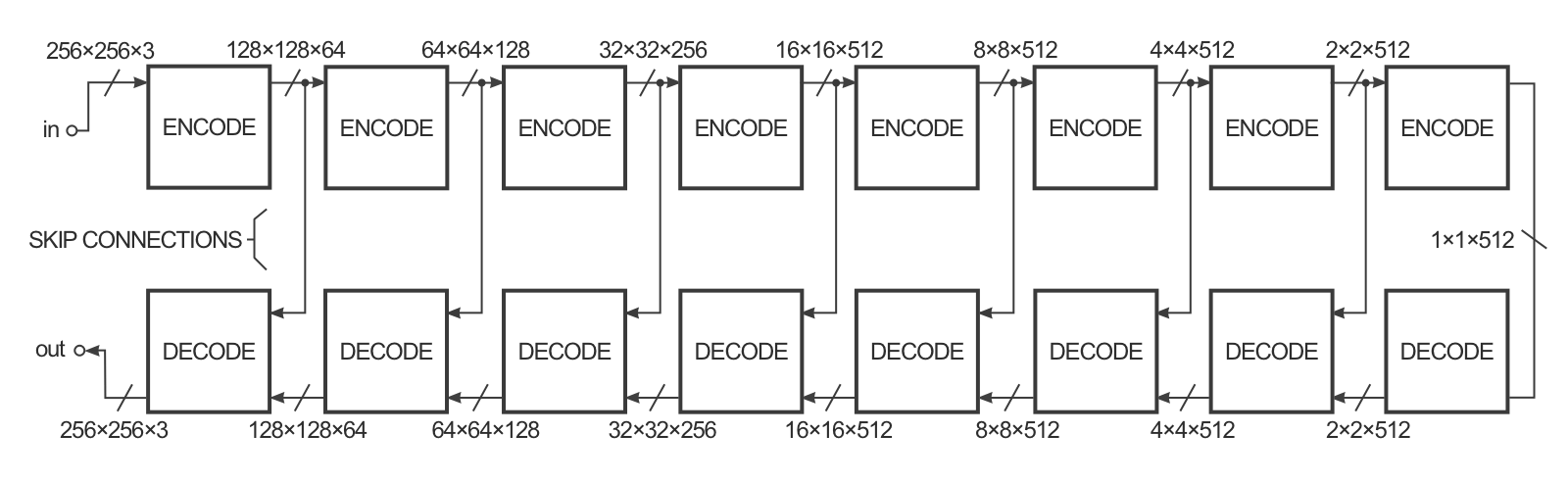
Fig. 8.14 pix2pix generator with skip connections. Source: https://affinelayer.com/pix2pix/.¶
The discriminator takes a pair of images as input: input/target or input/generated. It does not output a single value real/fake, but a 30x30 “image” telling how real or fake is the corresponding patch of the unknown image. Patches correspond to overlapping 70x70 regions of the 256x256 input image. This type of discriminator is called a PatchGAN.
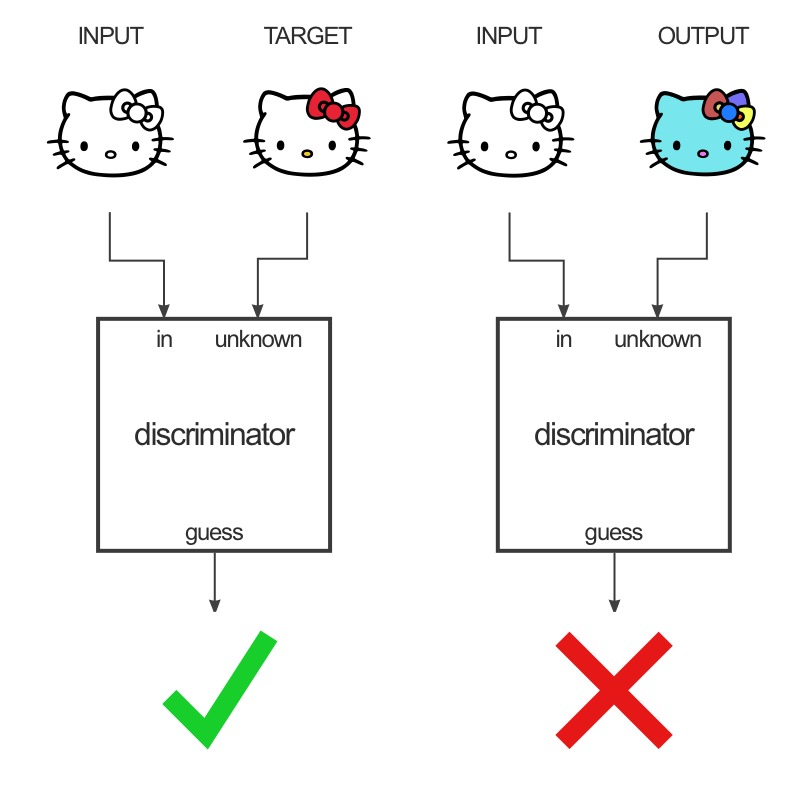
Fig. 8.15 pix2pix discriminator. Source: https://affinelayer.com/pix2pix/.¶

Fig. 8.16 pix2pix discriminator. Source: https://affinelayer.com/pix2pix/.¶
The discriminator is trained like in a regular GAN by alternating input/target or input/generated pairs.
