
4.2. Multiple linear regression¶
Let’s now investigate multiple linear regression (MLR), where several output depends on more than one input variable:
The Boston Housing Dataset consists of price of houses in various places in Boston. Alongside with price, the dataset also provide information such as the crime rate (CRIM), the proportion of non-retail business acres per town (INDUS), the proportion of owner-occupied units built prior to 1940 (AGE) and several other attributes. It is available here : https://archive.ics.uci.edu/ml/machine-learning-databases/housing.
The Boston dataset can be directly downloaded from scikit-learn:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
boston = load_boston()
X = boston.data
t = boston.target
print(X.shape)
print(t.shape)
(506, 13)
(506,)
There are 506 samples with 13 inputs and one output (the price). The following cell decribes what the features are:
print(boston.DESCR)
.. _boston_dataset:
Boston house prices dataset
---------------------------
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
This is a copy of UCI ML housing dataset.
https://archive.ics.uci.edu/ml/machine-learning-databases/housing/
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic
prices and the demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics
...', Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
.. topic:: References
- Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
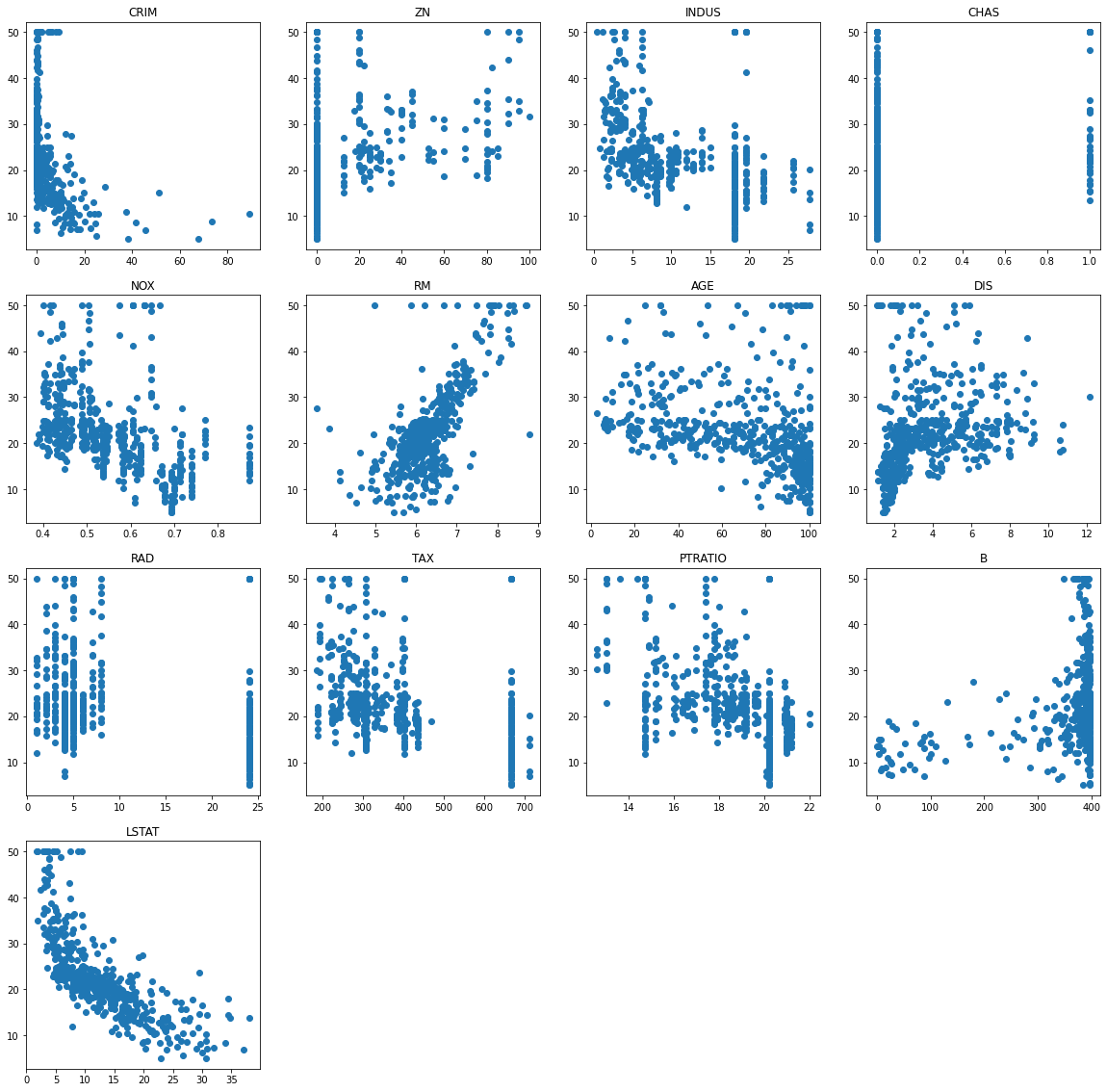
The following cell allows to visualize how each feature influences the price individually:
plt.figure(figsize=(20, 20))
for i in range(13):
plt.subplot(4, 4 , i+1)
plt.scatter(X[:, i], t)