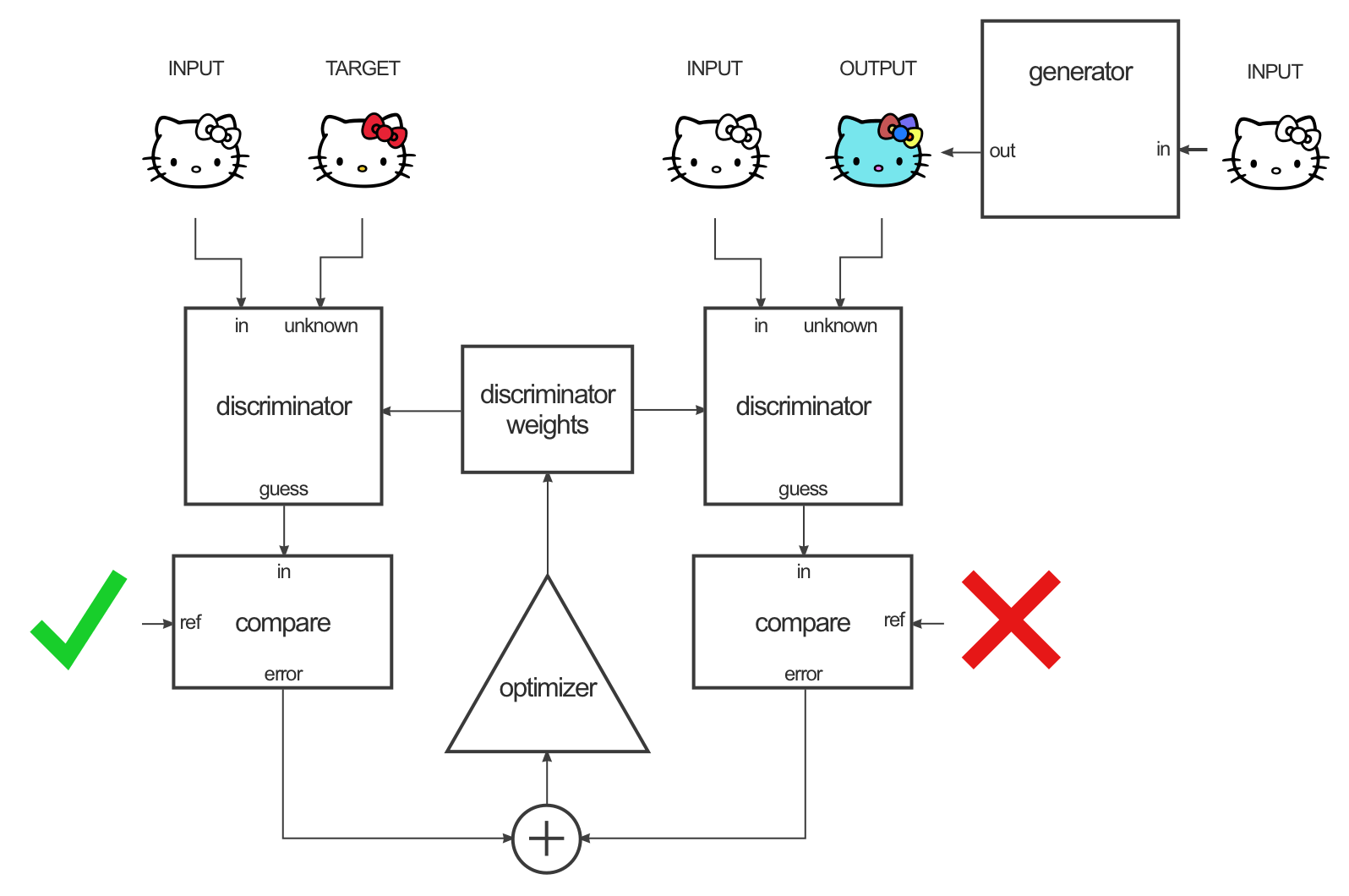
Fig. 8.17 pix2pix discriminator training. Source: https://affinelayer.com/pix2pix/.¶
The generator is trained by maximizing the GAN loss (using gradients backpropagated through the discriminator) but also by minimizing the L1 distance between the generated image and the target (supervised learning).
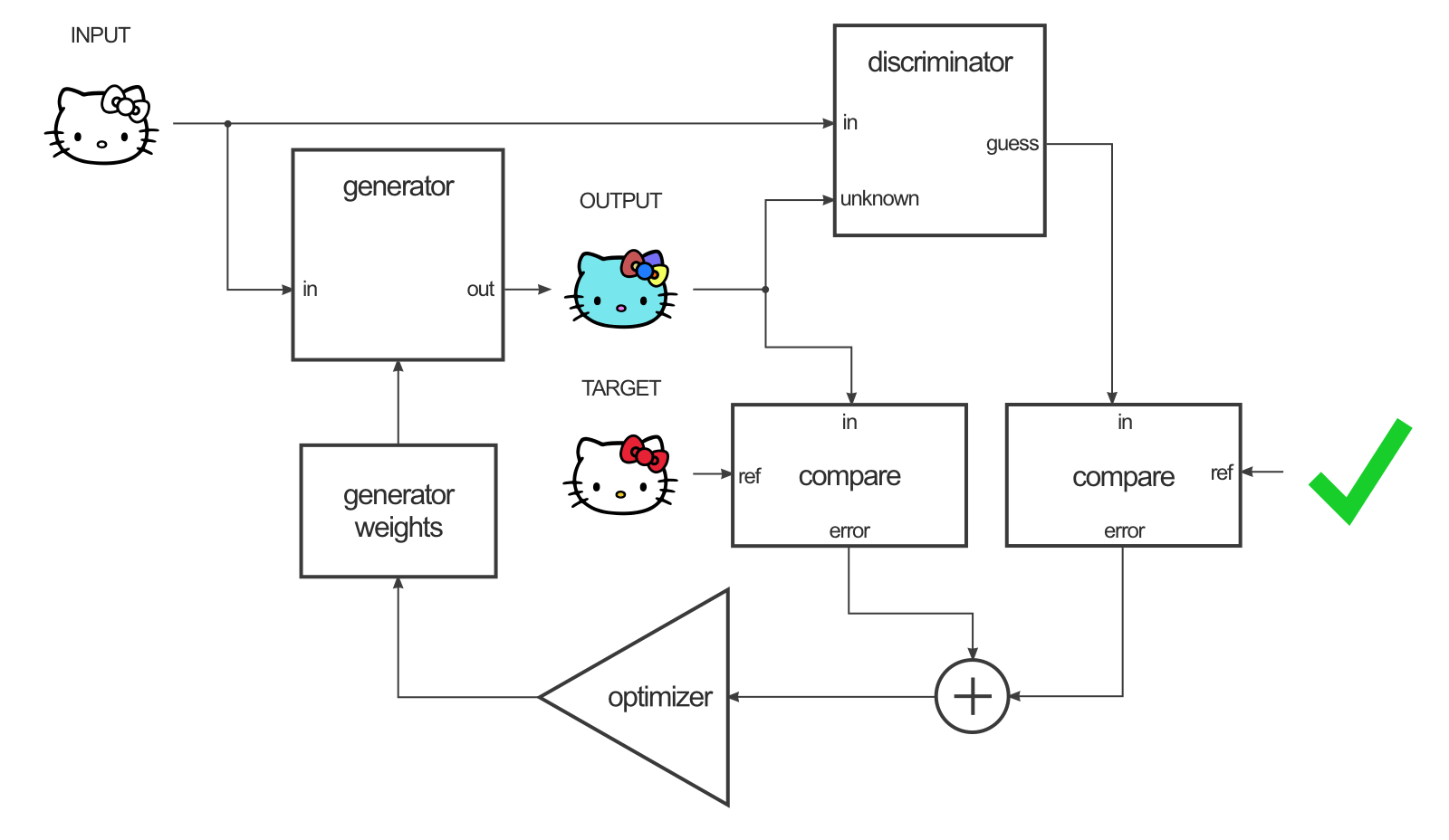
Fig. 8.18 pix2pix generator training. Source: https://affinelayer.com/pix2pix/.¶
8.2.3. CycleGAN : Neural Style Transfer¶
The drawback of pix2pix is that you need paired examples of each domain, which is sometimes difficult to obtain. In style transfer, we are interested in converting images using unpaired datasets, for example realistic photographies and paintings. CycleGAN [Zhu et al., 2020] is a GAN architecture for neural style transfer.