plt.title(boston.feature_names[i])
plt.show()
4.2.1. Linear regression¶
Q: Apply MLR on the Boston data using the same LinearRegression method of scikit-learn as last time. Print the mse and visualize the prediction \(y\) against the true value \(t\) for each sample as before. Does it work?
You will also plot the weights of the model (reg.coef_) and conclude on the relative importance of the different features: which feature has the stronger weight and why?
from sklearn.linear_model import LinearRegression
# Linear regression
reg = LinearRegression()
reg.fit(X, t)
# Prediction
y = reg.predict(X)
# mse
mse = np.mean((t - y)**2)
print("MSE:", mse)
plt.figure(figsize=(12, 5))
plt.scatter(t, y)
plt.plot([t.min(), t.max()], [t.min(), t.max()])
plt.xlabel("t")
plt.ylabel("y")
plt.figure(figsize=(12, 5))
plt.plot(reg.coef_)
plt.xlabel("Feature")
plt.ylabel("Weight")
plt.show()
MSE: 21.894831181729202
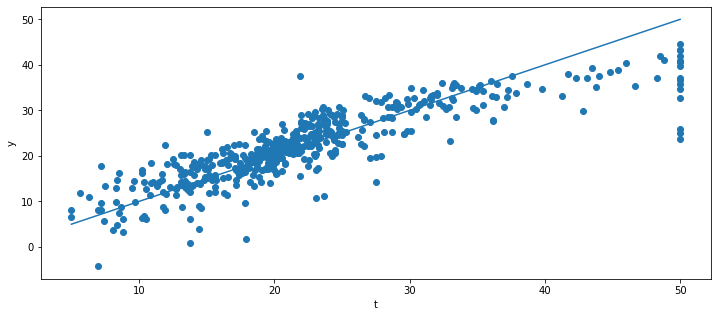
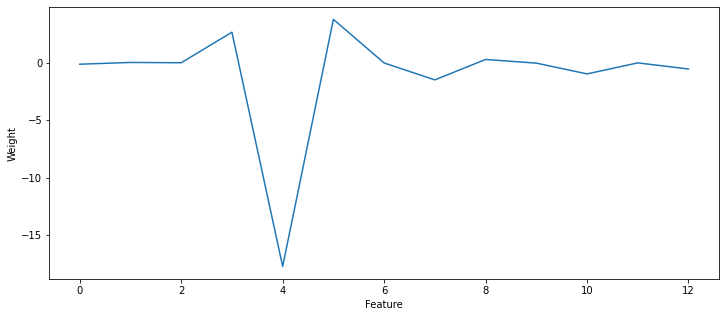
A: Feature 4 (NOX) got a very strong weight, although it is not a good predictor of the price. The main reason is that the features are not normalized: NOX varies between 0.0 an 1.0, while B varies between 0 and 400. The weight on B (Feature 11) does not need to be very high to influence the price prediction.
A good practice in machine learning is to normalize the inputs, i.e. to make sure that the samples have a mean of 0 and a standard deviation of 1. scikit-learn provides a method named scale that does it automatically:
from sklearn.preprocessing import scale
X_scaled = scale(X)
Q: Apply MLR again on X_scaled, print the mse and visualize the weights. What has changed?