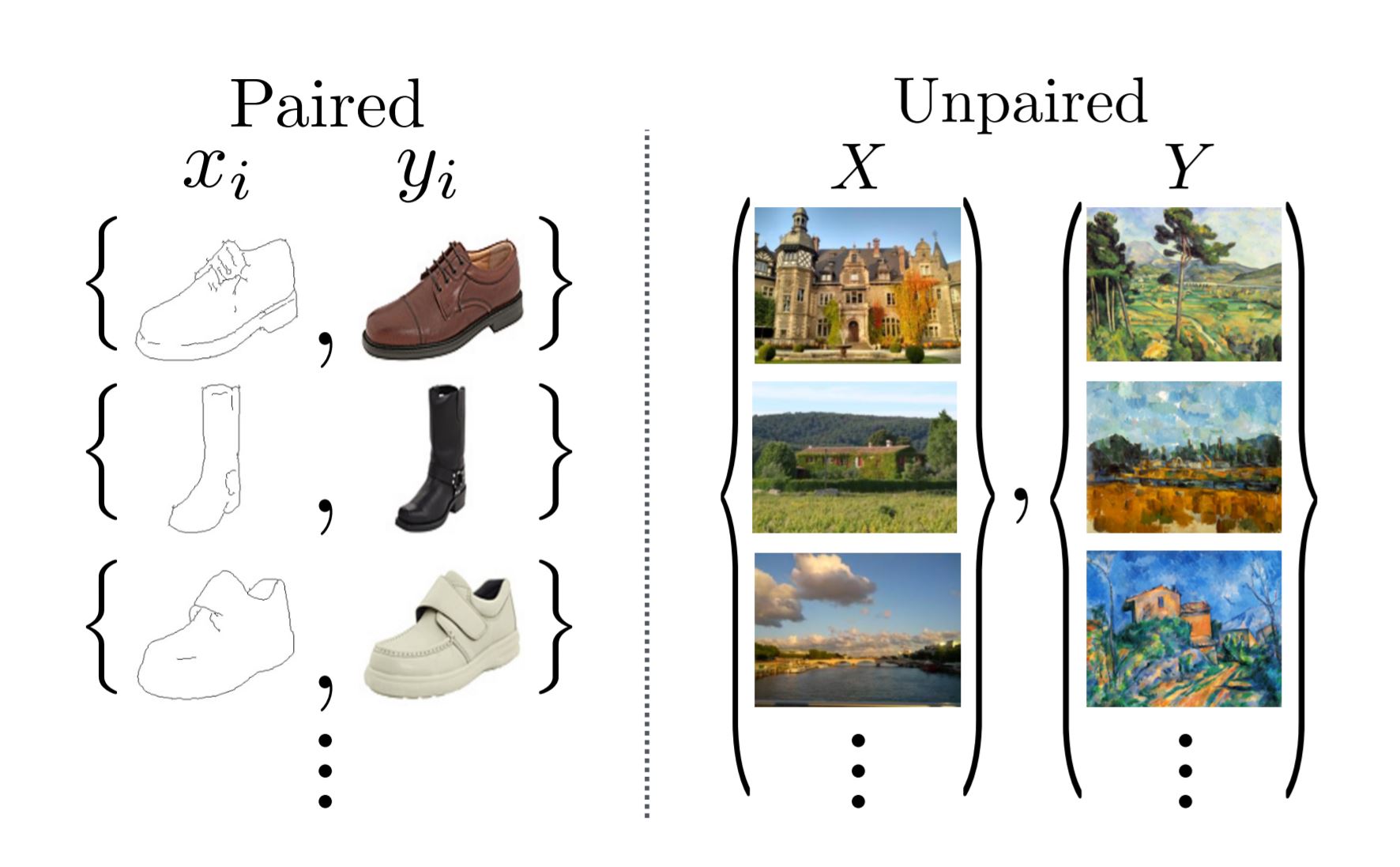
Fig. 8.19 Neural style transfer requires unpaired domains [Zhu et al., 2020].¶

Fig. 8.20 Neural style transfer. Source: https://hardikbansal.github.io/CycleGANBlog/¶
Let’s suppose that we want to transform domain A (horses) into domain B (zebras) or the other way around. The problem is that the two datasets are not paired, so we cannot provide targets to pix2pix (supervised learning). If we just select any zebra target for a horse input, pix2pix would learn to generate zebras that do not correspond to the input horse (the shape may be lost). How about we train a second GAN to generate the target?

Fig. 8.21 Neural style transfer between horses and zebras. Source: https://towardsdatascience.com/gender-swap-and-cyclegan-in-tensorflow-2-0-359fe74ab7ff¶
Cycle A2B2A
The A2B generator generates a sample of B from an image of A.
The B discriminator allows to train A2B using real images of B.
The B2A generator generates a sample of A from the output of A2B, which can be used to minimize the L1-reconstruction loss (shape-preserving).
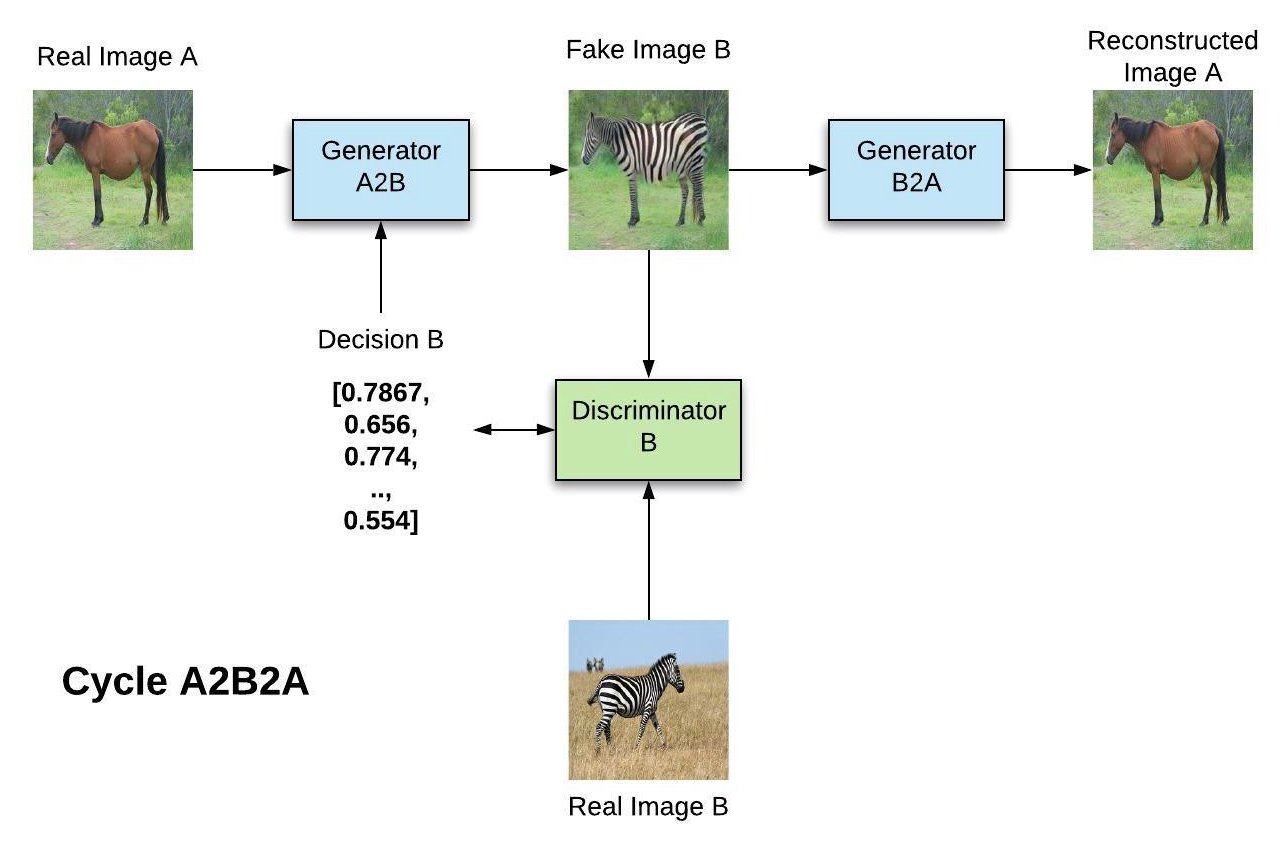
Fig. 8.22 Cycle A2B2A. Source: https://towardsdatascience.com/gender-swap-and-cyclegan-in-tensorflow-2-0-359fe74ab7ff¶
Cycle B2A2B
In the B2A2B cycle, the domains are reversed, what allows to train the A discriminator.