# Linear regression
reg = LinearRegression()
reg.fit(X_scaled, t)
# Prediction
y = reg.predict(X_scaled)
# mse
mse = np.mean((t - y)**2)
print("mse:", mse)
plt.figure(figsize=(12, 5))
plt.scatter(t, y)
plt.plot([t.min(), t.max()], [t.min(), t.max()])
plt.xlabel("t")
plt.ylabel("y")
plt.figure(figsize=(12, 5))
plt.plot(reg.coef_)
plt.xlabel("Feature")
plt.ylabel("Weight")
plt.show()
mse: 21.894831181729202
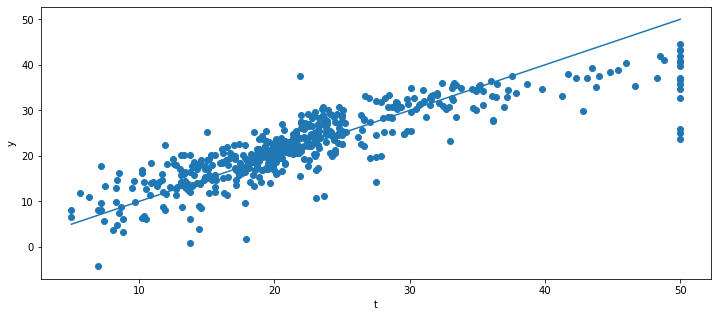
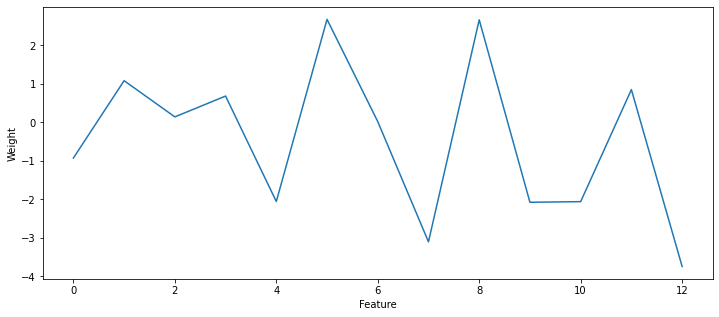
A: the mse does not change (it may in more complex problems), but the weights are more interpretable. Now strong weights in absolute value mean that the features are very predictive of the price.
4.2.2. Regularized regression¶
Now is time to investigate regularization:
MLR with L2 regularization is called Ridge regression
MLR with L1 regularization is called Lasso regression
Fortunately, scikit-learn provides these methods with a similar interface to LinearRegression. The Ridge and Lasso objects take an additional argument alpha which represents the regularization parameter:
reg = Ridge(alpha=0.1)
reg = Lasso(alpha=0.1)
from sklearn.linear_model import Ridge, Lasso
Q: Apply Ridge and Lasso regression on the scaled data, vary the regularization parameter to understand its function and comment on the results. In particular, increase the regularization parameter for LASSO and identify the features which are the most predictive of the price. Does it make sense?