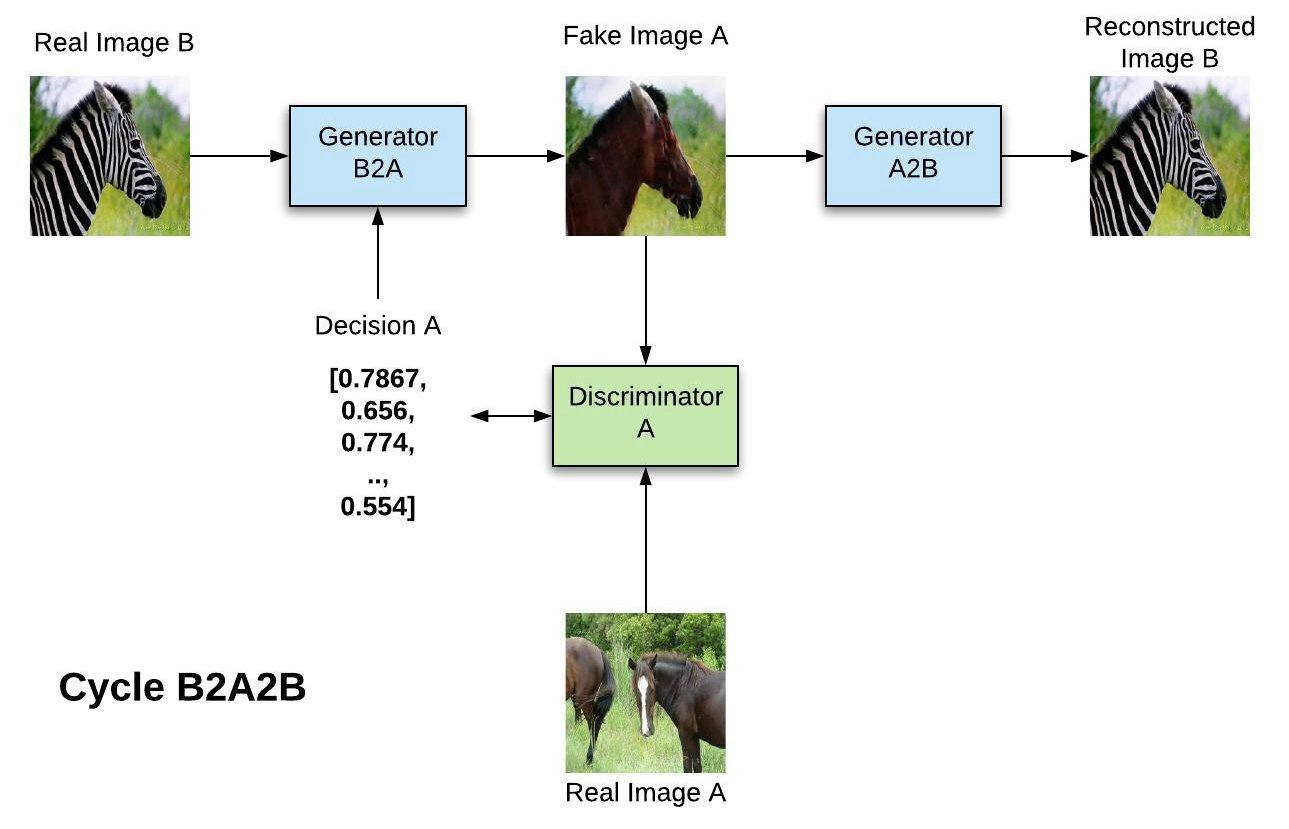
Fig. 8.23 Cycle B2A2B. Source: https://towardsdatascience.com/gender-swap-and-cyclegan-in-tensorflow-2-0-359fe74ab7ff¶
This cycle is repeated throughout training, allowing to train both GANS concurrently.

Fig. 8.24 CycleGAN. Source: https://github.com/junyanz/CycleGAN.¶

Fig. 8.25 CycleGAN. Source: https://github.com/junyanz/CycleGAN.¶

Fig. 8.26 CycleGAN. Source: https://github.com/junyanz/CycleGAN.¶