reg = Ridge(alpha=10.0)
reg.fit(X_scaled, t)
y = reg.predict(X_scaled)
mse = np.mean((t - y)**2)
print(mse)
print(reg.coef_)
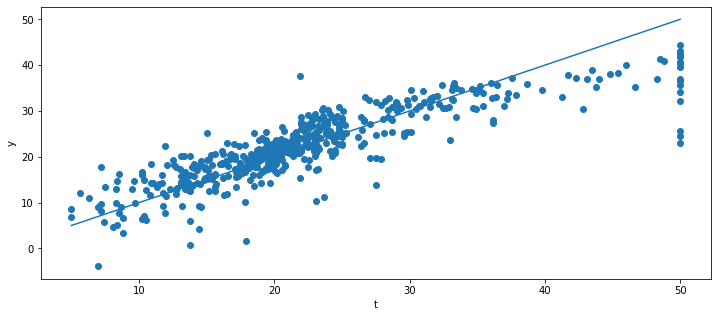
plt.figure(figsize=(12, 5))
plt.scatter(t, y)
plt.plot([t.min(), t.max()], [t.min(), t.max()])
plt.xlabel("t")
plt.ylabel("y")
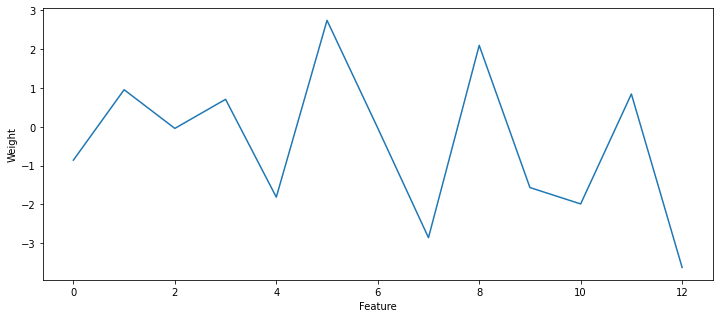
plt.figure(figsize=(12, 5))
plt.plot(reg.coef_)
plt.xlabel("Feature")
plt.ylabel("Weight")
plt.show()
21.967591187738435
[-0.85905074 0.95497477 -0.04132656 0.70777968 -1.81261091 2.74234394
-0.03238278 -2.85675627 2.0978234 -1.56539453 -1.98775121 0.84470905
-3.62394181]
reg = Lasso(alpha=1.0)
reg.fit(X_scaled, t)
y = reg.predict(X_scaled)
mse = np.mean((t - y)**2)
print(mse)
print(reg.coef_)
plt.figure(figsize=(12, 5))
plt.scatter(t, y)
plt.plot([t.min(), t.max()], [t.min(), t.max()])
plt.xlabel("t")
plt.ylabel("y")
plt.figure(figsize=(12, 5))
plt.plot(reg.coef_)
plt.xlabel("Feature")
plt.ylabel("Weight")
plt.show()
28.464652626660328
[-0. 0. -0. 0. -0. 2.7133553
-0. -0. -0. -0. -1.3435488 0.18095664
-3.54338107]
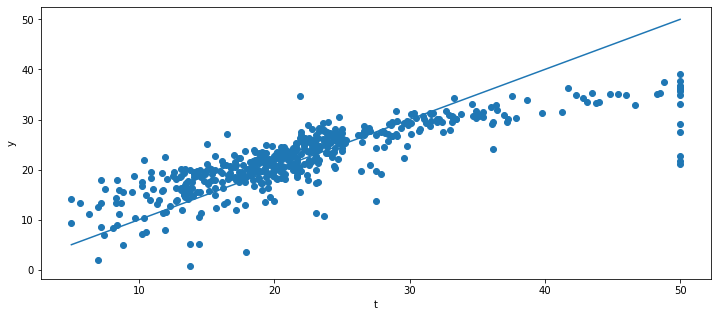
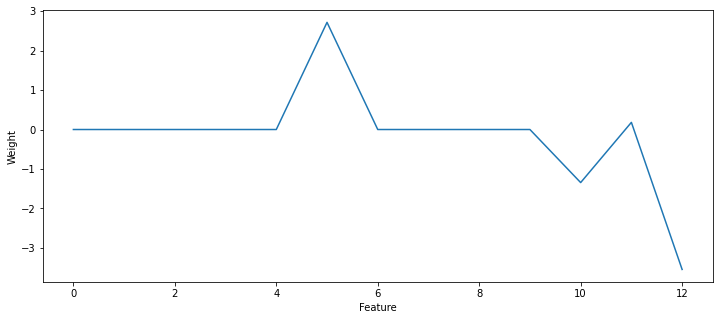
A: Ridge regression does not have a big effect for this data. By increasing the regularization parameter in Lasso regression, the MSE worsens slightly, but the number of non-zero weights becomes very small. With alpha=1.0, there are only 4 non-zero parameters: the corresponding features are the most predictive of the prices. You can identify them with:
print(boston.feature_names[reg.coef_ != 0.0])
['RM' 'PTRATIO' 'B' 'LSTAT']
RM average number of rooms per dwelling
PTRATIO pupil-teacher ratio by town
B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
LSTAT % lower status of the population
You are now a data scientist!